Google Brain工程师演讲实录:TensorFlow 与深度学习
作者 | 周玥枫 ,编辑 | vincent,AI前线出品| ID:ai-front
本文是Google Brain工程师周玥枫在QCon上海2017和DevFest 2017上的演讲实录,由GDG整理和发布。
我的名字叫做周玥枫,我是 Google Brain 的工程师,我现在做 TensorFlow 和 TensorFlow 分布式的开发以及使用机器学习来优化 TensorFlow 的研究项目。
今天首先跟大家分享深度深入学习的例子,然后再跟大家简单介绍一下什么是 TensorFlow ,以及 TensorFlow 一些最新特性,包括即将公开甚至还没有完成一些的特性,如果有时间的话,我会花一些篇幅着重介绍新的特性。最后的时间我会简要介绍一下 Google Brain 两个研究项目。
Machine Learning
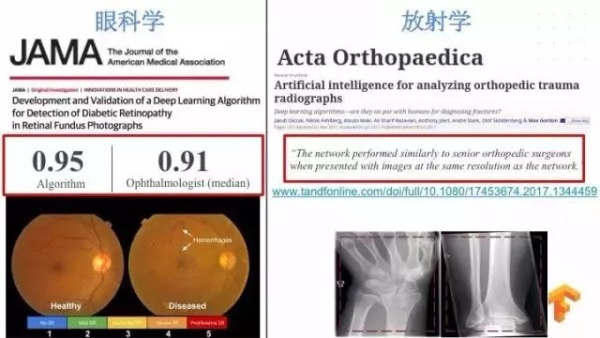
今天,我们看到机器学习已经改变了我们的世界,机器科学家用深度学习的方法来检测糖尿病和视网膜病变,其中检测视网膜病变达能到 95% 的准确率,甚至超过眼科专家 91% 的准确率。机器学习实现了机器和人类专家相媲美的准确率。
同时机器学习也可以用在自动驾驶方向,可以让交通更加安全和高效。

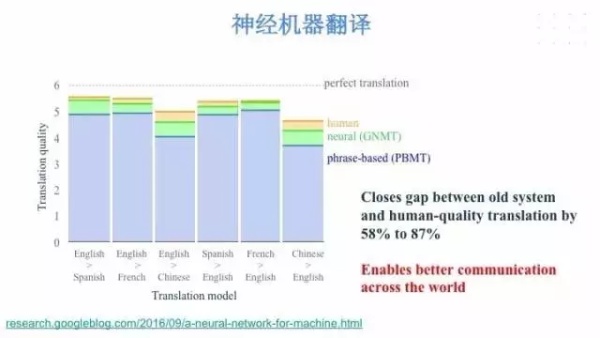
其次,机器学习能够跨越语言的障碍,实现更加便捷的沟通和交流,我们知道传统的机器翻译系统需要把不同语言词组对应起来,通过一些复杂的甚至手写的规则,把一种语言转换为一种语言,这种系统非常庞大且不利于维护,而且准确度不够高,所以最近兴起了一种基于神经网络的方法,我们将其用 TensorFlow 实现出来,用这种方法来缩小机器和人类翻译的差距,能够使翻译更加准确和自然。
同样的,机器学习还可以给人类带来愉悦,可以实现自动修改照片、突出人物的前景、背景虚化等功能,我们很快可以在手机上看到这个功能。

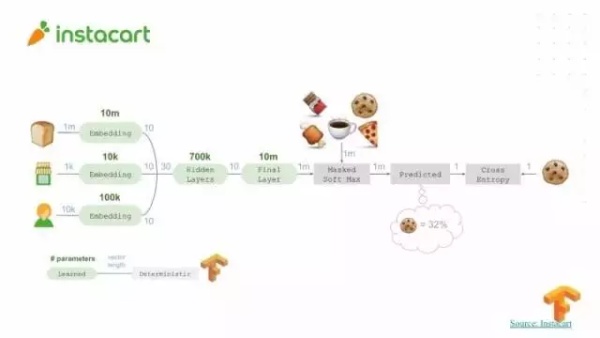
接下来看看机器学习在工业界的应用,第一个例子是 INSTACART ,它是做杂货当天送货服务的,顾客通过网络应用程序从当地许多零售商选出想要的商品并且购买杂货。这个软件的客户非常多。客户在购买时面临一个问题,就是从数百万计零售商店或者商品中选出自己想要的物品,所以 INSTACART 为了让购物者更快地找出想要的商品,用 TensorFlow 建立了一套深度学习模型用来最有效地排序商品列表,这种方法能大大省下购物者寻找商品的时间。
第二个例子就是 UBER ,UBER 用 TensorFlow 和基于 TensorFlow 的开源项目来构建一个叫做“米开朗基罗”的系统,这是一个内部使用的机器学习平台,谷歌希望利用这个平台让内部使用 AI 就像他们请求乘车一样的方便。这个系统涵盖了从数据管理、数据获取和模型训练、评估、部署等方面,而且这个系统不但支持 TensorFlow 深度学习,还支持其他机器学习的模型。
第三个例子是 KEWPIE ,它用 TensorFlow 搭建了人工智能系统用来改善婴儿食品的质量,对食物产品进行人工智能分析,这样可以识别出产品中可以接受的成分并且剔除产品中不能接受的成分,这样保证了婴儿食品的质量。

而实现上述这一切所有的基础框架就是 TensorFlow.
我们在 2015 年末开源了 TensorFlow ,希望把它做成能够服务所有人的机器学习平台。我们想要将它做成一个快速灵活的、生产环境就绪的框架。它可以很方便可以做研究,也可以很快部署到生产环境当中。TensorFlow 本质上是一个大规模的运算框架,它的运算被抽象成一张运算矢量图。就像在这边看到一张运算图一样,上面的节点代表运算或者状态。当我们完成了一些运算或者结束了一些状态的时候,我们的数据就从一个节点流到另外一个节点。这个图可以用任何语言来构建,当这张图构建完之后,我们把它传到 TensorFlow 核心当中进行编译,进行优化然后来执行。

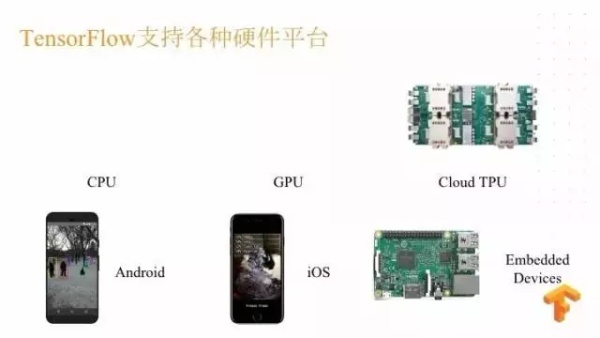
TensorFlow 也支持很多硬件平台,从最初的 CPU、GPU ,到即将发布 CLOUD CPU ,还有对安卓、 iOS 的支持,甚至对嵌入式设备的支持。
我们将 TensorFlow 开源到 Github 上面后,过去两年兴起了许多围绕 TensorFlow 活跃的开源社区,现在我们有 67,000 多个 star ,有 17,000 多个 Github 项目名字当中包括 TensorFlow. TensorFlow 不断出现在各种大学课程和在线课程里面,很多大学也正在开发基于 TensorFlow 的课程,除此之外我们也发布了 TensorFlow 中文网站,大家把它可以当做入门 TensorFlow 的初级教程,叫做 https://tensorflow.google.cn.
New Feature of TensorFlow
现在我们看一下 TensorFlow 的最新特性。首先是 Eager Execution ,Eager Execution 是一种新的编程模式,我在之前一张幻灯片中展示了一个基于 TensorFlow 的静态图。
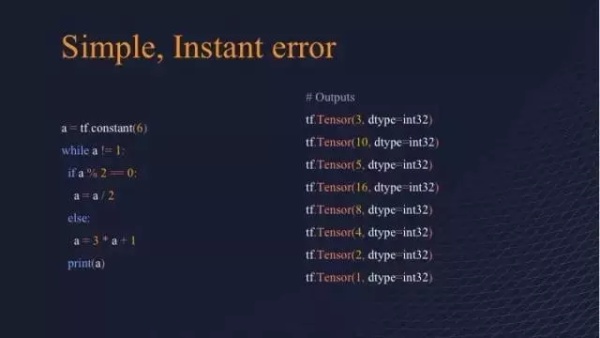
Eager Execution 解决了静态图中一些问题,解决了什么问题呢?首先它可以少写很多代码,就像上图一样。其次,通过 Eager Execution 写代码可以立刻发现它的错误,相对之前来说可以大大提高编写代码查错的效率。第三是可以用 Tensor 来编写控制流,就不需要用 TF 来做循环甚至做判断。最重要一点是如果用其他语言编写这张图的话,再把这图传到 TensorFlow 核心中相当于编写了另外一种代码。看到这个幻灯片就是简单的例子,充分说了 Eager Execution 的简单之处。
今年的 Google I/O 大会宣布了第二代 TPU,我们第二代 TPU 既可以做推理也可以作训练。一个 TPU 可以实现很高的词典运算。我们甚至可以把很多代 TPU 联合起来成为一个就像超级计算机一样的计算核心。在第二代 TPU 的帮助下,我们可以在 20 小时内全部训练出 RESNET-50 的模型,以前如果只做一个 TPU 的训练,可能要花一周的时间来训练这个模型。今天第二代 TPU 即将发布到 Google Cloud,并且推出供大家使用。

下面讲一下 TensorFlow 上层 API,除了神经网络训练速度,大家还关注如何更加方便实现用 TensorFlow 上层 API 来创建神经网络。Keras 是其中一个 API ,它支持很多的后端。相信很多观众都用过 Keras ,从本质上来讲 Keras 更加像一种 API 开发规范。TensorFlow 有一个 TF 就是 Keras ,但是它只是 API 规范实现的一种方式,使用的是一个自定义 TensorFlow 后端,有了这个后端,我们可以让 Keras 与 Estimators 或者 Secving 整合起来,这样会对分布式提供更好的支持。
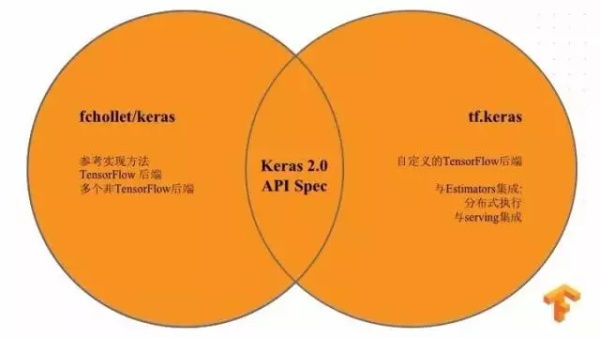
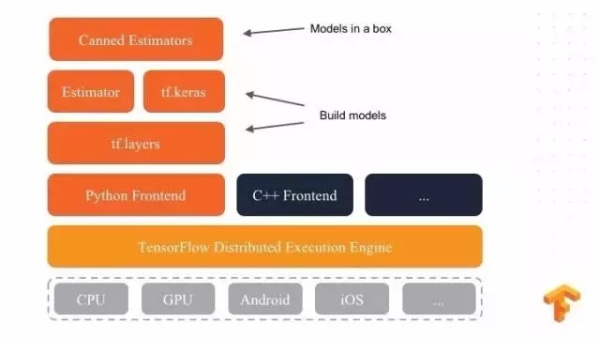
还有一个在 TensorFlow 里面介绍的概念,叫做 Estimators ,这是一个比较轻量化,并且在谷歌内部生产环境中广泛使用的 API ,其中 Estimators 提供了很多模型供大家使用,叫做 Canned Estimator ,他们的关系是这样的:Estimators 和 tf.keras 上层封装了一个 Canned Estimator ,可以用其来封装成各种模型。

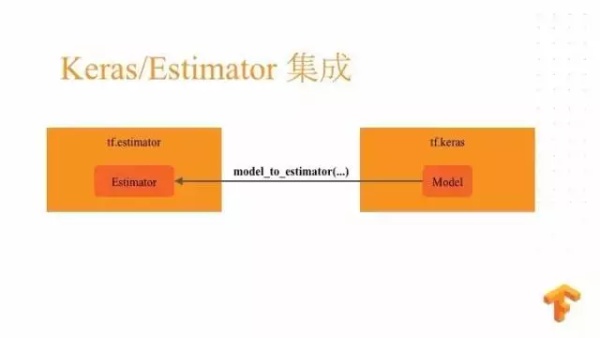
如果你们习惯于 Keras 的接口的话,我们提供了一个上层 API 转换的工具 ,叫做 model_to_estimator ,一旦你有一个编译好的 Keras 模型就可以调用这个 model_to_estimator 来获取一个 Estimator,从而将 Keras 转换成了 Estimator。
Estimator 还提供了分布式训练的接口,如果你用 TensorFlow 来做分布式训练的话,你就可能熟悉我们的分布式模式。我们的 Estimator 很好地提供了对分布式训练的支持,只要写一份单机的代码,它就可以帮你构建好在不同机器上的执行的程序,训练的程序只要调用 Estimator.train 就能完成这一执行过程,只要调用它的 Estimator.evaluate ,整个集群就可以开始训练了。
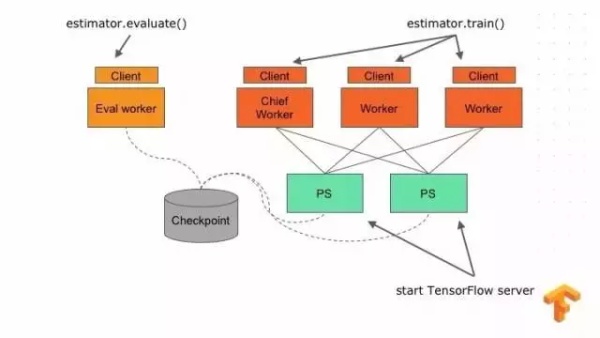
大家可以看一下这些 API 的文档:TF, KERAS, TFLAYERS 等等,我们还发布了一个改进过的程序员指南在官网上,希望大家去看一下。

下一个特性是 TensorFlow Lite ,TensorFlow Lite 是跑在移动设备上的 TensorFlow 的一个子集。现在移动设备无处不在,并且越来越重要。在移动设备上,我们可以在野外判断这个狗是什么品种或者判断这个植物有没有病害,利用人工智能都可以在移动设备做一些应用,所以我们推出了 TensorFlow Lite.
为什么很多时候要在移动设备上做?除了刚才说的那些应用场景,为什么要做移动设备的推理?这是因为我们时常需要在一些特殊环境下做一系列的推理,很多时候,尤其在野外,我们的网络带宽非常的低,网络延迟非常大。如果每次推理都向远程服务器发送请求,那对移动设备的电池能力要求很高。虽然现在市面上对移动设备能够完成推理有迫切的需求,但是其中存在很多的挑战,最主要的挑战是因为移动设备的内存、计算资源以及带宽等等受到了限制。从编程角度来讲,因为平台抑制性很高,开发越来越复杂,比如说在安卓上,我们可以使用 CPU 或者指令等方式编写底层代码,在 IOS 上又有自己一些平台和工具,这种不同平台的工具让我们的硬件以及 API 的开发,甚至存在不同的 API 让我们的开发变得更复杂,所以我们设计了 TensorFlow Lite.
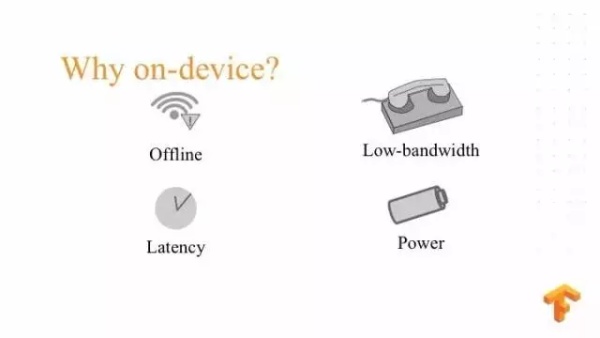
相比 TensorFlow Lite 的话, TensorFlow 主要关注一些大型的设备。TensorFlow Lite 让小型的设备应用更加效率,现在我们通过一个小的例子看 TensorFlow Lite 如何工作的。
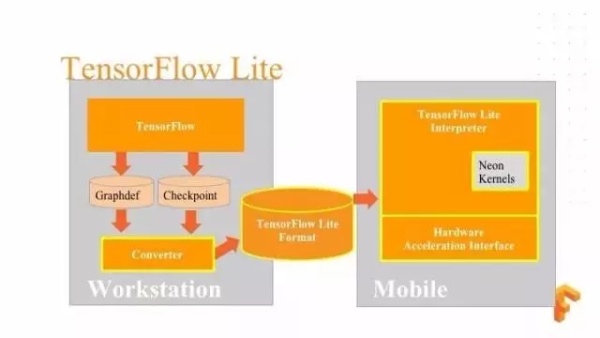
这个是 TensorFlow Lite 生命周期,首先我们以标准方式来运行 TensorFlow,运行结束之后,我们得到 Graphdef 和 Checkpoint,我们通过 TensorFlow Lite 提供一个转换器,把它转换成 TensorFlow Lite 的模型格式。有了这个 TensorFlow Lite 格式的模型之后,我们就可以把它转移到移动设备当中。接入 TensorFlow Lite 显示器就能够在移动设备加载这个模型。如果我们的显示器直接调度 NeonKerels ,如果是在其他设备上,还可以利用硬件加速器接口来定义自己对自己硬件的一些优化。
下一个特性就是 Input Pipeline ,不管是初学者还是专家都会对 Input Pipeline 感兴趣,因为 Input Pipeline 使用起来非常痛苦。

它主要有两种模式,一种是 Feeding,它优点是可以用 python 灵活处理零距,但是性能很差。而且单线程跑,每一步训练都要等待数据处理的完成,这个对 GPU 来说效率非常低。另外一种方式效率高一点,就是把数据处理变成一系列的操作,这使用一个 Queues 作为数据存放的临时空间,我们把预处理好的数据和一些中间预处理数据放在 Queues 里面,通过 python 来控制 Queues 的输入和控制。但是有一个问题,这个 python 有一个权值解释器的锁,所以它让这个 Queues 输入性能受到很大的限制。

还有一个问题就是,我们写的数据处理模块没有办法得到常用,也没有办法在训练的时候更改输入数据。所以我们了开发了一套 Input Pipeline,因为种种原因,所以把它设计成惰性的列表。因为我们的数据很多长得类似,而且数据量可以比较大,所以可以把它定义成 LAZY,我们把它定义成惰性列表之后,可以很自然用函数编程语言中的 map 和 filter 来定义预处理管道,我们在很多语言当中都可以看到 map 和 filter 的操作。现在我们看一下它的接口,我们还有第二个接口叫做 Iterator,可以方便把 edements 数据取出来。就像很多一般的编程语言里面的 Iterator 一样,我们可以对这个 Iterator 配置不同的数据,PPT 上这就是一个例子,大家可以看一下。

在神经网络解决问题的时候,神经网络也会给我们带来一些新的问题,就是我们设计神经网络架构需要投入大量的专业知识和时间投资,比如这个就是谷歌图象分类的一个 .NET 的架构,这个神经网络架构设计从最初的卷积的架构到现在复杂的架构,经过研究人员多年的实验不断重复、完善,才得以达到这么复杂的模型。
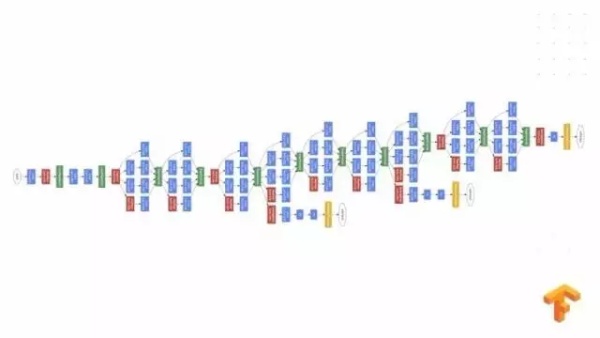
我们与其让科研人员不断在电脑面前,为什么不用强大计算资源,让机器自动寻找好的神经网络架构?在谷歌我们用一种方法,就是用 RNN 循环神经网络来生成一个子网络,这个想法的来源是因为我们可以把一个神经网络对应成一个训练化的一个个序列,RNN 非常擅长解决这类问题,所以我们用 RNN 来生成一个子网络,我们把这个子网络用真实数据进行训练。通过训练准确度的好坏来更新 RNN 的控制器。在它下一次迭代当中,RNN 就会输出更高精度的子网络。这是 RNN 转接架构的例子,这个例子看上去错综复杂,其实也不难理解。

我们也尝试用同样的方法来生成优化函数,然后把生成的优化函数和常用的函数来进行对比,从这张表可以看到生成的函数超过了现有函数的精度,但是这些生成的函数非常的不直观,所以我们就开始想,有没有更加直观的方法来处理 learn 2 learn 这个问题,于是我们想到了进化的算法,或者说遗传算法。既然一个简单单细胞生物都可以进化到非常复杂的、有独立思考多细胞生物,那么我们可以不可以把同样理论用到模型的构建上来,于是我们就设计了这样一种算法,在每个时间的开始,我们建立了含有一千个训练好模型的种群,每一步进化从一千个模型中随机选两个,比较他们的准确率,准确率低的模型就会被扔掉,准确率高的模型会留下来,而且模型会繁殖,他们繁殖的方式就是给模型创建一个副本,并且简单修改这个模型,看上去像基因变异一样,我们会训练这个变异的副本然后放在种群当中。
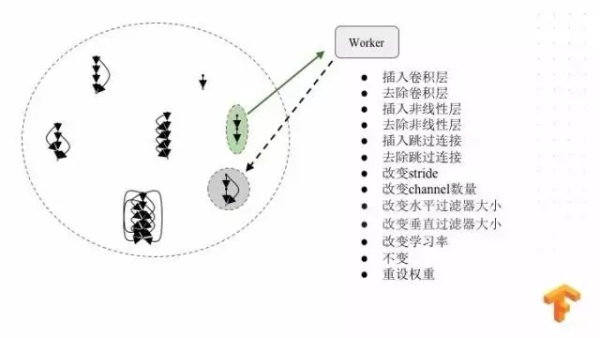
这个是分布式训练的细节。模型变异有很多种,我们刚才提到结构的一些变化,甚至也有一些会保持不变,但是我们会对它多训练一下,或者重新训练一下,因为初始化变异非常重要。变异化的选择是均匀分布概率的模型。
我们看一下进化时间的最新进展,图中横轴代表的是时间,纵轴是准确率,里面每个点代表种群当中一个模型,灰色点是被淘汰的模型。右上方蓝色的点是存活下来的模型,训练三天之后就在这个位置。训练三天之后就可以得到一个比较高的准确率。在训练十天之后,可以看到准确度达到停止期,也就是我们找到了个比较理想的模型。
Device Placement
我们看一下另外一个研究项目叫做 Device placement ,他是用强化学习的方法来做 Device Placement ,当前机器学习使用了非常多的模型,也使用非常多的数据,这个要求我们必须有很多的设备共同训练这个模型。
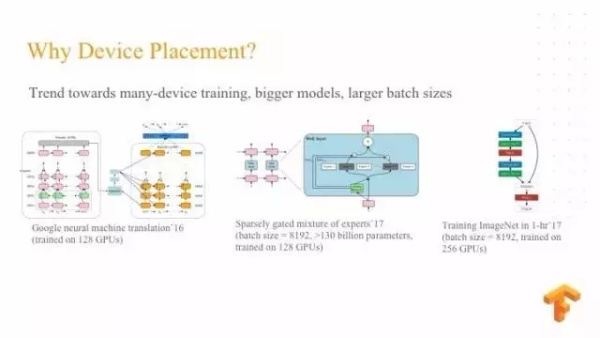
比如说看到这个翻译的模型就非常大。我们通常使用 128 个 GPU 来训练,我们先简单介绍一下 Device placement ,Device placement 就是把计算和设备对应起来,目前我们都是用一些人工的方法,甚至简单的算法。我们设置算法需要我们对设备有充分的了解,而且对模型有充分的了解,这个算法并不是简单从一个模型推广到另外一个模型。但是目前非常时髦的做法,都是将基于这些规则的系统转化为,变成基于机器学习的系统,所以我们也用了类似的方法。我们用强化学习的方法来解决这个 Device placement 的模型,我们受 learn 2 learn 方法的启发来创建一个类似的模型。
我们有一个网络,这个网络以神经网络作为输入,同时告诉一个网络有多少计算资源,这个网络就会告诉我们 Neural Model ,我们跑一下这个放置好的 Neural Model ,根据运行的时间来调整一下神经网络,我们用类似的机器翻译的架构。因为模型比较大,比较慢,我们采用了数据并行方式来做训练。


之后我们看一下训练出来的结果,这是在一个神经翻译系统 Device placement 的结果,上面白色的点代表是在 CPU ,在 CPU 运行的节点,下面彩色点代表在不同 GPU 运行的节点,尽管取得了 20% 左右的提高,但是还是非常不利于理解。现阶段这个在输入端采用了 CPU ,到后面都是采用了 GPU 。
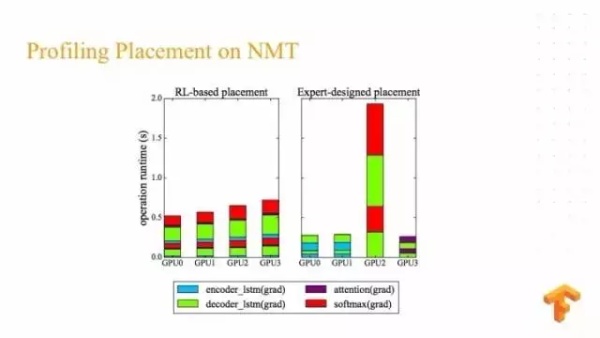
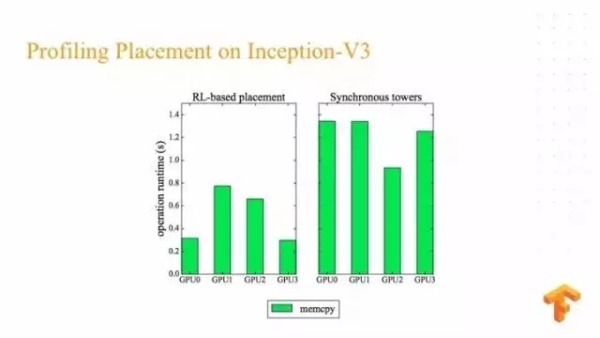
最后两张图表示我们在神经翻译系统上,每个 GPU 运算非常平衡,而右边人类专家设计的运算非常不平衡,在 GPU2 花了非常长的时间,在其他 GPU 花了很少的时间,但是这个也是可以理解,因为专家设计一般只考虑到一部分。在 Inception V3 我们的结果不是非常平衡。但是可能是因为 Inception V3 当中有一些过分的依赖,我们的结果仍然在 Inception V3 有总体的运行时间上的提高。后来我们做一些分析发现因为在数据拷贝期间,我们花了更少的时间。所以总体对它有一个运行时间的提高。
The End
我们讲了两个例子,我们探索如何用算法或者机器学习来优化机器学习的模型,并且取得了一定的进展,我们相信在不久的将来,如果有更好的计算资源,以后的所有架构将是由电脑的生成,谷歌已经给大家走出了探索的第一步,希望大家都可以参与其中,我讲到这里,谢谢大家!
上海谷歌开发者社区授权发布,原址为:
TensorFlow 与深度学习|DevFest 2017 实录


图像影音设计相关的软件
凡科快图
- 4.5
(95)咨询产品免费试用墨刀
- 3.9
(423)咨询产品免费试用Pixso
- 3.9
(22)咨询产品免费试用



大厂都在用的图像影音设计软件
蓝湖
- 4.0
(584)咨询产品免费试用Canva可画
- 4.0
(206)咨询产品免费试用字魂
- 4.5
(20)咨询产品免费试用



限时免费的图像影音设计软件
Dprox创意3D视频
- 5.0
(1)咨询产品免费试用万兴喵影
- 3.9
(31)咨询产品免费试用易企秀
- 3.8
(260)咨询产品免费试用



新锐产品推荐
斗鱼营销平台
- 3.7
(4)咨询产品免费试用爱站网站长工具
- 0.0
(0)咨询产品免费试用Alexa排名优化工具
- 3.9
(20)咨询产品免费试用小红书蒲公英
- 0.0
(0)咨询产品免费试用动维
- 0.0
(0)咨询产品免费试用51拉网站统计
- 0.0
(0)咨询产品免费试用







