都在谈人工智能,但你知道它的潜力、实践意义、障碍是什么吗?
编者按:本文来自微信公众号“InfoQ”(ID:infoqchina),作者:NER,36氪经授权发布。
在过去的 250 多年里,技术创新一直是经济发展的根本推动力。这些技术创新中最重要的就是经济学家所说的“通用技术”,包括蒸汽机、电力,以及内燃机。它们中的每一个都催化了互补性创新与机遇的浪潮。举例来说,内燃机让汽车、卡车、飞机、链锯、割草机,甚至大型零售商、购物中心、交叉对接仓库、新供应链以及郊区得以出现。像沃尔玛、UPS 和 Uber 这样拥有多样性的公司找到了利用新技术创造新商业模式的方法。
我们这个时代最重要的通用技术就是人工智能,尤其是机器学习,也就是说机器能够持续提高自己的性能,而无须人类明确解释所有这些任务要怎样完成。在过去几年的时间里,机器学习已经变得越来越高效和广泛地使用。我们现在已经能建造出自己学习如何完成任务的系统了。
为什么这件事非常重要呢?有两个原因。第一,人类的知识比我们能表达出的更多,我们不能解释为什么人类能完成那么多的事情,从识别出一张人脸到在古老的亚洲策略游戏围棋中走出绝妙的一招。在机器学习之前,我们无法精确表达出我们的知识,这种无能正意味着我们不能自动化很多事情,而现在我们可以做到了。
第二,机器学习系统是非常出色的学习者。这些系统能在广泛的领域中达到超人类性能,包括检测欺诈和诊断疾病等。人们在整个经济领域中都部署了这样出色的数字学习者,它们的影响力将会十分深刻。
在商业领域,人工智能在早期通用技术的阶段就被认为拥有变革性的影响。虽然它目前已经被应用于全球上千家公司,但大多数重大的机遇并没有被利用开发出来。随着制造业、零售业、交通运输、金融业、医疗保健行业、法律、广告业、保险业、娱乐、教育业,以及事实上每一个其他领域转变其核心进程和商业模式,并从机器学习中受益,人工智能的影响,在即将到来的这个十年中一定会被放大。现在的瓶颈在于管理、执行,以及商业想象力。
然而,就像很多其他新技术一样,人工智能也催生出了一大批不切实际的期望。我们看到有大量商业计划随意挥洒在机器学习、神经网络,以及各种其他形式的技术方面,但却几乎与其真正的功能没有联系。举个例子来说,简单地把一个约会网站叫做“人工智能驱动的网站”,并不能让它变得更高效,但那或许有助于网站融资。这篇文章将穿过这些喧嚣的噪音,描述出人工智能的真正潜力、它的实践意义,以及它在被采用的过程中面临的障碍。
人工智能今天能够做些什么?
“人工智能”这个词是 1955 年由约翰·麦卡锡(John McCarthy)创造的,麦卡锡是达特茅斯学院的一位数学教授,他组织了之后一年那场具有开创意义的人工智能大会。从那以后,也许部分原因是因其令人回味的名称,人工智能这个领域开始崛起,而不仅仅停留在梦幻般的主张和承诺上了。在 1957 年,经济学家赫伯特·西蒙(Herbert Simon)预测,十年之内,计算机将在国际象棋方面打败人类。(事实上,计算机只花了 40 年时间。)在 1967 年,认知科学家马文·明斯基(Marvin Minsky)说:“在一代人之内,创造‘人工智能’这个问题将会得到实质解决。”西蒙和明斯基二人都是知识分子中的巨擘,但他们都错了。所以,对未来突破的戏剧性主张遭到了一定程度的怀疑。
我们先来看看,人工智能现在在做些什么,以及它在以多快的速度发展。最大的两个进步发生在这样两个广阔的领域:感知和认知。在早期的分类中,最有实用性的进步都是跟语音有关的。语音识别还差强人意,但现在有百万计的人们在使用它,想想 Siri、Alexa,以及 Google 的语音助手。你现在在读的这篇文章,最开始是我口述给一台计算机并让它以足够的精确度转写出来的,这样比打字要快。由斯坦福计算机科学家詹姆斯·兰迪(James Landay)和他的同事们进行的一项研究发现,平均来说,语音识别比在手机上打字要快三倍,其错误率已经由曾经的 8.5%降低到了 4.9%。令人震惊的是,这个显著的改进并不是经过 10 多年时间才实现的,而仅仅是从 2016 年夏天才开始。
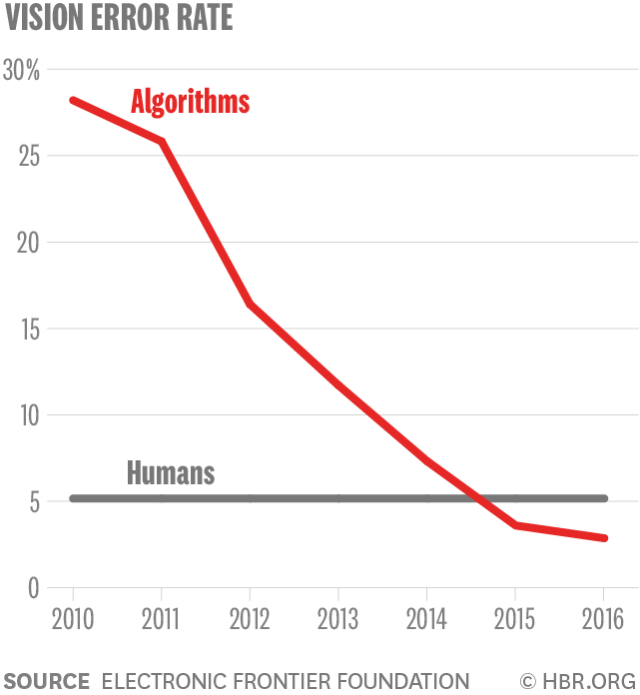
同样地,图像识别也进步得非常惊人。你可能已经注意到,Facebook 和其他应用程序现在可以在发出的图片中识别出你很多朋友的脸,并且提示你给他们贴标签。一个在你智能手机上的应用就能识别出野外的任何一只鸟。在一些公司总部,图片识别甚至正在取代身份证件。视觉系统,比如那些用在自动驾驶汽车上的视觉系统,以前在识别行人方面每 30 帧中就会出现一次错误,而现在它们的错误率比在 3000 万帧中出错一次还要低。图片识别有一个巨大的数据库,叫 ImageNet,它拥有几百万常见的、模糊的或完全怪异的照片,顶级系统的图片识别错误率已经从 2010 年的 30%多,降低到了 2016 年的 4%。
最近几年来,由于采用了基于庞大的或“深度的”神经网络的新方法,图片识别的改进速度迅速加快。视觉系统的机器学习还远非完美,但即使是人类,也可能会在快速识别出一只小狗方面有困难,人们也可能会在根本没有可爱小狗的地方看出小狗来。
小狗还是玛芬蛋糕?图像识别的进步
机器已经在识别相似图像的类别方面取得了长足的进步。

图片识别的错误率
第二个主要改进的方面是认知和问题解决。机器已经战胜了最棒的人类扑克选手和围棋选手,这是一项专家们之前预测需要至少又一个十年的时间才能实现的成就。Google 的 DeepMind 团队用机器学习系统提高冷却数据中心的效率,高达 15 个百分点,即使人类专家已经优化过数据中心,它也还是达到了这个水平。网络安全公司 Deep Instinct 正在使用智能代理来检测恶意软件,PayPal 用智能代理防止洗钱行为。使用 IBM 技术的一家新加坡保险公司支持用户自动进行索赔流程,而数据科学平台 Lumidatum 能提供实时建议来改进客户支持系统。
一大批公司在使用机器学习来决定接受华尔街的哪一笔买卖,有越来越多的信用决策都在机器学习的帮助下做出。亚马逊采用机器学习优化库存并改善他们向用户推送的产品推荐。Infinite Analytics 开发了一个机器学习系统,来预测用户是否会点击一个特定的广告,改善全球消费品商品公司的在线广告布局,另一个系统则是为了优化用户在一个巴西网络零售商的搜索和发现过程。第一个系统将广告投资回报率提高了三倍,第二个系统则增加了 1.25 亿美元的年收入。
机器学习系统不仅在很多应用里代替着原始的算法,而且在很多人类曾经表现最好的工作任务中更为出色。虽然这个系统还有待改进,它们在 ImageNet 数据库的错误率(大约是 5%)已经达到或比人类水平的表现更好了。语音识别也是这样,即使在嘈杂的环境下,现在也几乎和人类水平持平。机器学习系统达到了这样的门槛,进而为改变工作场所和经济开辟出了新的广阔可能性。一旦以人工智能为基础的系统在某个领域超越了人类的表现,它们就更容易快速广泛传播。
举个例子,比如 Aptonomy 和 Sanbot,它们分别是无人机和机器人制造者,它们正在使用改进过的视觉系统,使很多安保工作自动化。在很多同类公司中,软件公司 Affectiva 正在使用机器学习在特定群体中识别快乐、惊讶和气愤等情绪。Enlitic 则是一家使用机器学习扫描医学图像进而帮助诊断癌症的深度学习创业公司,而这样的公司已经有好几家了。
这些都是了不起的成就,但以人工智能为基础的系统,其适用性依然非常狭窄。举个例子,机器学习在拥有数百万图片的 ImageNet 数据库中的出色表现,并不意味着它总能“在野外环境中”取得一样的成功,在野外环境中,光线条件、角度、图片分辨率以及情境都可能非常不同。更为根本地,我们可能会惊叹于一个系统能理解中国话并把它翻译成英文,但我们不能指望这个系统理解一个特定中文字的意义,更不用说在北京去哪里吃饭好了。
如果一个人能出色地完成一项任务,那很自然也可以假设他有能力完成一些相关的工作。但是机器学习系统就是为了某些特定任务而训练出来的,它一贯的知识并不会扩展延伸。一个典型的谬论就是认为计算机狭窄的理解力意味着它能扩展到更广阔的理解力中,这可能是一个最大的混淆之源,更为夸张的宣称就是认为人工智能能够自己取得进步。我们离具备在多领域中拥有通用智能的机器还非常遥远。
理解机器学习
要理解机器学习,最重要的一点就是明白机器学习代表了一条创造软件的完全不同的道路。举个例子,机器是去学习一件事情,而不是为某一明确结果被明确编程成什么样子。在过去 50 年的绝大多数时间里,信息技术领域的进步及其应用都聚焦于把某种已有的知识和程序编成指令,再把这些指令植入机器中。确实,“编程”这个词总是意味着这样一种艰苦的过程,即开发者把自己头脑中的知识转化成一种机器能理解和执行的格式。这种方法有一个根本上的弱点:我们现有的很多知识都是大家心照不宣的,也就是说我们无法完全解释它们。对我们来说,写下每一条指令让另一个人明白如何骑自行车、如何识别出一个朋友的脸庞,这几乎是不可能的。

上图:这就是使用人工智能的意义。结果是人又不是人,可识别但又不是你期望中的那样,它们美丽吗,可怕吗,能让人感到愉悦吗?
换句话说,我们所知的比我们能表达的更多。机器学习正在克服这个困难。在第二次机器革命的这第二波浪潮中,人类制造的机器正在从实例中学习,并且使用结构清晰的反馈来解决自己的问题,比如面部识别。
机器学习的不同特色
人工智能和机器学习有很多种特色,但近年来大多数成功的案例都集中在监督学习方面,也就是关于某特定问题,赋予机器大量正确的实例学习。这个过程几乎总涉及从一组输入 X,到一组输出 Y 的映射。比如,输入可能是一些各种动物的图片,正确的输出就是关于这些动物的标签:猫、狗、马等。输入也可以是一段音频的声音波形,正确的输出就是一些词汇:是、否、你好、再见等。
成功的系统通常使用几千个甚至几百万个实例的训练数据集,每个实例都已经被标记出正确的答案,系统会再大体看一下新的实例,如果训练顺利,系统就会以高度的精确度来预测答案。
算法的成功多半要依仗一种叫“深度学习”的方式,而深度学习利用的是神经网络。和早期机器学习算法相比,深度学习算法有一个重要的优点:深度学习能够更好地使用大得多的数据库。旧的系统会随着训练数据实例的增加而改进,但会到达一个点,在那个点之后再增加数据并不能带来更好的预测。这个领域的领军人之一吴恩达说:“深度神经网络就不会在这种方式下失效,更多的数据的确会带来更好的预测。”一些非常大的系统是由 3600 万或更多实例训练出来的。当然,要使用极大的数据库就需要更加强大的处理能力,这就是为什么非常大的系统通常在超级计算机或专用计算机上运行。
如果你有很多有关行为的数据并试图预测结果,这就是监督学习系统的潜在应用机会。亚马逊的全球消费者部门的 CEO 杰夫·威尔克(Jeff Wilke)说:“监督学习系统已经在很大程度上取代了用于向客户提供个性化建议的基于内存的过滤算法。”摩根大通则引入了一个系统来检查商业贷款合同,这项工作以前需要负责贷款的员工用 360000 个小时来完成,而现在只需要几秒钟了。监督学习系统还被用于诊断皮肤癌。上面所说的只是部分例子而已。
相对来说,标记一组数据并把它用于训练监督学习系统是比较简单直接的。这也是为什么监督学习式机器学习系统比无监督学习系统更为常见,至少目前是如此。无监督学习系统想要自己学习。我们人类就是出色的无监督学习者,我们用很少的没有标签的数据就能从这个世界上获取大部分知识,比如识别出一棵树,但是开发出一个如此运行的成功的机器学习系统就极端困难。
如果我们能建立强大的无监督学习系统,就将开启令人振奋的新的可能性。这些机器将能够用全新的方法审视复杂的问题,帮我们找出其中的模式,可用于观察疾病传播、市场证券价格走势、客户的购买行为等等。正是这种可能性引领着 Facebook 的 AI 研究主管、纽约大学教授 Yann LeCun,他把监督学习系统比作在蛋糕上撒糖霜,而把无监督学习比作蛋糕本身。
在这个领域里,另一个渺小但是在成长中的领域就是强化学习。它已经被嵌入了雅达利电子游戏和围棋这样的棋盘游戏中。它还能帮助优化数据中心的电力使用,甚至为股票制定交易策略。Kindred 公司制造的机器人能用机器学习来辨识和归类它们从没遇到过的物体,还能加快消费品配送中心的运送速度。在强化学习系统中,编程人员会具体说明系统的现状和目标,列出可被允许的行为,描述会影响和限制行为结果的环境因素。在可被允许的行为下,系统要找出尽可能接近目标的方法。人类可以具体说明目标而不需要说明如何做到,在这种情况下系统运行得最好。
比如,微软利用强化学习来为 MSN 网站的新闻报道选标题,方法就是在点开链接的用户更多的时候,给系统打更高的分数作为奖励。系统会尝试着在编程人员给定规则的基础上最大化它的分数。当然,这就意味着强化学习系统会针对你明确奖励的目标进行自身优化,而不一定针对你真正关心的目标来优化,因此,准确而清晰地指定目标至关重要。

上图:今天的人工智能应用都是由人类来驱动的,医生尝试着去解决一个癌症患者的病痛,家庭厨师在寻找新的菜谱,通勤上班族决定着如何开车出门。
把机器学习带入工作中
对那些期望把机器学习付诸实践的组织来说,现在有三个好消息。第一,人工智能在广泛地传播。这个世界上还远没有足够的数据科学家和机器学习专家,但在线教育资源和大学院校正在努力迎合这种需求。其中最好的资源包括 Udacity、Coursera 和 fast.ai,他们不仅教授概念性的东西,而且能真正让学生们去实现工业级别的机器学习部署。除了培养自己的员工之外,感兴趣的公司还可以利用 Upwork、Topcoder 和 Kaggle 这样的在线人才平台寻找具备专业知识的机器学习专家。
第二,对现代人工智能来说十分必要的算法和硬件已经可以被买到或租赁到。Google、亚马逊、微软和 Salesforce 等公司都在建构强大的机器学习基础设施,并且都可以通过云系统得到。在这些竞争对手之间存在激烈的竞争,这就意味着,随着时间推移,那些想要尝试和部署机器学习的公司将看到越来越多可获得的平价功能。
第三,也许你并不需要那么大量的数据才能开始利用机器学习。大多数机器学习系统的表现都会随着它们得到更多数据而提升,所以,似乎拥有最多数据的公司将会取得胜利。在这种情况下,“胜利”意味着“控制某一单一应用,比如广告定位或者语音识别的全球市场”。但如果胜利的定义被转变为“显著提高性能”,那么其实充足的数据是非常容易获得的。
机器学习正在三个层面推动变革:任务和职业、商业进程、商业模式。用机器视觉系统识别出潜在的癌细胞就是第一个层面变革的极好例证,它把放射学家解放出来,让他们能够专注于真正重要的事情,能够更好地和病人沟通,和其他医生协作。对商业进程的变革也有一个例子,就是亚马逊引入了机器人,并使用以机器学习为基础的优化算法,重新发明了工作流程,重新布局了亚马逊的各个履职中心。同样地,商业模式也需要利用机器学习系统来重新思考,这些系统可以智能地定制化地推荐音乐、电影等。更好的模式不是以消费者选择为基础销售单曲,而是提供一种预订和播放特定用户可能会喜欢的音乐这样一种个性化订阅服务,即使这个用户可能根本没听说这些音乐。
风险和极限
第二次机器革命的第二波浪潮也带来了新的风险。尤其是,机器学习系统是“难以解释的”,也就是说我们人类很难理解系统是如何作出决定的。深度神经网络可能拥有数亿个连接,每一个连接都为最终的决策贡献了一点力量。结果就是这些系统的预测是无法简单明晰地被解释出来的,机器知道的比它们能告诉我们的更多。
这就带来了三个方面的风险。第一,机器可能会有隐藏的偏见,这些偏见不是来自机器设计者的意图,而是来自训练它们的数据。比如,如果一个系统利用人类数据库的决策学习可以接受面试中的哪些工作申请,它可能会不经意间评估应聘者的种族、性别、民族等。更进一步,它们的偏见可能不会表现成明确的规则,而是嵌入在上千种考虑因素的细微互动之中。
第二,与建立在明确逻辑规则上的传统系统不同,神经网络系统处理的是数据事实,而不是绝对的事实。可能很难证明这个系统是完全确定可以在任何情况下正常工作,尤其是在训练数据时没有涉及到的情况下。缺乏确定性可能是在处理关键任务时的一个问题,比如控制核电厂,或者涉及生死攸关的决定。
第三,当机器学习系统犯错的时候(犯错几乎不可避免),诊断和纠正错误都极端困难。得出解决方案的基础结构可能是我们难以想象地复杂的,如果系统的训练条件改变了,得出的解决方案可能远非最优。
这些风险都非常真实,合适的基准不是追求完美,而是追求最优的可选项。毕竟我们人类也会有偏见、犯错误,还觉得诚实解释我们做出决定的过程很困难。以机器为基础的系统,其优点在于它可以随着时间推移而改进,而且你给它什么样的数据它都会得出一致的回答。
这是否意味着人工智能和机器学习能做的事情就没有极限呢?感知和认知覆盖了绝大部分的领域,从开汽车到预测销售,甚至还能决定雇佣什么人、提拔什么人。我们相信,在绝大多数领域,人工智能很快就会超越人类水平的表现。那么,人工智能和机器学习不能做什么呢?
我们有时会听到这样的说法:人工智能永远无法估计评估我们这些情绪化的、灵巧的、狡猾的人类,它太呆板太非人化了。我们不同意这样的说法。在通过声音语气、面部表情来识别一个人的情绪状态方面,机器学习系统已经处于或者已经超越了人类水平的表现。有些系统甚至能识别世界最顶级的扑克选手是否在虚张声势。这是一个非常精细的工作,但它不是魔法。它需要知觉和认知,这正是机器学习现在正变得越来越强大的地方。
讨论人工智能的极限,最好从毕加索开始,毕加索通过对计算机的观察得出结论:“它们没有用,它们只能给你答案罢了。”事实上,计算机当然不是没有用,但是毕加索的观察依然提供了某些洞见。计算机是用来回答问题的设备,而不是提出问题的设备。那就意味着,企业家、创新者、科学家、创造者和其他那些寻找下一个问题与机会的人,那些探索新领域的人,他们依然至关重要。
我们认为,在这个超级强大的机器学习时代,对人类智慧来说,最大最重要的机遇在于两个领域的交叉:弄清楚下一步要解决什么问题,说服很多人解决这个问题,一起去寻求解决方案。这也是对“领导力”的一种合适的定义,而领导力已经在第二机器时代变得越来越重要了。
我们认为,人工智能,尤其是机器学习,这些是我们这个时代最重要的通用技术。这些创新对企业和经济的影响不仅仅体现在它们的直接贡献中,而且还体现在它们启发互补创新的能力方面。通过更好的视觉系统、语音识别、智能解决问题系统,以及由机器学习所提供的很多其他功能,新的产品和流程正在成为现实。
虽然预测具体地哪个公司会在新环境中居于统治地位很难,但一个通用的原则很明晰,那就是:最为灵活的、有适应能力的公司和经营管理者会走向繁荣。能迅速感知到机遇,并对此有所反应的组织,终将会在人工智能这片热土上占据优势。所以成功的策略就是,乐于快速实验并学习。如果管理者们没有在机器学习领域开展实验,那么他们就没有做好自己的工作。在未来的十年时间里,人工智能并不会取代管理者,但是,那些善用人工智能的管理者将会取代那些没有这样做的人。

上图:仔细凝视,你将会看到算法中的人类;更仔细地凝视一会儿,你将会看到智能中的算法。


图像影音设计相关的软件
凡科快图
- 4.5
(95)咨询产品免费试用墨刀
- 3.9
(423)咨询产品免费试用Pixso
- 3.9
(22)咨询产品免费试用



行业专家共同推荐的软件
蓝湖
- 4.0
(584)咨询产品免费试用Canva可画
- 4.0
(206)咨询产品免费试用字魂
- 4.5
(20)咨询产品免费试用



限时免费的图像影音设计软件
Dprox创意3D视频
- 5.0
(1)咨询产品免费试用万兴喵影
- 3.9
(31)咨询产品免费试用易企秀
- 3.8
(260)咨询产品免费试用



新锐产品推荐
星立方-教学数据分析系统
- 0.0
(0)咨询产品免费试用佳发教育-教考统筹整体解决方案
- 0.0
(0)咨询产品免费试用佳发教育-智慧校园整体解决方案
- 0.0
(0)咨询产品免费试用城市大脑智能运营指挥中心(IOCC)
- 0.0
(0)咨询产品免费试用WooCommerce
- 0.0
(0)咨询产品免费试用Shopify Plus
- 4.0
(40)咨询产品免费试用







