AI错把黑人识别为大猩猩?伯克利大学提出协同反向强化学习
编者按:本文由新智元编译,来源:bair.berkeley.edu,作者:Dylan Hadfield-Menell ,编译:刘小芹 弗格森;36氪经授权发布。
伯克利大学的研究博客最新文章介绍了AI奖励机制存在的缺陷,提出让AI学习人类价值观,价值对齐问题的重要性,以及协同强化学习的一些最近研究。
小心你给的奖励
“小心你许的愿望!”——我们都听过这句谚语。国王弥达斯的故事告诉我们,轻易许愿往往事与愿违。弥达斯是一个爱财的国王,他向酒神许愿希望得到点石成金的能力,并如愿以偿得到了点金术。最初,这很有趣,他把碰触到的一切物品都变成了黄金。但快乐很短暂,当国王拥抱自己的女儿时,女儿变成了一座金子的雕像,国王认识到自己愿望的错误。
我们人类对于实际想要什么非常难以决定,我们建立的人工智能系统也深受其害。对于AI,这句警言实际上应该变成“小心你给的奖励!”当我们为一些应用设计以及部署一个AI智能体时,我们需要指定希望这个智能体来做什么,这通常是采用一种奖励函数的形式:该函数告诉智能体哪种状态和动作的组合是好的。比如说,汽车到达目的地是好的,一辆车撞到另一辆车就不好了。
AI研究在使AI的行为根据规定的奖励函数表现良好方面取得了很大的进展,例如将图像根据分类到正确的标签,以及引导汽车自主行驶。但是,正如弥达斯国王的故事所警示的,重要的不是规定的奖励函数:我们真正想要的是使AI的行为根据设计者或用户的期望来表现的奖励函数。
我们最近的研究《协同反向强化学习》(Cooperative Inverse Reinforcement Learning)正式确定和调查了价值对齐问题(value alignment problem)——引出和优化用户的预期目标的问题。
论文地址

人工智能系统的奖励机制存在缺陷
OpenAI 最近公开一个示例,说明规定的奖励函数与预期的奖励函数(stated vs. inteded reward functons)之间的区别(地址)。其中系统设计师为赛车游戏设计强化学习。他们决定奖励制度是获得得分。这似乎很合理,因为我们的期望是赢得比赛,那就需要得分高。不幸的是,这导致在某些环境中出现了相当不合理的行为。
这个视频展示了一个只追求得分的赛车策略,最终当然是没有赢得比赛。这显然与期望的行为截然相反,但设计者确实得到的是他们要求的行为。
关于价值偏差(value misalignment),我们可以回顾另一个例子,发生在2015年6月,谷歌刚发布一个图像分类的功能。不幸的是,有一个用户报告,谷歌的系统将他的非裔美国人朋友分类为大猩猩。
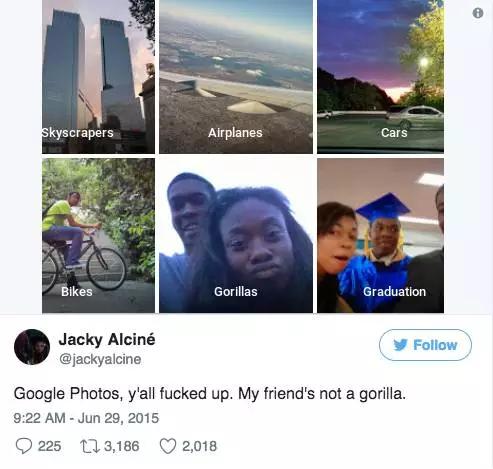
根据给定的奖励措施,学习算法会愿意把将自行车误认为是烤面包机的几率减少。同时把将某人误认为是动物的几率增加。这不是系统设计师的明智选择。
价值对齐问题
我们可以将上述失败归因于错误的假设,也就是说错误地假设了给学习系统的奖励函数是系统设计者真正关心的奖励函数。但实际上,两者之间往往存在不匹配,而这种不匹配最终会导致不好的行为。
随着AI系统的使用越来越广泛,这种不良行为的潜在后果也越来越严重。例如,我们必须很确定,一辆自动驾驶汽车的控制策略能够做出正确的权衡。但是,确保这点是很困难的:汽车不正确行使的方式太多太多。起码,穷举所有方式并评估它们是很具挑战性的。
价值对齐问题(value alignment problem)是将AI的目标与我们的目标对齐的问题。这个问题具有挑战性的原因,在于我们很难描述我们想要什么,甚至描述给其他人都很难,更不用说描述给AI。我们通常假设,正如上面的例子中,我们的目标是已知而且可观察的。
反向强化学习
解决这个问题的一个灵感是反向强化学习(inverse reinforcement learning)。在人工智能研究(例如强化学习)中,我们主要关注计算最优(或者只需OK)的行为。也就是说,给定一个奖励函数,我们来在计算一个最优策略。在反向强化学习中,所做的工作正相反。我们需要观察最优行为,然后尝试计算智能体正在优化的一个奖励函数。这可以引出价值对齐的一个粗糙的策略:让智能体观察人类行为,通过反向强化学习,智能体学习人类的奖励函数,并根据该函数行动。
这个策略有三个缺陷。
第一个很简单:机器人需要知道它是为人类来优化奖励:如果机器人知道某人想要咖啡,它应该为这个人去取咖啡,而不是为自己去取咖啡。
第二个挑战有点难解释:人是策略性的。如果你知道机器人正在观察你,以图学习你想要的东西,那么这会令你改变自己的行为。你可能会夸大任务的步骤,或展示常见的错误或陷阱。这些类型的合作教学行为不是简单地用反向强化学习来建模的。
最后,反向强化学习是一个纯粹的推理问题,但是在价值对齐中,机器人必须共同学习其目标,并采取措施来实现。这意味着机器人在学习过程中必须考虑“探索-开发”的权衡。反向强化学习对于如何平衡这些没有提供任何指导。
协同反向强化学习
我们最近与Human-compatible AI 中心一起完成的工作介绍了正式的、用于价值对齐的问题,我们将这些差异称为协同反向加强学习(CIRL)。
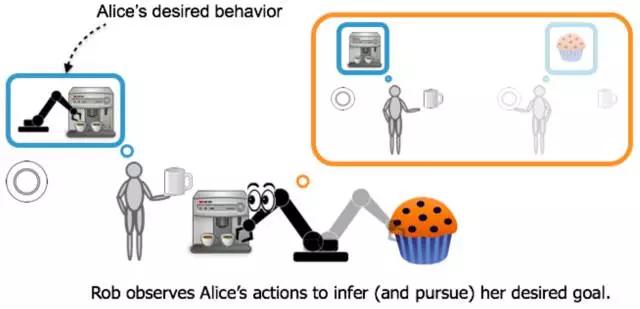
我们可以看到这与反强化学习有着密切的联系。 Alice 根据一些回馈函数进行优化,在帮助她的过程中,Rob将会学习Alice正在优化的功能。 关键的区别是,Alice知道Rob正在努力提供帮助,这意味着最佳的合作策略将包括Alice的教学行为,并确定罗布管理 exploration-exploitation 权衡的最佳方式。
未来的工作
与CIRL的合作之后,我们认为机器人对于什么是正确的回馈功能应该是不确定的。
在即将在2017年IJCAI上发布的研究中,我们调查了这种回馈不确定性对最佳行为的影响。 “The Off-Switch Game (开关游戏)”分析了机器人接受人的监督或干预的动机。 我们用一个CIRL游戏来建模,其中Alice可以关闭Rob,但Rob可以禁用关闭开关。 我们发现,Rob对Alice的目标的不确定性是听取她的激励的关键组成部分。
然而,正如弥达斯国王的故事所说,我们人类并不总是完美地下令。可能有些情况下,我们想要Rob按照Alice心里真实的想法进行行动,而不是她所说的。 在“机器人应该服从吗?”中,我们分析了Rob的服从水平(遵循Alice 命令的速度)与Alice可以产生的价值之间的权衡。 我们表明,至少在理论上,如果Rob可以不服从Alice,Rob可以更有价值,但是还要分析Rob的对世界的建模是错的,那么性能会如何降低?
在研究价值对齐问题时,我们希望为可靠地确定和追求我们所期望的目标的算法奠定基础。 从长远来看,我们预计这将带来更安全的人工智能设计。 我们的方法的关键在于我们必须考虑到真正的回馈信号的不确定性,而不是给予奖励。 我们的工作表明,这导致AI系统更愿意接受人为的监督,并为人类使用者带来更多的价值。 我们的工作还为我们提供了一个工具来分析偏好学习中的潜在缺陷,并调查模型错误带来的影响。 未来,我们计划探索针对CIRL游戏的计算解决方案的有效算法,以及考虑对多个人的价值对齐问题的扩展,这些人每个都有自己的目标和偏好。
原文链接

图像影音设计相关的软件
凡科快图
- 4.5
(95)咨询产品免费试用墨刀
- 3.9
(423)咨询产品免费试用Pixso
- 3.9
(22)咨询产品免费试用



行业专家共同推荐的软件
蓝湖
- 4.0
(584)咨询产品免费试用Canva可画
- 4.0
(206)咨询产品免费试用字魂
- 4.5
(20)咨询产品免费试用



限时免费的图像影音设计软件
Dprox创意3D视频
- 5.0
(1)咨询产品免费试用万兴喵影
- 3.9
(31)咨询产品免费试用易企秀
- 3.8
(260)咨询产品免费试用



新锐产品推荐
信管飞RMS
- 0.0
(0)咨询产品免费试用XySyn迅越综合性印包ERP
- 0.0
(0)咨询产品免费试用印管家ERP系统
- 0.0
(0)咨询产品免费试用哲霖ERP管理系统
- 0.0
(0)咨询产品免费试用全程DRP
- 0.0
(0)咨询产品免费试用赛思ERP系统
- 0.0
(0)咨询产品免费试用







