强化学习的入门之旅
编者按:本文来自微信公众号“将门创投”(ID:thejiangmen),编译:T.R;36氪经授权转载
深度强化学习可以用于在围棋中实现超人的表现,在atari游戏中成为高手,同时也可以控制复杂的机器人系统,自动调节深度学习系统、管理网络堆栈中的队列问题,此外还能改善数据中心的能耗效率…这几乎就是一个神通广大的技术啊!但是我们需要对这种铺天盖地的媒体宣传保持足够清醒的头脑。
作者希望在这篇文章中为读者呈现出强化学习的真实面貌,让我们明白什么是强化学习能做的而且能出色完成的,而哪些又仅仅是停留在纸面上的假设而已。同时作者还认为机器学习中的一些重要问题将可以通过强化学习的角度予以解决。
强化学习令人不解的原因主要在于它需要我们利用一种在通常机器学习中不常用的核心概念去思考。首先你需要考虑时变的统计学模型并理解数据中的依赖只是暂时的相关而已;第二、你应该理解统计学习问题中的反馈效应,每一次行为后对于结果的观测分布,强化学习系统必须适应这些分布。这两个方面都理解起来都十分困难,在这篇文章里作者将强化学习归结成了一种预测分析的模式,而在随后的文章里则是以优化控制的形式展开的。每一种都和我们熟知的机器学习问题有很大的不同。
强化学习与预测分析
人们一般认为机器学习拥有三根重要的柱石:非监督学习、监督学习、强化学习,这三个部分基本上包含了机器学习研究与应用的方方面面。
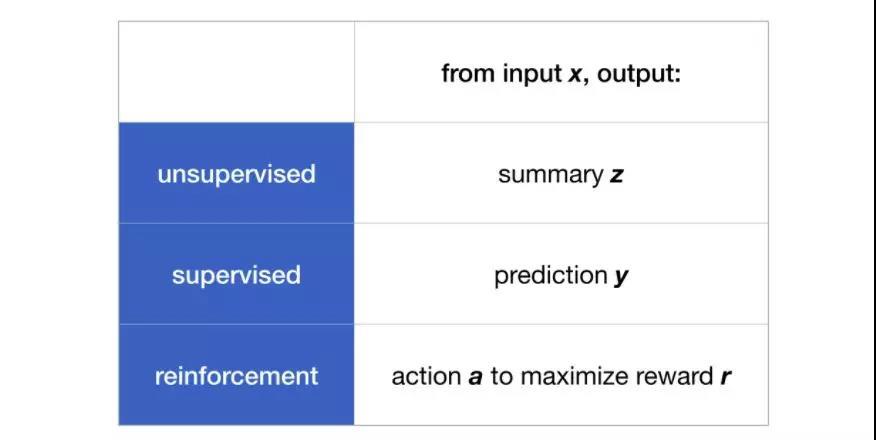
那他们之间有什么不同呢?每一种方法的输入都是一列索引和对应的特征,但对应的输出却各不相同。在非监督学习中,算法的目标是对数据进行有效的归纳总结,我们可以把这一过程视为模型将输入的x数据转换为了可以归纳表示输入信息的低维度输出z。常见的非监督学习包括聚类或者将样本映射到其他的维度上,下图分别表示了常见的聚类、词云和流形学习等典型的方法。

而对于监督学习来说、我们需要通过输入数据x预测出输出数据的某一特征y,这是我们最为熟悉的机器学习方法了,主要包括回归和分类两大分支。
而对于强化学习来说,对于特定的输入x对应着两个输出分别是action和reward。强化学习的目标就是在给定输入的情况下尽可能地选择出能使r(奖励)最大的a(行为)。有很多问题可以用强化学习来解决,从游戏中的在线决策到网络世界中的最大化收益都可以通过这样的方式来获取较好的解决方案。
对于更为广阔的领域来说,下面这张图道出了各种方法和应用所处的阶段和特点。
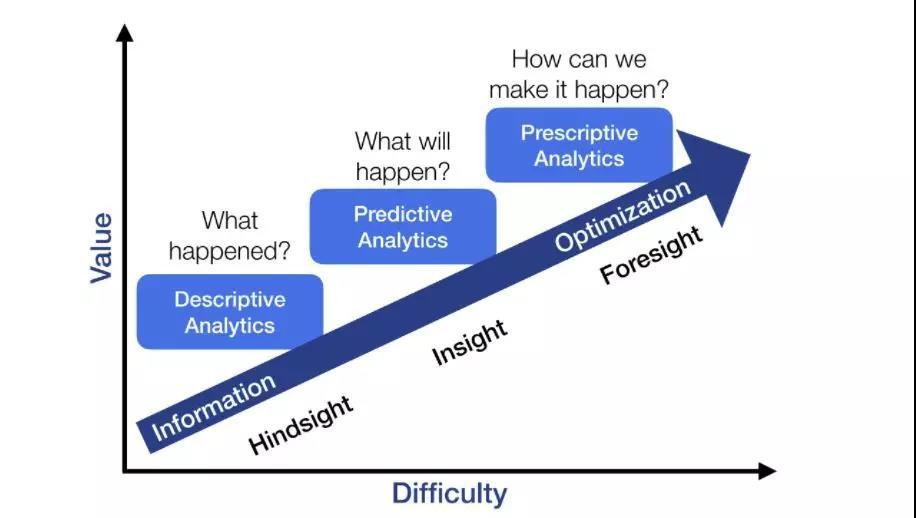
描述性分析指的是通过归纳数据使其具有更好的可解释性,非监督学习就是一种很好的描述性分析方法,而预测分析的目标则是基于现在的数据估计未来的结果,而最终的规范性分析(prescriptive analytics)则旨在指导行动以保证结果。强化学习恰恰就属于最后一个范畴。
上图描绘的结果可能与传统的机器学习智慧大相径庭,而本文想呈现的是一个不同的观点。根据Gartner的观点,非监督学习是这三类机器学习中最容易的一种,因为它的风险会很低。如果你所需要的仅仅只是归纳总结的话它几乎不会给出错误答案。就像GAN对你的卧室颜色进行了正确或者错误的渲染对于结果没有影响。描述性模型和非监督学习主要着眼于美学方面而不是具体的目标;预测分析和监督学习则充满了更多的挑战,我们还需要分析它的精度以及在新数据中的行为和表现。
而最大的挑战则来自于规范性分析。这一类模型的目标十分清晰:强化学习和规范性分析需要分析输入并决定要采取的行动和明确对应的奖励。规范性分析所面对的新数据来源于不确定的环境中,随后需要作出决策并利用这些决策影响环境。这样的系统会在好的决策下获得丰厚的奖励,而在糟糕的决策后则面临着灾难性的结果。但由于反馈来源于复杂的相互联系中使其在理论上难以研究。对于真实的计算系统来说,无论是自动驾驶系统还是庞大社交网站,与真实世界的活跃交互远远超过了你我的想象!
这就是我们需要详细理解强化学习的原因,它为我们提供了一种可以进行交互的机器学习框架。作者认为强化学习将会在机器学习领域有着更多的应用。对于每一个人来说,理解一些强化学习有助于我们更安全的构建和利用机器学习系统。在下一部分中作者将要从优化控制的角度更为详细的阐释强化学习。
强化学习最为迷人的地方在于将机器学习和控制有机地结合到了一起,但人们对于智能体与环境的交互还知之甚少。机器学习和控制在各自的领域的应用有很大的差别,控制是在一个具体的环境中设计出精密复杂行为的理论,而机器学习却是在没有预先模型的情况下从数据中进行复杂的预测任务。控制理论的核心在于连接输入和输出的动力学系统。这一系统的初始状态在输入和环境条件的作用下不断转换,而输出则是输入和对应状态的函数。如果在没有输入的情况下,我们要预测未来的输出只需要知道系统所处的状态即可。
我们利用牛顿定律来作为例子理解控制的过程。如果我们希望将四旋翼悬浮在空中并从一米上升到2m的位置,那么我们首先需要增加螺旋桨的转速以获取更大的升力。这时候螺旋桨转速是输入1,它需要与输入2重力进行相互作用。那么四旋翼无人机的动力学就要满足牛顿定律:加速度的大小与受外力成正比,而这里的外力则是升力与重力之差。同时加速度的大小还与四旋翼飞行器的质量成反比。同时速度等于初速度加上加速与加速的时间,最终的位置则需要满足初始位置加上速度与运动时间的乘积。通过这些公式我们就可以计算出运动到目标位置所需的升力和转速以及作用的时间了。这时候系统的状态就可以表示为位置和速度这一对参量。
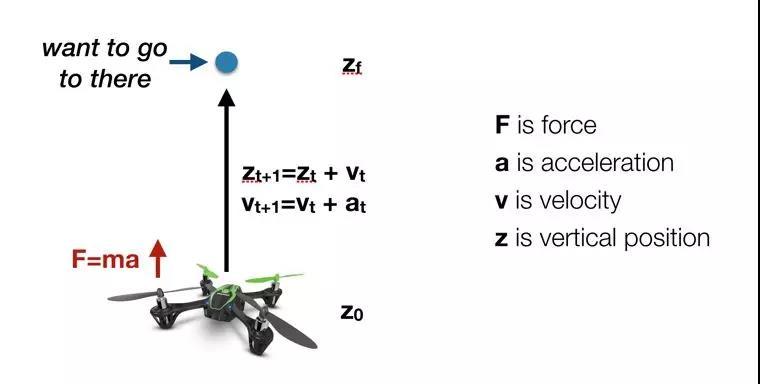
这时候可以将这一动力学系统表示为一个差分方程:
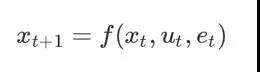
其中f表示状态转移方程,主要受到当前状态、当前输入和误差的影。et可以是随机噪声也可以视为模型的系统误差。
优化控制的目的是尽可能的最小化或者最大化控制目标。我们假设每一时刻我们都能从当前的输入和状态中获取到目前一些奖励,而我们需要的是最大化这些奖励。我们可以将这一过程表现为下面的形式:
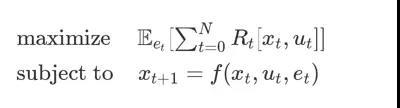
上式表示我们需要特定的控制序列ut来最大化0~N时间内的奖励,而这取决于动力学系统的状态转移规则f。假设我们是控制工程师,那么我们现在需要做的就是为这一优化控制问题建立模型,并寻找最优解,然后问题就迎刃而解了!有很多的控制问题可以按照这样的方式解决,其中最早的求解算法便是反向传播算法。
另一个重要的例子是马尔科夫决策过程(MDP),这时候xt变成了离散的输入值,u(t)则是离散的控制,x(t+1)的概率分布则由x(t)和u(t)共同决定。在马尔可夫过程中,可以将上述变量表示为概率分布,同时可以利用动态编程的方法求解这一问题。
讲了这么多,现在是我们把学习引入到控制过程中的时候了。如果我们对于f一无所知那么我们将如何建模如何解决问题呢?这就是机器学习可以大显身手的地方了!
我们可能不知道螺旋桨在给定电压下的推力,我们该如何建模呢?首先我们应该利用实验去观察在不同的输入下一个动力学模型是否适合这个系统,随后将这一模型转换为一个优化问题。
对于更为复杂的系统,我们不可能写出一个紧凑的参数化模型。一种可能的方法就是不去管模型而是尝试在x(t)的不同测量来不断增加奖励,这就引入了”规范分析“领域的强化学习。这样的规范分析不仅利用从头开始创建控制系统,同时也适用时变模型的建模和分析。需要强调的是,这是一种纯粹依赖于反馈的控制方法,而不依赖于传统的控制理论。
其中关键的不同在于我们对于一个动力学系统的了解程度有多么的深刻,从而才能建立优化的控制过程?使系统达到高水平控制性能的优化过程是什么(重复与监测)?
这两个问题构成了强化学习的对于经典控制问题的核心。
来源:argmin.net
强化学习入门之旅下一站:
The Linearization Principle >>http://www.argmin.net/2018/02/05/linearization/
The Linear Quadratic Regulator>>http://www.argmin.net/2018/02/08/lqr/


图像影音设计相关的软件
凡科快图
- 4.5
(95)咨询产品免费试用墨刀
- 3.9
(423)咨询产品免费试用Pixso
- 3.9
(22)咨询产品免费试用



行业专家共同推荐的软件
蓝湖
- 4.0
(584)咨询产品免费试用Canva可画
- 4.0
(207)咨询产品免费试用字魂
- 4.5
(20)咨询产品免费试用



限时免费的图像影音设计软件
Dprox创意3D视频
- 5.0
(1)咨询产品免费试用万兴喵影
- 3.9
(31)咨询产品免费试用易企秀
- 3.8
(260)咨询产品免费试用



新锐产品推荐
登云-美采供应链
- 0.0
(0)咨询产品免费试用智慧会务
- 0.0
(0)咨询产品免费试用易房大师
- 0.0
(0)咨询产品免费试用房友-中介软件
- 0.0
(0)咨询产品免费试用房友-财务薪资管理软件
- 0.0
(0)咨询产品免费试用Openbase
- 0.0
(0)咨询产品免费试用







