潮科技行业入门指南 | 深度学习理论与实战:提高篇(10)——目标检测算法FPN
编者按:本文节选自《深度学习理论与实战:提高篇 》一书,原文链接http://fancyerii.github.io/2019/03/14/dl-book/ 。作者李理,环信人工智能研发中心vp,有十多年自然语言处理和人工智能研发经验,主持研发过多款智能硬件的问答和对话系统,负责环信中文语义分析开放平台和环信智能机器人的设计与研发。
以下为正文。

本文介绍目标检测的常见算法之一:FPN。
Feature Pyramid Networks(FPN)
FPN简介
检测不同尺度的目标(尤其是小目标)是很困难的。如下图左所示,我们可以使用同一图像的不同尺度版本来检测目标。但是处理多尺度图像很费时,内存需求过高,难以同时进行End-to-end的训练。因此,我们可能只在推理阶段使用这种方法,以尽可能提高精确度,尤其是竞赛这种不考虑时间的情况,但是在实际环境中我们很难使用它。此外我们也可以创建特征金字塔来检测目标,如下图右所示。但是低层的特征映射在精确目标预测上效果不佳。
注意左右两图的区别:左图是一张图片的4个尺度,然后分别用卷积网络来提取特征并且进行预测,这样每次预测的时候都要用4倍的时间,而且模型的参数也会增加很多。而右图是一张图片,只有一个卷积网络来逐层的提取层次化的特征,然后对4个特征映射进行预测,它可以避免4次的特征提取。但是它的问题在于底层的特征(比如边角等)很难用于判断它是猫还是狗,而只有高层的特征(比如鼻子、眼睛等)才容易判断目标物体。而高层的特征虽然有较强的语义(容易判断目标),但是它丢失了一些更精细的位置等信息,在定位物体时也会有问题。
FPN是基于金字塔概念设计的特征提取器,设计时考虑到了精确性和速度。它代替了Faster R-CNN的检测模型的特征提取器,生成多层特征映射(多尺度特征映射),它的质量比普通的特征金字塔好。因此在左图中图像金字塔提取的特征都是有较强语义的(图中用边框较粗的平行四边形表示);而特征金字塔高层的特征语义较强,但是底层的特征语义较弱,用来预测效果不佳。
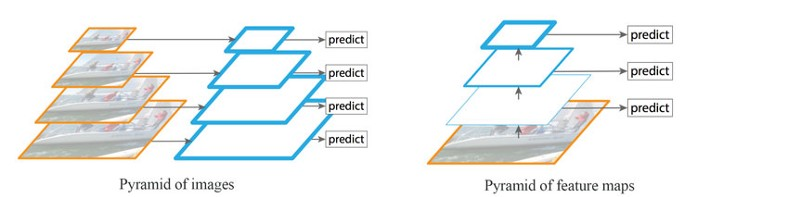
左:图像金字塔;右:特征金字塔
数据流
FPN的结构如下图所示,和图像金字塔类似,它的每一层都有较强的语义,同时它的速度也很快。
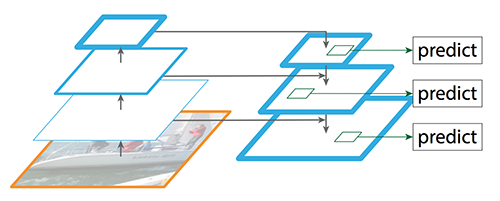
FPN
FPN由自底向上(bottom-up)和自顶向下(top-down)两个路径(pathway)组成。自底向上的路径是通常的提取特征的卷积网络,如下图所示。自底向上,空间分辨率变小,但能检测更多高层结构,网络层的语义在增强。
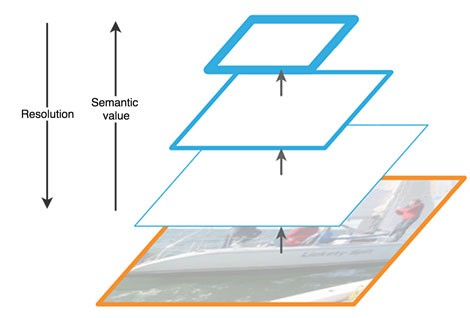
FPN的自底向上路径
SSD(Single Shot MultiBox Detector)也会基于多个特征映射进行检测。但是低层并不用于目标检测,原因是这些层的分辨率虽然很高,但语义不够强,因此,为了避免显著的速度下降,目标检测时不使用这些层。因为SSD检测时仅使用高层,所以在小目标上的表现要差很多。它的结构如下图所示。
SSD结构
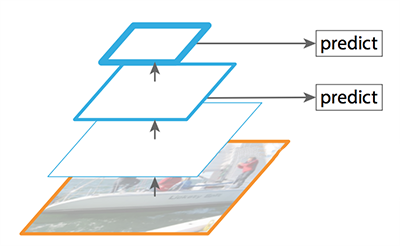
而FPN提供了自顶向下的路径,基于语义较丰富的层从上向下来构建分辨率较高的层。如下图所示。
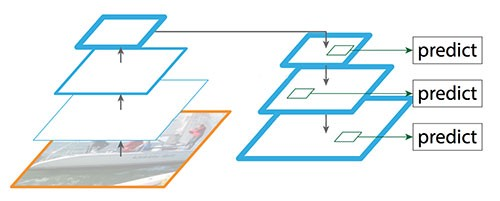
FPN自顶向下的路径(不含skip connection)
虽然重建的层语义足够强,但经过这些下采样和上采样之后,目标的位置不再准确了。因此FPN在重建层和相应的特征映射间增加了横向连接,以帮助检测器更好地预测位置。这些横向连接同时起到了跳跃连接(skip connection)的作用(类似残差网络的做法),如下图所示。
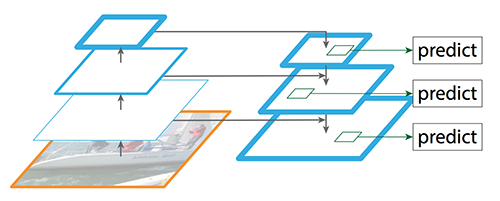
增加skip connection
接下来我们详细介绍FPN的自顶向下和自底向上路径。
自底向上路径
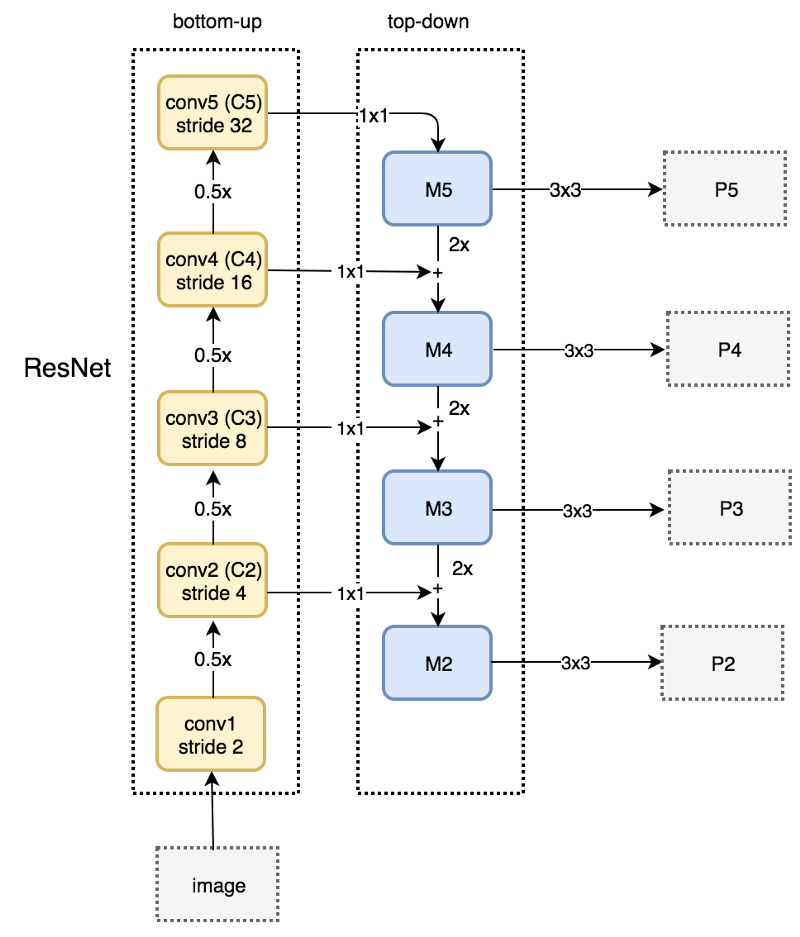
文章使用残差网络来构建自底向上的路径。这个网络由很多卷积层组成,我们把大小相同的分成一组,共计有五组,相邻组之间大小减半,从下往上我们把每一组最后一层记为C1-C5。如下图左边的虚线框所示。
增加skip connection
自顶向下路径
如上图右边的虚线框所示,FPN使用一个1x1的卷积过滤器将C5(最上面的卷积模块)的channel数降至256维,得到M5。接着应用一个3x3的卷积得到P5,P5正是用于目标预测的第一个特征映射。
沿着自顶向下的路径往下,FPN对之前的层应用最近邻上采样使得空间分辨率翻倍。同时,FPN对自底向上通路中的相应特征映射应用1x1卷积,并把它加到上采样的结果里(skip-connection)。最后同样用3x3卷积得到目标检测的特征映射,这有助于减轻了上采样的混叠效应。
我们重复上面的过程得到P3和P2,我们没有生成P1,因为它的尺寸太多,会严重影响速度。因为所有的P2-P5会共享目标检测的分类器和Bounding box回归模型,所以要求它们的channel数都是256。
FPN用于RPN
FPN自身并不是目标检测器,而只是一个配合目标检测器使用的特征提取器。我们可以使用FPN提取多层特征映射后将它传给RPN(基于卷积和anchor的目标检测器)检测目标。RPN在特征映射上应用3x3卷积,之后在为分类预测和bounding box回归分别应用1x1卷积。这些3x3和1x1卷积层称为RPN头(head)。其他特征映射应用同样的RPN头,如下图所示。
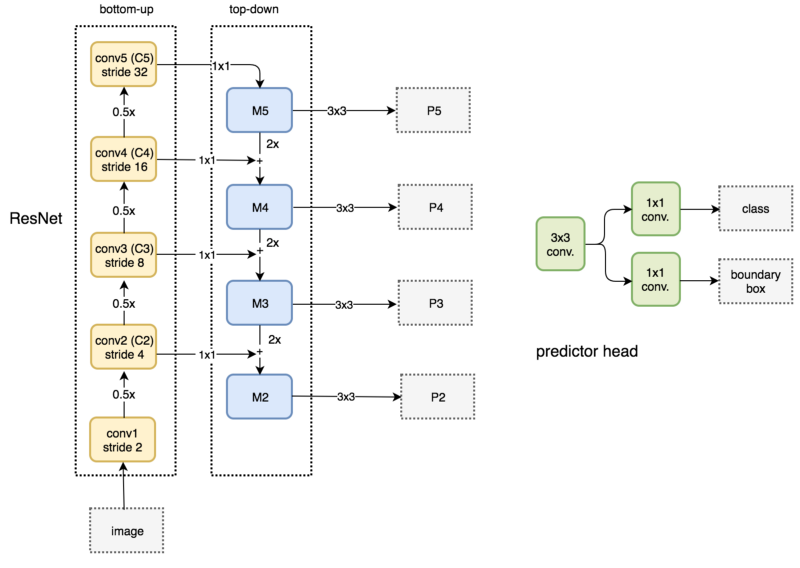
FPN用于RPN
下面我们来详细分析FPN怎么集成到我们之间介绍过的Faster R-CNN里。
FPN用于Faster R-CNN
我们首先来回顾一下Fast R-CNN,如下图所示,输入一张图片,我们首先使用卷积网络(通常叫作backbone)来提取特征,得到一组特征映射。然后使用Region Proposal选择出一些(图中是3个)可能的候选区域,然后根据候选区域的位置从特征映射中选择对应区域的特征。因为候选区域大小不一,所以使用RoI Pooling的技巧把它们都变成相同的大小,然后在接一些网络层来实现分类和Bounding box回归。
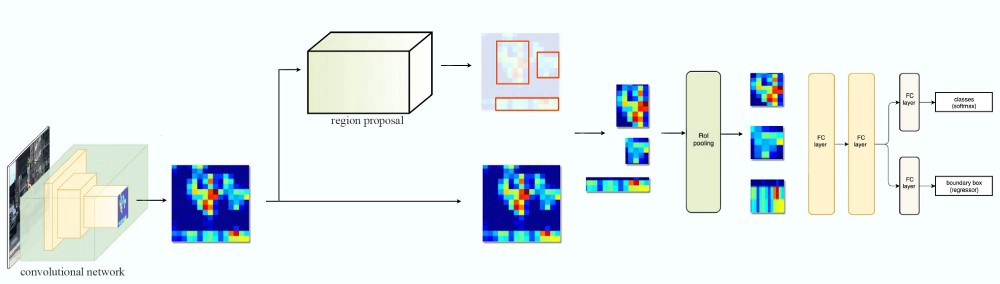
Fast R-CNN
如果是Faster R-CNN的话,结构和Fast R-CNN类似,只是把Region Proposal用一个RPN网络来代替,而且Bounding box回归也由它来完成,其余都是类似的。那现在怎么把FPN集成近Faster R-CNN呢?
如下图所示,我们首先用FPN提取特征,和之前不同,FPN产生的是多个(更准确的说应该是多组)特征映射,代表同一幅图的不同尺度。这些特征映射输入RPN网络来产生候选的区域,这都没有什么不同。有了候选区域,我们需要从特征映射里选择对应的区域,这就有所不同了。前面只有一组特征映射,所以所有的候选区域都是从这组特征映射的对应位置产生。而现在有了多个不同尺度的特征映射,就可以根据候选区域的大小选择合适的尺度了,基本的原则就是候选区域越大,我们就应该选择越高层的特征映射。具体的计算公式为:
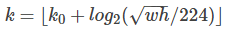
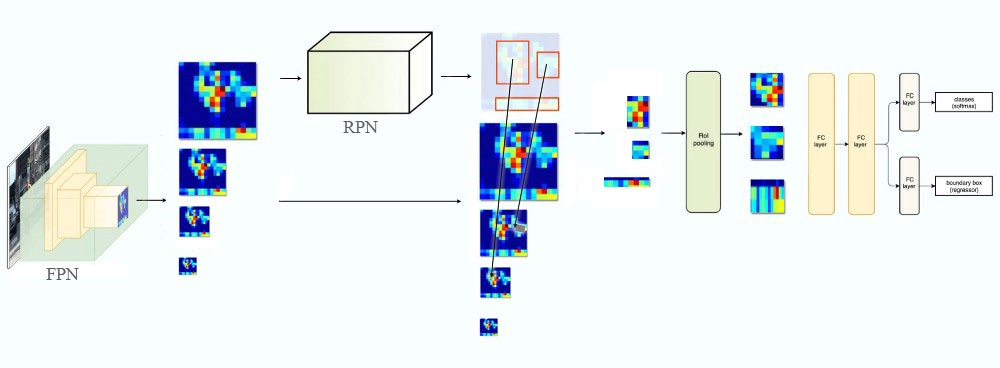
FPN用于Faster R-CNN
实验结果
FPN搭配RPN,提升AR到56.3,相比RPN的baseline提高了8%。 在小目标上的更是提高12.9%。如下表所示。

实验结果


图像影音设计相关的软件
凡科快图
- 4.5
(95)咨询产品免费试用墨刀
- 3.9
(423)咨询产品免费试用Pixso
- 3.9
(22)咨询产品免费试用



大厂都在用的图像影音设计软件
蓝湖
- 4.0
(584)咨询产品免费试用Canva可画
- 4.0
(206)咨询产品免费试用字魂
- 4.5
(20)咨询产品免费试用



限时免费的图像影音设计软件
Dprox创意3D视频
- 5.0
(1)咨询产品免费试用万兴喵影
- 3.9
(31)咨询产品免费试用易企秀
- 3.8
(260)咨询产品免费试用



新锐产品推荐
EQS企业合规平台
- 0.0
(0)咨询产品免费试用工资哥算薪平台
- 3.9
(8)咨询产品免费试用璞华易研PLM
- 0.0
(0)咨询产品免费试用璞华易投(股权投资管理系统)
- 0.0
(0)咨询产品免费试用传信
- 3.8
(2)咨询产品免费试用传信即时通讯
- 4.0
(1)咨询产品免费试用







