新生代农民工正在“声”援AI未来——14万人录制最全的中文数据集

图片来源:摄图网
近期,人社部定义的“新生代农民工”一词火了,它是指就业于劳动密集型行业,从事信息传输、软件和信息技术服务业的群体。如果互联网、电商这些行业无法直观感受什么是“劳动密集型”,了解一下人工智能行业就会明白。
在监督学习为主流的当下,人工智能算法、数据和算力三驾马车中,数据是关键点,大量的数据需要大量的人工进行采集、标注、清洗和处理,数据处理的量级直接关系到机器的智能程度。
人社部预计到2022年,数据标注相关从业人员有望达到500万人的规模,所以人工智能行业有句流传很广的话:有多少智能,就有多少人工。
超9万小时中文数据集
当前智能设备市场产品众多,人和机器进行语音交互、命令控制、人机对话等动作大都是通过中文来完成,所以语音相关的智能设备都离不开中文数据的支撑。
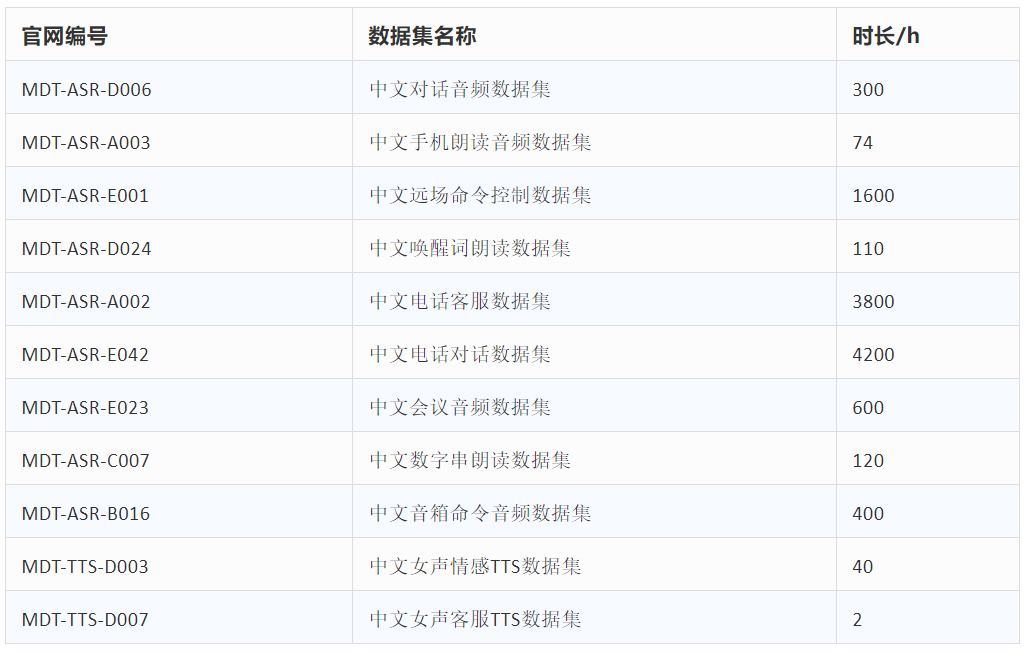
北京爱数智慧作为一家全球领跑多模态数据服务提供商,拥有大量的中文语音数据,根据出行、社交、金融、家居和终端等不同行业的应用场景录制的朗读、对话、自发式等类型数据,中文类数据总量超过90000小时,来自全国各地超过14万人先后参与录制。一个智能设备越智能,背后的数据量级就越大,这些数据让决定了智能化体验水平。
爱数智慧部分中文数据集
对话式中文数据—破解口语交互难点
对于AI开发者来说,搭建从0到1的智能模型,解决语音识别问题首先会使用朗读语音数据,要想提升模型在真实环境下的识别率,就需要贴近真实场景的自发式对话风格的数据。
朗读式数据一般依照文本进行朗读,书面化而不贴近生活,但是现实中人际交流,会出现打断/抢话、语序颠倒、交叠音和犹豫迟疑等现象。

比如部分北方地区人常说“知不道”,其实是“不知道”的倒装。“你去过香港吗?”温州人却说:“你香港走过罢也未?”包括我们边思考边表达的“嗯”、“啊”等,AI遇到这种情况很容易变成“人工智障”,不知所措。
AI真正理解人对话中的口语、语序颠倒问题,朗读数据外还需要大量对话式AI训练数据,数据录制自两人或多人自由对话,还原真实对话场景,帮助AI识别复杂对话场景下的声音。
中文对话数据集介绍
数据集根据多组主题自由对话,还原电话对话真实场景,话题涵盖职业、日常生活、娱乐等常见场景。该数据集总时长超过6000小时,由超过20000人参与录制。数据可用于智能社交、智慧金融、智能家居等行业智能推荐、智能电销、智能质检、智能客服等场景。
中英混合数据—提升多语言识别性能

图片来源:摄图网
“程序自动执行命令为何不Work了?”
“麻烦把WiFi打开,谢谢!”
早在20世纪初,上海流行过“洋泾浜语”,就是交流中夹杂外语的情况。如今文化进一步融合,类似上面中文夹杂英语现象开始普遍化和日常化。AI产品如何提高“播放Taylor Swift的love story”这样中英混合对话的识别率?
北京爱数智慧从声学建模角度,通过混合发音字典建模和混合双语声学建模来提升多语言混合识别率。通过发音词典构建统一音素集,将各语种的音素映射到该音素集,同时模型使用中文和英文语音数据外,需要使用中式英文语音数据、中英混合语音数据进行音素聚类和模型训练。
中国人说英语数据集介绍
该数据由600多人参与录制,用中式英语朗读日常用语,录制人覆盖青少年、中年等各个年龄段。数据可用于智能家居、智能社交等行业,用于智能音箱、智能客服等场景的AI模型训练。
中英混合朗读音频数据集介绍
数据集近5000人在安静室内录制,时长超过2100小时,音频内容丰富,涵盖带有中英混合的日常用语、人机交互、控制命令等。数据可应用于智能家居、智慧金融、智能社交等行业的智能音箱、智能客服等场景。
中文音频数据典型应用场景
每个领域的对话式AI都离不开大量的中文数据,如果数据是人工智能“原油”的话,那么中文数据便是被使用最多的“汽油”。
车载/导航场景
在车载场景下,AI识别率会受到各种噪音如车胎摩擦音、说话声、外边的风声、汽笛声等等复杂环境影响,模型需要真实车载场景的录音数据。北京爱数智慧专为车载场景开发中文数据,解决车载识别率问题。

图片来源:摄图网
中文车载朗读数据介绍
数据集由1100人参与录制,总时长超过640小时,在车载环境下录制,录制内容为人机交互、命令控制,例如导航、搜索歌曲、天气预报等朗读语料。
车载噪音数据集介绍
该数据集在真实车载场景下录制的噪音场景,总时长近100小时,语音参数44.1 kHz/16 bits。该数据集有助于提升车载AI产品对噪音的识别率。
家居场景
家居场景在应对复杂噪音环境同时,还要解决远场问题。远场语音是指超过5米距离用语音命令控制家居设备,人可以享受摆脱遥控器和按开关的繁琐操作。北京爱数智慧专门针对家居环境开发远场带噪中文数据。

图片来源:摄图网
中文普通话远场带噪数据集
该数据集在在室内、室外、车载、公共场所等的远场环境下录制,内容为日常用语,近800人参与录制,总时长超过500小时。数据用于智能家居行业外,还可用于智慧出行、智能终端等行业的远场带噪场景的模型识别。
北京爱数智慧拥有海量、多维度的中文音频数据,数据类型多样,内容包括日常用语、命令控制、唤醒词、数字串、导航、客服对话、短语等,既能够满足多领域的模型训练需求,也能够解决噪音、远场等特殊场景的识别问题。
中文数据集外,北京爱数智慧还拥有海量的方言、外语类数据,目前北京爱数智慧拥有超过200000小时自有数据集,其中对话式数据超过120000小时,朗读式数据超过60000小时,自发式数据超过20000小时,为初步搭建AI模型或者模型迭代的客户提供高质量、多维度、合规性高的数据集,有效帮助客户实现更好的模型效果,提高投入产出比和有效地降本增效。


图像影音设计相关的软件
凡科快图
- 4.5
(95)咨询产品免费试用墨刀
- 3.9
(423)咨询产品免费试用Pixso
- 3.9
(22)咨询产品免费试用



行业专家共同推荐的软件
蓝湖
- 4.0
(584)咨询产品免费试用Canva可画
- 4.0
(207)咨询产品免费试用字魂
- 4.5
(20)咨询产品免费试用



限时免费的图像影音设计软件
Dprox创意3D视频
- 5.0
(1)咨询产品免费试用万兴喵影
- 3.9
(31)咨询产品免费试用易企秀
- 3.8
(260)咨询产品免费试用



新锐产品推荐
BML全功能AI开发平台
- 0.0
(0)咨询产品免费试用即时设计
- 3.6
(65)咨询产品免费试用mastergo
- 3.8
(21)咨询产品免费试用码前
- 3.9
(7)咨询产品免费试用联通沃云云服务器 ECS
- 0.0
(0)咨询产品免费试用中金智汇-智能质检
- 0.0
(0)咨询产品免费试用







