解密特斯拉自动驾驶芯片和背后一号人物
编者按:本文来自微信公众号智东西(ID:zhidxcom),作者:Origin 。36氪经授权转载。
上周,智东西撰文介绍了英特尔的AI芯片Nevarna;紧接着,国内地平线发布了AI芯片旭日与征程。“AI芯片”这个一年之前还处于无名状态的词,已经成为一片红海。
在自动驾驶领域,AI芯片其实并非新奇玩意。Mobileye的EyeQ系列芯片,就是较早应用于自动驾驶的AI芯片之一。而在这个月早些时候,硅谷钢铁侠马斯克,还宣布了特斯拉正在研发用于自动驾驶的AI芯片,回顾马斯克对自动驾驶芯片的各种动作,我们发现近来各种跳票“不靠谱”的他,其实对技术发展的趋势,远比看上去更理解。
马斯克对特斯拉自行研发自动驾驶芯片的布局,从两年前就开始了。
从Mobileye到英伟达 特斯拉的自动驾驶焦虑症
2014年,特斯拉找上Mobileye,用上了它家的新一代辅助驾驶芯片EyeQ3,来武装自家的独门绝技——自动驾驶系统Autopilot。
在这个时间点,EyeQ3无疑是最好的选择。它的计算性能达到300Gflops(每秒3000亿次浮点运算),并且内部封装了先进的ADAS算法,广泛用于各家车厂的的ADAS系统中。

▲图中圈内为EyeQ3
但对特斯拉来说,Mobileye的EyeQ3成在这一点,败也败在这一点。去年特斯拉Model S撞卡车事件发生后,特斯拉与Mobileye开始分道扬镳。当时人们普遍认为是这场事故导致了双方的信任破裂——对特斯拉来说,Mobileye并不保证自动驾驶足够安全,而Mobileye也很冤,因为当时还只定位于ADAS而已,特斯拉车主违规操作不仅害死了自己还让Mobileye的名声遭受了打击。
不过,这件事虽然看上去是特斯拉与Mobileye蜜月结束的导火索,但背后的原因仍然是,特斯拉的计算力焦虑。 马斯克一再宣称要将全自动驾驶短期内带上特斯拉的Model系列,但从未实现过。一个重要的原因就是,Mobileye的EyeQ3这块芯片,在计算力上并不能满足需求,它只是为ADAS设计的。
而在2016年初,英伟达推出了Drive PX 2,理论计算性能最高达到10Tflops,比EyeQ3的性能来得要粗暴得多。并且,希望在自动驾驶领域建立起自家GPU计算生态的英伟达,给需求较大的特斯拉还开出了优惠的价格。此时急于对自动驾驶功能进行升级的特斯拉,选择再度回归英伟达的拥抱,到也显得合情合理。
以Model 3为例,其为自动驾驶功能和环视配置了8枚摄像头与12枚超声波雷达以及一枚毫米波雷达,大量的视频图像数据处理以及在其之上运行图像识别算法,将会消耗巨量的计算资源,这显然是算力只有300G的EyeQ3力所不及的。
相对于EyeQ3只是一块ADAS芯片,Drive PX 2实质上是一台车载电脑,是更加完整的解决方案。

▲上图为Drive PX 2 AutoCruise,下图为Autochauffeur

在配置了Drive PX 2过后,特斯拉在度过车祸事件的一阵低调过后,确实也对自动驾驶功能进行了更新。车东西不久前曾体验过特斯拉新的AutoPilot,发现开启后维持在一条车道上撒手不管也没问题,不过特斯拉依然做了限制,时间太长系统会发出警报。
但Drive PX 2就能解决马斯克的焦虑了吗?显然也不能。因为Drive PX 2实质上有多个版本,其中算力较高的是Autochauffeur,算力较低的是Drive PX 2 AutoCruise,其上只搭载了一个Nvidia Parker Soc。
有国外车主拆解过特斯拉Model S上配置的Drive PX 2,它长这样:

▲英伟达为特斯拉定制的Drive PX 2车载电脑
可以看到,特斯拉所用的Drive PX 2并没有像Autochauffeur版本那样使用了两枚Soc+两块额外的GPU,而是只有一个Parker Soc+一块独立GPU。因此特斯阿拉所用的,更像是英伟达为其定制的AutoCruise版本。对于Drive PX 2,英伟达自身都明明白白地说过,要经过多块(多块Autochauffeur)叠加,才能满足L4级自动驾驶的算力需求。所以对于特斯拉上面的Drive PX 2,我们也可以明确其算力支持,不会超过L3水平。
并且,GPU为主的计算架构,一直有着功耗高的问题。为了给这块Drive PX 2散热,特斯拉使用了两枚风扇,也说明Drive PX 2的热设计功耗,至少是在50-100W区间(英伟达硬件工程师曾向车东西表示,双Soc+双独立Pascal显卡的Autochauffeur功耗在150W)。
高成本、高功耗,算力还无法完全满足需求,即使是号称超级车载电脑的Drive PX 2,依旧有着这三个问题。而这些,对自动驾驶量产车来说,都是致命的。于是英伟达也拿出了下一代的Xavier作为应对,功耗/性能比大幅升级,但它的装车量产要到2019年。
马斯克早已等不及了。
揽来大牛沉寂两年? 只因在憋大招
马斯克是个聪明人,不会吊死在一棵树上,这一点,从特斯拉的计算芯片先使用Mobileye EyeQ3再转入Drive PX 2就能看出来。
如果别人的树上结不出果子,那么自己种一颗也不是不行。
2016年1月,特斯拉的硬件工程部门迎来了新的副总裁,一名做芯片架构设计的工程师,名叫吉姆·凯勒,跟他一起来到特斯拉的,还有曾经在他工作过的AMD、P.A Semi、苹果公司中任职过的数十名芯片行业的人才。

▲吉姆·凯勒
跟马斯克一样,吉姆·凯勒也是个不甘寂寞的人。吉姆·凯勒早年间在AMD任职,深度参与了x86-64架构的定制工作,让曾经只支持32位的X86升级到了64位。这也是吉姆·凯勒可能作出的最大贡献——眼下各位内置了英特尔、AMD处理器的64位PC,都有吉姆·凯勒的功劳。
吉姆凯勒也帮助AMD拿出了K7、K8架构,使得AMD在与英特尔的CPU竞争中用速龙压制了奔腾(虽然并未维持多久)。
随后,吉姆·凯勒从AMD离职,后来又加入半导体设计公司P.Asemi出任副总裁,专事设计低功耗处理器。2008年,苹果收购了P.A。于是吉姆·凯勒又成为了苹果A4、A5处理器的设计领头人。
在两家著名公司中领导芯片项目,并且最终产品造福了以亿计的人们,吉姆·凯勒可以说是功成名就了,但他的故事还将继续。
2012年,吉姆·凯勒重返AMD,出任芯片首席架构师。此时的AMD已经在CPU市场上被英特尔打得满地找牙,“i3默秒全”早已成为圈内的笑谈。 吉姆在AMD待了三年,在2015年9月离职。他做了啥?帮AMD打造了新的处理器架构“Zen”。今年,当基于Zen架构打造的AMD 锐龙处理器诞生时,当年AMD速龙对决英特尔的辉煌再度上演,升级缓慢的英特尔大幅提高了下代处理器的性能作为应对。
因此,吉姆·凯勒其实是充当了AMD的“救世主”,而且是在两年前救的,而且是救完就走,不留下一片云彩。

▲AMD锐龙处理器
起2016年加入特斯拉的消息表明,救完AMD过后,吉姆·凯勒又拯救陷入“自动驾驶谎言”中的特斯拉去了。
事实上,马斯克在2015年就感受到了特斯拉可能会面临的自动驾驶危机,当年主动发推文,先行大力招募自动驾驶的软件人才,而后对AMD、英特尔、苹果等公司的硬件人才挖角行动也没有停过。
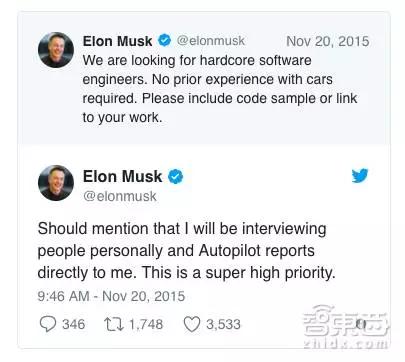
获得吉姆·凯勒过后,特斯拉与芯片制造商/代工商的接触开始变多。去年9月,消息一度传出,三星将帮助特斯拉打造车载芯片,后来消息不了了之。今年早些时候,CNBC曾报道AMD将与特斯拉合作打造芯片,听上去可信度很高——吉姆·凯勒来自AMD,而特斯拉方面也曾经表示,他们在自动驾驶芯片上的选择很灵活。
今年9月,AMD的拆分子公司、芯片代工方格罗方德在对外演示中无意走漏风声,称正在与特斯拉合作。后来格罗方德辟谣称与特斯拉并没有直接合作(也等于间接指出特斯拉在于AMD合作)。一时间特斯拉自研芯片的消息再度沸沸扬扬,AMD还因为这个利好消息股价小涨一波。
直到12月,面对不断下行的股价压力,马斯克把这个消息当做利好放了出来。
如果从吉姆·凯勒加入开始算起,到这个时候,特斯拉的自研芯片计划其实已经潜行了快两年。两年时间,对外零成果,这完全不符合特斯拉的风格。为何一向求快的特斯拉,此时却稳了起来?
因为特斯拉要研发的,正是面向自动驾驶的ASIC。(马斯克原话是“developing specialized AI hardware”)
ASIC,Application Specific Integrated Circuit,专用集成电路,意思就是面向专门计算用途打造的芯片。其特点是在某一特定领域的计算上能够以更低的功耗获得更高的性能。 另一个特点则是,研发周期长,时间通常超过一年。
对于特斯拉来说,在应用了高功耗的Drive PX 2仍然无法实现高级自动驾驶过后,研发出自己掌握的、2-3年的时间是值得等待的。特别是,当这个芯片项目是由吉姆·凯勒主导时。
吉姆·凯勒在辗转AMD与苹果的过程中,曾经开发过基于MIPS架构的网络芯片,还开发过基于ARM V8架构的服务器芯片(MIPS、ARM V8都是RSIC精简指令集架构,一般来说在功耗上具有优势) 拥有了丰富的低功耗芯片设计经验,结合其此前在高性能芯片上的设计能力,他为特斯拉带来的将是功耗/性能表现更加优越、高度适配自动驾驶软件算法的专用芯片。

在马斯克放出特斯拉将自研芯片消息时,他如此形容这款芯片的优势——“this can give 10x power at a tenth the cost”。什么意思?能以十分之一的功耗,实现十倍的性能。吉姆·凯勒也称,现在的AI技术在进行应用时,功耗是一个常被忽视的元素。
从特斯拉众人的一席话中可以看出,他们研发的这款自动驾驶芯片,将在功耗/性能比上下更多功夫。
特斯拉芯片最大可能的代工方格罗方德,也拥有专门面向低功耗的芯片工艺——FD-SOI。近年格罗方德刚刚实现了FD-SOI的22纳米制程升级,宣称功耗比28nm降低了70%,该工艺相较于我们较为熟悉的FinFET而言,更适合需要低功耗芯片的移动计算等场景。
当然,低功耗并不代表低性能。以特斯拉的旧爱Mobileye为例,其明年将要量产的EyeQ4系列芯片,采用MIPS架构搭建,能够以3W的功耗,实现2.5Tflops的计算性能。
而同时玩过X86、MIPS、ARM v8架构的吉姆·凯勒,玩芯片性能跑得上得去,做功耗优化也降得下来。
特斯拉自研背后 自动驾驶芯片正在转向
特斯拉自研自动驾驶芯片,其实反映了随着自动驾驶行业成长、需求明确,其计算的需求由通用转向了专用,运行的由训练走向了落地(Inference,推断),随着自动驾驶向量产推进,自动驾驶系统所需要的芯片,由原本不计代价、不惧高功耗追求绝对算力的GPU,走向低成本(前提是大规模量产摊薄成本)、低功耗、高性能的ASIC。
曾有整车厂出身的自动驾驶创业者向车东西吐槽,业内许多创业者完全没有考虑过自动驾驶的量产问题,其中一个显著表现就是大量堆砌高功耗的计算核心,“将数块GPU拼在一起”,放在车辆的后备箱中。而现在对于要量产的自动驾驶车来说,其计算核心必须是嵌入式的,不仅要满足计算性能,同时要满足低功耗需求,同时成本要可接受,此时ASIC是看上去最可行的方案。
尽管ASIC开发的周期不短,需要的资金也十分惊人(制程较先进时仅是单次流片可能就需要数百万美元),但一旦投入量产、规模铺开,芯片产业的边际效用会立即发挥,将单枚芯片成本压低。
对于特斯拉来说,尽管自研自动驾驶芯片的风险巨大,初始成本高昂,但一旦投入使用,带来的各种收益将是显著的。除了降成本、降功耗,另一点就是频频被提及的自主性:全世界的科技企业都从苹果的成功中学习到一点——软硬件一体的威力。
自研芯片的特斯拉,不仅能够为Autopilot提供定制化的硬件支持,同时也可以将大量自动驾驶算法直接封装到芯片内。构建起这样的能力,将成为特斯拉在自动驾驶竞赛中的核心优势。
除了特斯拉之外,还有其他公司已经走上了这条道路。
上周,国内自动驾驶芯片初创公司地平线,推出了两款AI芯片,其中一枚,正是面向自动驾驶的ASIC“征程”。在参数上,征程能够以1.5W的功耗,实现1Tflops的算力,每秒处理30帧4K视频,对图像中超过200个物体进行识别。

性能功耗比可以直接反映出在自动驾驶领域,ASIC面对GPU时所展现出来的优势——征程每瓦特功耗实现了0.666T的计算力,而英伟达此前推出的Drive PX 2 ,以150W的高功耗,实现的是不到24T的算力。若如此计算,“征程”的性能功耗比达到Drive PX 2的3倍还多。
并且,由于ASIC不是GPU类的通用计算,内部直接封装了算法,数据交换只是底层I/O,因此其计算的时延也会比GPU更低。也是因为这个原因,尽管“征程”这枚ASIC在绝对算力上要比Drive PX 2 Autochauffeur 低上不少,但地平线也称其能够满足L3的计算需求。
而有吉姆·凯勒坐镇、财力也更雄厚的特斯拉,在自动驾驶ASIC上做得更好,只是必然。
当然,与特斯拉分手的英伟达自己也非常清楚GPU路径的优势与不足,在下一代的计算核心Xaiver中,将采用CPU+GPU+ASIC的异构计算方案,Xiaver在提供给不同的合作伙伴时可以采用定制方案。英伟达未选择转入ASIC的路径,是因为毕竟还要做生态,抛弃GPU就没法玩了。不过生态也是英伟达最好的武器,除了底层的cuDNN和Tensor RT等,英伟达还提供在云端强大的训练能力,以及大量的自动驾驶通用算法,包括提供车辆、行人、红绿灯识别能力和可行驶区域检测能力的DriveWorks。这极大地降低了自动驾驶开发的上手难度,对于不像特斯拉那样追求极致的后来者们,生态完整的英伟达仍然是良好选择。
结语:自动驾驶芯片或成特斯拉下一轮救星
尽管马斯克声称,特斯拉正在打造的AI专用芯片“将是世界上最好的AI芯片”,但并未透露它什么时候会诞生。而马斯克已经再一次“夸下海口”,要在2019年实现完全的自动驾驶。有吉姆·凯勒这样的大神助阵,马斯克这一次的承诺跳票可能性看上去小了那么一丢丢。不过,按照人们对特斯拉的期望值来看,只要它能够实现高度自动驾驶,即使稍微晚来了几年,也没有关系。
只是问题在于,无论是地平线这样的初创公司,还是Mobileye这样的老牌,都在自动驾驶ASIC这条道路上越走越远。在短暂引领自动驾驶(实质仍是辅助驾驶)风骚过后,特斯拉的优势已经不再明显。
但马斯克常常能化不可能为可能,无论是造出一辆续航超过500公里的电动车,还是实现运载火箭的回收。这一次,有芯片大神吉姆·凯勒的坐镇,特斯拉在自动驾驶芯片上可能实现的成就,不可小觑。一旦问世,它或许就会成为“不思进取”的AutoPilot的救星。
在特斯拉的不断跳票与被拯救中,自动驾驶正在悄悄走向量产。


图像影音设计相关的软件
凡科快图
- 4.5
(95)咨询产品免费试用墨刀
- 3.9
(423)咨询产品免费试用Pixso
- 3.9
(22)咨询产品免费试用



行业专家共同推荐的软件
蓝湖
- 4.0
(584)咨询产品免费试用Canva可画
- 4.0
(206)咨询产品免费试用字魂
- 4.5
(20)咨询产品免费试用



限时免费的图像影音设计软件
Dprox创意3D视频
- 5.0
(1)咨询产品免费试用万兴喵影
- 3.9
(31)咨询产品免费试用易企秀
- 3.8
(260)咨询产品免费试用



新锐产品推荐
GTCOM-大数据智能分析
- 0.0
(0)咨询产品免费试用Moran
- 0.0
(0)咨询产品免费试用迅法网
- 0.0
(0)咨询产品免费试用英檬科技
- 0.0
(0)咨询产品免费试用百度智能云-文字识别
- 0.0
(0)咨询产品免费试用极客OCR
- 0.0
(0)咨询产品免费试用







