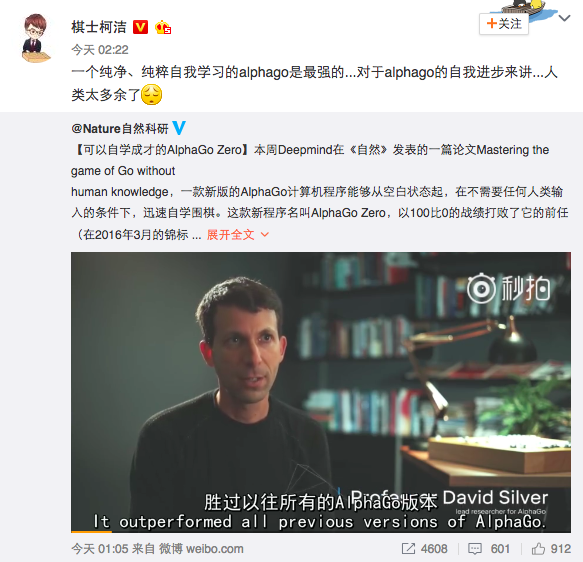
"最强版AlphaGo"100比0完虐前代 柯洁:人类太多余了
今日凌晨(伦敦时间10月18日18:00),DeepMind公布了AlphaGo的最新升级版本AlphaGo Zero,并于最新一期的《自然》杂志上,对其使用的相应技术做出详解。
DeepMind称,“AlphaGo Zero与AlphaGo最大的不同是做到了真正的自我学习,经过3天的训练,就以100:0的战绩完胜前代AlphaGo。”
除了夜猫子们第一时间看到了这则消息外,曾与AlphaGo有过交战的柯洁也在第一时间做出回应,柯洁表示,“对于AlphaGo的自我进步来讲...人类太多余了”。
今年5月,在乌镇举办的围棋峰会上,世界排名第一的柯洁不敌AlphaGo,最终以0:3告负。随后,AlphaGo宣布退役,不再与人类下棋,DeepMind则表示,将在今年晚些时候公布AlphaGo的技术细节。
那么,究竟这次的AlphaGo Zero相较此前的版本有哪些提升呢?(划重点啦)
1.AlphaGo Zero通过与自己不断挑战来进行提升,不依赖人类数据。此前版本则是通过分析海量棋谱数据进行学习。AlphaGo打败李世石用了3000万盘比赛作为训练数据,而AlphaGo Zero仅用了490万盘比赛数据。经过3天的训练,AlphaGo Zero以100:0的战绩完胜AlphaGo。并且只用了1台机器和4个TPU,而李世石版AlphaGo则用了48个TPU。
2.AlphaGo Zero只使用围棋棋盘上的黑子和白子作为输入,而上一版本的AlphaGo的输入包含了少量人工设计的特征。
3.AlphaGo Zero 不使用“走子演算”,它依赖于高质量的神经网络来评估落子位置。其它围棋程序使用的快速、随机游戏,用来预测哪一方将从当前的棋局中获胜。
4.在训练过程中,AlphaGo Zero每下一步需要思考的时间是0.4秒。相比之前的版本,仅使用了单一的神经网络。
5.AlphaGo Zero采用的是人工神经网络。这种网络可以计算出下一步走棋的可能性,估算出下棋选手赢的概率。随后根据计算,AlphaGo Zero会选择最大概率赢的一步去下。
DeepMind联合创始人兼CEO哈萨比斯称:“AlphaGo Zero是我们项目中最强大的版本,它展示了我们在更少的计算能力,而且完全不使用人类数据的情况下可以取得如此大的进展。”
2014年谷歌以4亿英镑的价格收购英国人工智能公司DeepMind。2016年,谷歌旗下的DeepMind团队发布AlphaGo,并在以4:1的成绩击败李世石后,名声大噪。
相较于研究成果的闪耀,DeepMind在研究费用上的投入也是惊人的。据英国政府此前发布的资料显示,DeepMind仅去年一年就亏损了1.62亿美元。对此,DeepMind则表示,“我们会继续向自己的科学使命投资,与世界上最聪明的人合作,解决社会上最复杂的问题。”


图像影音设计相关的软件
凡科快图
- 4.5
(95)咨询产品免费试用墨刀
- 3.9
(423)咨询产品免费试用Pixso
- 3.9
(22)咨询产品免费试用



行业专家共同推荐的软件
蓝湖
- 4.0
(584)咨询产品免费试用Canva可画
- 4.0
(206)咨询产品免费试用字魂
- 4.5
(20)咨询产品免费试用



限时免费的图像影音设计软件
Dprox创意3D视频
- 5.0
(1)咨询产品免费试用万兴喵影
- 3.9
(31)咨询产品免费试用易企秀
- 3.8
(260)咨询产品免费试用



新锐产品推荐
e企学-在线学习平台
- 0.0
(0)咨询产品免费试用U校园智慧教学云平台
- 0.0
(0)咨询产品免费试用Utalk-视听实训智慧学习平台
- 0.0
(0)咨询产品免费试用有你智居-智慧物业
- 0.0
(0)咨询产品免费试用有你智居-智能家居管理系统
- 0.0
(0)咨询产品免费试用游天地API
- 3.4
(14)咨询产品免费试用