30年前的“CNN梦”在这颗芯片落地,能效比高出Tesla10倍
编者按:本文来自“机器之能”(ID:almosthuman2017),作者:四月,36氪经授权转载。
30年前,基于CNN(Cellular Neural Network)的定制化人工智能芯片的想法在美国加州大学伯克利分校的实验室里萌芽。
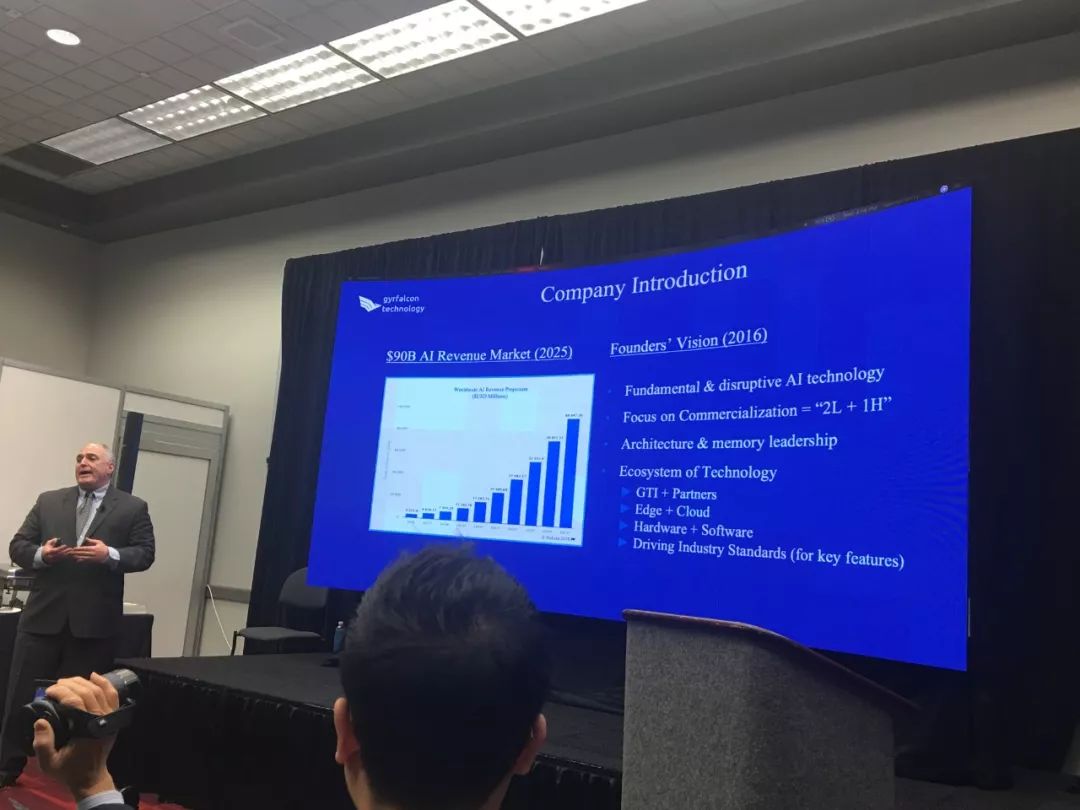
30年后,这个想法终于在硅谷的华人AI芯片创业公司Gyrfalcon Technology里得到实现(以下简称GTI)。
目前,这家成立不到两年的公司已经吸引了全球前五大手机芯片公司中的三家大客户。
GTI合作客户覆盖手机、安防、机器人、工业和IoT领域,且已有量产产品出货,其首个数据中心项目在2018年落地深圳。
GTI的芯片故事最早可以追溯到31年前。
1988年,加州大学伯克利分校的一位名叫杨林的博士和Leon Chua提出CNN(Cellular Neural Network)理论,并同年在IEEE上发表论文《Cellular Neural Networks: Theory》、《CellularNeural Networks: Applications》。杨林团队还基于该理论研发出一颗20*20矩阵的并行模拟电路芯片。
31年后,当年的“CNN”逐步演化成当下的卷积神经网络CNN和循环神经网络RNN,而开辟先河的两篇论文的引用数也分别达到了3871和1462。
更让人兴奋的是,当年那颗停留在实验室里的并行矩阵计算芯片终于在工业界落地——由杨林和董琪联合创办的AI芯片公司Gyrfalcon Technology(以下简称GTI)进一步迭代和优化,并衍生出多条产品线。
他们野心勃勃,希望借此在日益拥挤的AI芯片赛道上拔得头筹。

机器之心1月9日消息(美国时间),CES2019期间,GTI带来三款AI加速芯片,分别是面向AI终端的Lightspeeur®2801S、面向数据中心/云端的Lightspeeur®2803S 、以及全球首款采用MRAM(磁阻式随机存取记忆体)技术的TheLightingpee®2802M。
活动现场,GTI数位联合创始人充分展示了公司多项关键核心技术,包括可同时兼备训练和推理性能、可实现计算存储一体化的独创APiM架构、采用MCMC网络代替常见的SDG模型训练方法。
GTI强调其系列芯片在AI加速方面的高性能、低功耗、高性价比、小尺寸等特性,使用其开发平台能够实现非常快速和有效,支持最大规模的部署。

此外,MRAM(磁阻式随机存取记忆体)技术也颇值得一提。
眼下主流的储存器大致可分为两类:一类以传统内存DRAM、HM为代表,读写速度快但具有易失性(断电数据易丢失),另一类以传统闪存Flash为代表,具有非易失性但读写速度慢。
而MRAM(磁阻式随机存取记忆体)能同时兼顾非易失性和高速读写。由于铁磁体的磁性几乎永不消失,因而磁阻内存可以接近无限次地重写,切断电源时,记录的数据依然保存在磁性单元内,因而也不会丢失数据,在超高速读写时能耗也相对较低。
从MRAM芯片技术的特性上来看,它能解决计算机或手机启动慢、数据丢失、数据装载缓慢、电池寿命短等问题,从而改变消费者使用电子设备的方式。因此,MARM被视为大多数手机、PC、移动硬件等数字产品储存器的替代品。
但MRAM的制作工艺复杂,体积会随内存增加而增大,生产成本高等难以量产的缺点让储存器市场望而却步。据投资人尽调数据显示,全球目前具备MRAM实体产品的公司不超过三家。
三大产品矩阵


第一款芯片,Lightspeeur 2801S旨在解决广泛的Edge AI应用,并快速落地消费电子产品,帮助企业和工业应用此技术设计产品。
IDC在最近的一份报告中称,“到2019年,大约45%的人工智能数据将在Edge上存储、执行和操作”,这使得终端由于其独特的机遇,成为GTI的一个有吸引力的目标。该芯片在2017年9月推出该芯片后,已在手机、机器人、工业以及安防等多个领域落地,其公开客户包括富士通、LG和三星等。
该芯片具有9.3 TOPS / W的等效性能,采用28nm工艺技术。 它尺寸为7x7mm,小尺寸可容纳各类边缘设备。 它的峰值性能为5.6 TOPS,在0.3 W时可提供2.8TOPS。支持VGG和SSD网络模型。
2801S的计算棒版本在2018年开始供客户使用。相比同类的英特尔Movidius,2801S更适合采用大规模采用的商用设备,因为它提供了更好的性能(2801S , 5.6 TOPS VS Movidius,1 TOPS),更好的功率使用(2801S的0.3W, 2.8TOPS VS Movidius的1W ,1 TOPS)和更小的尺寸和更低的价格。
第二款芯片,TheLightingpee 2802M是业界第一款基于MRAM技术的AI加速芯片,并使用专有的GME(Gyrfalcon MRAM引擎),将Edge AI设计带来诸多优势。
使用2803M的设备可支持在同一芯片上同时运行的多个模型,或非常大的AI模型,因为该芯片可提供40MB内存。支持多个模型对于需要复杂的AI实现以支持用户交互或多阶段AI功能的设备非常重要。
该芯片采用22nm工艺技术,并提供非易失性存储器,这对于物联网端点和边缘设备至关重要,这些设备在退出睡眠模式或电源中断后,仍可立即运行。对于使用太阳能或电池供电的远程设备,这是一项强烈的需求。
第三款芯片,Lightspeeur 2803S同时面向边缘产品(家庭和小型办公室中心,自动驾驶车辆,机器人等)以及提供云AI的数据中心加速。
该芯片具有24 TOPS / W的等效性能,并采用28nm工艺技术。 尺寸为9x9mm,在0.7W时的峰值性能为16.8 TOPS。它还支持448x448x4图像尺寸,近似为VGA图像尺寸,满足更多种应用需求。
该芯片可支持各种神经网络,包括ResNet,MobileNet,ShiftNet,VGG和SSD。

此外,GTI还提供基于USB计算棒、加速卡等产品形态。GAINBOARD™系列加速卡可配置2801S或2803S芯片。目前,2801S仅支持并联方式,2803S支持级联与并联两种方式。
2803S支持两种扩展模式:一、多颗芯片级联,线性提升AI算力,运行大规模神经网络;二、多颗芯片并联,同时处理多任务。
性能解读
据介绍,所有Lightspeeur芯片均可并联使用,可将所有芯片封装到GAINBOARD产品中,如4芯片M.2卡,16芯片PCIe服务器卡和64芯片服务器产品。客户可以灵活地选择在先进边缘,边缘服务器或数据中心服务器设计中精确设计多少芯片。
据介绍,基于2803的PCIe开发板性能将优于NVIDIA Tesla4、以及英国的 Graphcore芯片。

16芯片2803 PCIe板将提供了271TOPS,而NVIDIA Tesla 4在PCIe中仅提供65 TOPS,而Graphcore在使用2个芯片的类似配置中仅提供248TOPS。将TOPS的结果与所使用的功耗进行比较,可以看出其对于先进边缘或数据中心操作的卓越效果,因为2803S PCIe将仅使用28W,而NVIDIAPCIe将消耗70W, Graphcore PCIe将消耗高达300W的功耗。

性能与功耗的比方面,2803S提供了惊人的10TOPS /W,而NVIDIA PCIe提供了大约1 TOPS/W,而Graphcore提供了不到1TOPS/W。

2803落地的终端产品可面向无人机,先进的监控设备,机器人和自动驾驶汽车;边缘服务器可以是复杂的工作站,家庭和小型办公室AI中心,以及用于小型私人学校,大厦或社区的单卡AI服务器。基于2803搭建的数据中心服务器将提供大规模云AI服务器操作。这提供了无限的灵活性,因为模型可以大量并行运行,并且在系统中的实际芯片数量没有限制。

为此外,据GTI创始人兼CEO董琪向机器之心介绍,基于GTI芯片首个Cloud AI已经在中国深圳落地,可以支持广泛的用例,包括图像识别,文本分类,情感分析,语言翻译,文本预测,聊天机器人操作,阅读理解和图像字幕。
上述产品均利用GTI提供的三项专利和专有技术引擎、MPE(矩阵处理引擎),ConStreaming™引擎,独特且极其有效的卷积神经网络引擎,以及GME(Gyrfalcon MRAM引擎)。

据介绍,GME引擎为业界首创,只有这项技术才能实现嵌入式MRAM。所有这些引擎在终端设备和数据中心运营中都能提供卓越的结果和效率。目前,GTI已经获批并正在授予的技术专利超过50项。
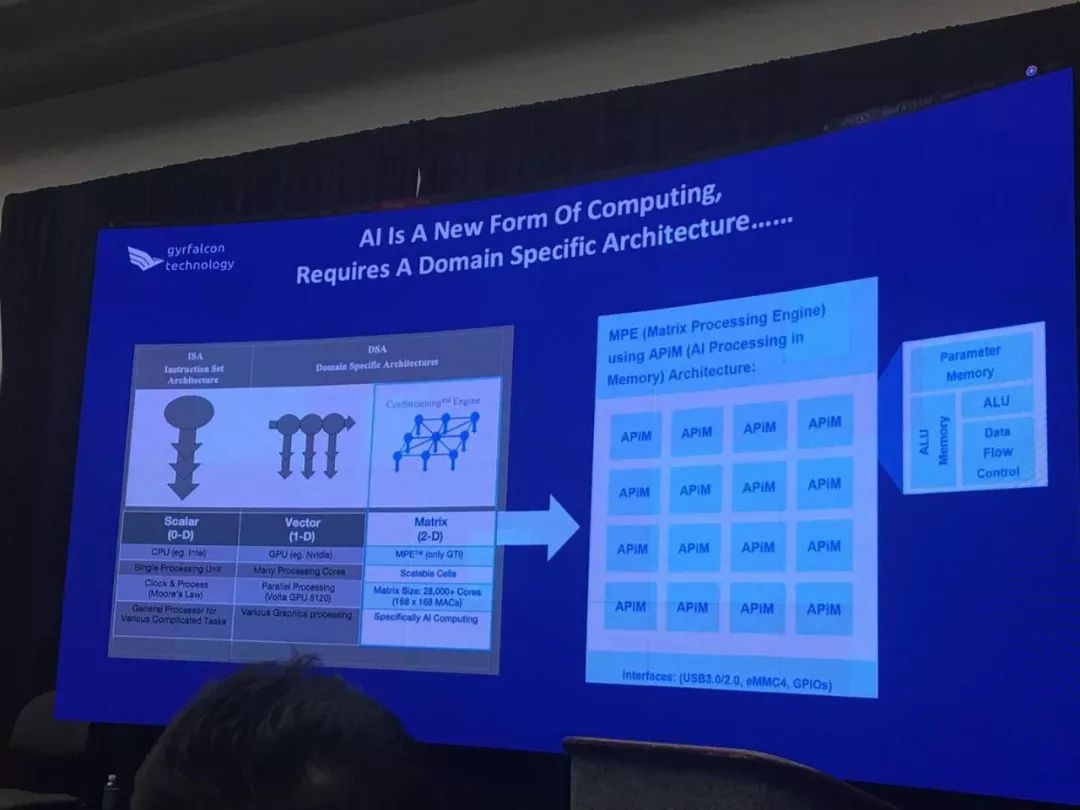
上面提到的MPE可能够让芯片像人脑一样,将逻辑和内存集成在一起,这样在处理人工智能数据时就不会浪费精力和时间。 AI算法可以即时访问数据,快速提供结果,并且不会浪费将数据移入和移出位于系统其他位置的离散存储器的能量。这使得数据处理具有非常高的性能,同时使用非常少的能量。
关键细节探讨
GTI总部位于硅谷地区的核心城市Milpitas,成立于2017年初。GTI由经验丰富的硅谷企业家和人工智能科学家创建,通过将云人工智能的强大功能引入本地设备,推动人工智能的应用,并以更高的性能和效率提高云AI性能,提供最大的人工智能定制新设备和人工智能升级路径给客户。

“我们是唯一一个以矩阵乘法作为基本计算元素的人,”GTI总裁Frank Lin谈道,“其他芯片制造商,他们中的一些人正在考虑新的矩阵或张量架构,”,但是Gyrfalcon在2018年1月就已经向客户提供了第一块芯片。
GTI认为,通过将每个相同的计算单元与内存合并成“内存中的AI处理”与 APiM架构的方法相结合,可以大大减少外部存储器的使用,从而大幅降低AI芯片的功率预算。
比如,2801能够以1瓦特的能量计算每秒9.3万亿次运算,其中每次运算都是乘法累加的步骤。“这比英特尔的Movidius部件的能效比提高了90%。”
而面向数据中心的2803,则不仅可以用于推理而且可以用于训练,GTI采用马尔科夫链蒙特卡洛方法(Markov Chain Monte Carlo),即所谓的随机数递归,以代替更常见的SGD(随机梯度下降)以实现在APiM架构上快速进行模型训练。
2801和2803都采用了嵌入式存储器,2801的数量级为9Mb,与每个计算元件集成在一起的存储器允许芯片完成几乎所有的推理工作,而不必离开芯片到专门的存储器。该公司将其称为“内存中的AI处理”或“APiM”架构。
“我可以将网络模型和数据以及激活单元一次性预加载到芯片上吗,”杨林说道,“不必再与存储器进行频繁的数据输入与读出交换,能够节省大量功耗,这就是为什么性能是那么高。“
2802的另一个有趣特性:非易失性存储器。
2802用MRAM替换2801和2803部件中使用的静态RAM(SRAM)。与NAND闪存类似,MRAM在断电时不会丢失数据。这意味着神经网络可以由客户预先加载,甚至可能在工厂预装,然后部件出货。
在核心软件部分。与CPU和GPU不同,Gyrfalcon的专用集成电路(ASIC)没有现成的编程堆栈。
出于这个原因,该公司刚刚发布了一个开发人员SDK来为这些部件构建应用程序。开发套件可以在两个硬件配件上进行测试,包括一个名为“PLAI Plug”的USB计算棒和“PLAIWiFi”的独立设备,可作为移动端的无线加速设备使用。
沿袭杨林教授的并行矩阵计算思想,GTI展现超脱寻常的算力能力,但同时他们也采取了一个看起来稍显激进的模式——芯片的基础来自卷积神经网络,虽然卷积神经网络在过去几年中已经成为一些最重要的神经网络设计,但是这种选择使得芯片不太容易适用于其他类型的网络,例如“长期短期记忆”网络。
但GTI方面认为这并不是一种局限。
“CNN是所有其他AI的基础,”杨林在接受采访时说道。他指出,“我们发现最大的市场份额仍然由ResNet和MobileNet占据,我们需要做的是支持最主流的模型”。董琪认为,网络模型的形态并不决定真正的应用。试图覆盖所有现有的或即将到来的神经网络,会让AI专用芯片的性能变得平庸。
如果新的网络出现并占据了相当大的市场份额,“那么我们将为此推出另一种芯片,”他补充道。
据公开资料显示,2017年,一村资本母公司华西股份联合华天科技对GTI完成了首轮领投投资。据公开数据显示,Graphcore目前的融资资金超过1亿美元。
Gyrfalcon在采访中谈道,他们已经获得了“美国,日本,韩国和中国的机构和企业投资者的三轮融资”,并补充说“按目前的员工和费用率,公司有资金运营至少三年”。
(现场照片由机器之心驻海外记者Tony提供)


图像影音设计相关的软件
凡科快图
- 4.5
(95)咨询产品免费试用墨刀
- 3.9
(423)咨询产品免费试用Pixso
- 3.9
(22)咨询产品免费试用



大厂都在用的图像影音设计软件
蓝湖
- 4.0
(584)咨询产品免费试用Canva可画
- 4.0
(206)咨询产品免费试用字魂
- 4.5
(20)咨询产品免费试用



限时免费的图像影音设计软件
Dprox创意3D视频
- 5.0
(1)咨询产品免费试用万兴喵影
- 3.9
(31)咨询产品免费试用易企秀
- 3.8
(260)咨询产品免费试用



新锐产品推荐
数盈·洞察云
- 0.0
(0)咨询产品免费试用灵雀云-容器基础设施
- 0.0
(0)咨询产品免费试用观脉科技-全球数字中心
- 0.0
(0)咨询产品免费试用观脉科技-云服务
- 0.0
(0)咨询产品免费试用观脉科技-SASE
- 0.0
(0)咨询产品免费试用观脉科技-全球融合CDN
- 0.0
(0)咨询产品免费试用







