腾讯系阅读APP的深度学习方法论
本文来自 「AI前线」,作者 | 孙子荀,编辑 | vincent
AI 前线导语:”2018年1月15日,微信创始人张小龙在微信公开课的演讲中提到了有关微信公众号的一些改变,包括公众号将会拥有自己的独立App。自微信公众号推出以来,就立刻成为了媒体人的宠儿,尤其在技术领域,对于技术人来说,一个靠谱的技术类公众号不仅是阅读的平台,更是学习和进步的阶梯。在AI迎来巨大发展的今天,本文将为你揭秘新媒体平台如何利用深度学习提供更加丰富的个性化阅读体验?”
 大家好,我是来自腾讯的孙子荀。今天我主要以落地实践为主,分享一下新媒体中的深度学习。
大家好,我是来自腾讯的孙子荀。今天我主要以落地实践为主,分享一下新媒体中的深度学习。
新媒体大家都知道,从网易到腾讯、今日头条、一点资讯,基本上大家大把的时间都花在这些阅读 APP 上。阅读 APP 为什么会火起来?可能更多的是因为以前的传统媒体往新媒体方向发展,变成有图文、视频、直播,还有自媒体的表现形式,还有个性化的推荐技术,使它做到了千人千面。我们这里主要介绍一下我们腾讯手 Q 上的一款新媒体产品在这方面的一些经验,主要把跟深度学习相关的方面抽取出来,可能不太涉及工程或其他方面。
随着深度学习技术的发展,个性化阅读领域的媒体内容有了更加丰富的处理手段。在过去主要是基于机器学习技术来进行内容分类、主题建模等。现在有了更加丰富的技术手段对于视频图片等富媒体内容进行建模处理。 本次演讲主要介绍如何应用深度学习技术帮助媒体提高内容的质量、点击率以及如何为新媒体内容运营提供帮助,包括如下内容: 媒体标题与内容关联分析、评论的情感分析、自动评论等; 图像分类与检索、语义提取; 帮助媒体选图的个性化热点区域识别技术; 图片的画风和场景识别技术应用。
阅读类 APP:把合适的内容,推送给合适的用户
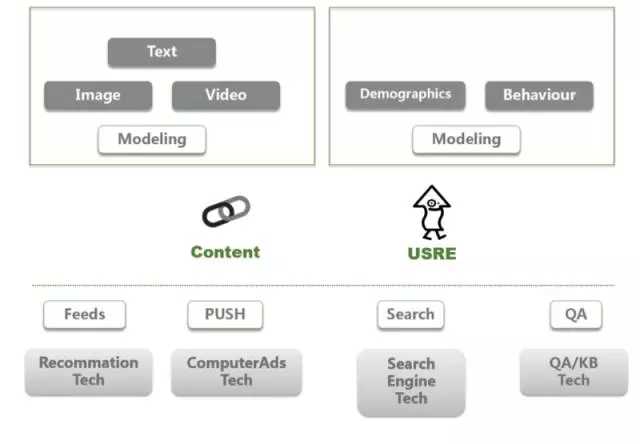 首先这种阅读类的 APP 都做了什么?比如说你自己创业要搞一个 APP,首先一定要有内容,内容可能是文本的,图像或者视频的,然后你要对它建模,文本建模、分类、清洗,图像建模、分类、抽取,视频也是一样。然后是用户,作为一个新媒体,阅读 APP 需要做的事情就是把合适的内容,推送给合适的用户,如果做过广告的就会比较熟悉。涉及到用户的话,有一些对用户进行基本建模的东西,比如说人口属性,就是我们讲的年龄、地域、性别、学历等,还有用户的实时的行为,浏览的行为、浏览的记录、在你平台上所打的标签,这都是对人的建模,是做 APP 必须要做的东西。
首先这种阅读类的 APP 都做了什么?比如说你自己创业要搞一个 APP,首先一定要有内容,内容可能是文本的,图像或者视频的,然后你要对它建模,文本建模、分类、清洗,图像建模、分类、抽取,视频也是一样。然后是用户,作为一个新媒体,阅读 APP 需要做的事情就是把合适的内容,推送给合适的用户,如果做过广告的就会比较熟悉。涉及到用户的话,有一些对用户进行基本建模的东西,比如说人口属性,就是我们讲的年龄、地域、性别、学历等,还有用户的实时的行为,浏览的行为、浏览的记录、在你平台上所打的标签,这都是对人的建模,是做 APP 必须要做的东西。
其次阅读类 APP 关联在哪些场景?比如说大家知道像 facebook 大部分推送内容是通过 feeds,这个涉及到推荐技术,就可以把内容跟用户关联起来,用户主动刷 feeds 的时候,实际上就会不断的给你推荐新的东西。第二个是 push,跟它相关的是 ComputerAds Tech,计算机广告学。计算机广告学最近比较火,在前两年的时候有成体系的书籍,我在百度做过这方面的工作,这一块也涉及到非常大的一个体系,包括在线的广告跟合约广告。Push 就是我挑一个内容主动给用户,这是一个主动的模式。Search,用户主动搜索内容,它跟普通的搜索引擎有区别,这里面有个性化的推荐,以阅读内容为主。后面的 QA,有一些公司做的 chatbot,我们也在做这一块,今天不太会涉及这个,因为我们也在摸索中,主要涉及到一些 QA 或者 KB 的一些技术。
 如何选择合适的推送时间?这需要跟特定的用户关联起来。还有 feeds,如何给用户推荐图像,就是图像的推荐是比较难做的,因为图像本身如果没有文字描述,你怎么去推荐?里面有很多的 feature 需要抽取。还有内容,内容怎么建模,怎么去评价一篇文章或者一个媒体内容,如何评估一个媒体内容是优质的还是劣质的。如果刷新 APP 的时候看到一些劣质内容、一些广告和一些营销性的内容、排版错乱的文章,那么用户体验就很差了。在做一些阅读 APP 的时候,要有方法对它评级。
如何选择合适的推送时间?这需要跟特定的用户关联起来。还有 feeds,如何给用户推荐图像,就是图像的推荐是比较难做的,因为图像本身如果没有文字描述,你怎么去推荐?里面有很多的 feature 需要抽取。还有内容,内容怎么建模,怎么去评价一篇文章或者一个媒体内容,如何评估一个媒体内容是优质的还是劣质的。如果刷新 APP 的时候看到一些劣质内容、一些广告和一些营销性的内容、排版错乱的文章,那么用户体验就很差了。在做一些阅读 APP 的时候,要有方法对它评级。
如何选封面图片?封面图片很有意思,就是你会选择阅读 APP 推送的哪些内容?你有没有想过,你刷 feeds 的时候,推送的东西你为什么会点?你看了两样,一个是标题,一个是图片,通过标题和图片就能决定会不会点进去看这篇文章,所以标题是一方面,图片是更加重要的一方面。如果在图片上面做优化,至少能够提高 25% 以上的阅读量。
如何推送
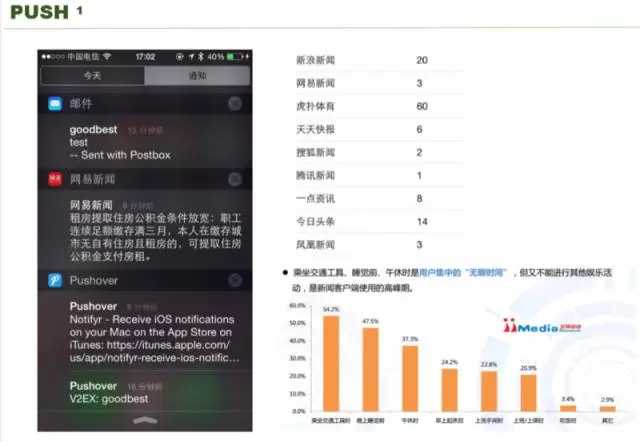
推送使用的技术和深度学习相关,但是我们发现传统的统计技术在这里比深度学习技术更好用。我们有两个同学同时做,一个是用深度学习,一个用传统的统计学技术,发现传统的统计学技术要比深度学习好很多。右边是我列了一下我朋友收到的 push 的数量,大家可以看到这种个性化 APP 推送的非常多,像国内很多的产品,通过 push 的打开率有 43%,新用户主动进去的场景下,43% 是通过 push 进去的,所以 push 是非常重要的。
我们知道像广告,有两种广告,一种在线广告,就是页面上会出现上下文式的广告,还有弹窗式的广告,比如说看一些视频站点的时候,会弹框、弹广告。展示类的广告跟合约式的广告其实是两种不同的技术,在合约广告里面有一个“库存预估”,根据库存来卖合同,那么怎么预估库存有多少?我一定是预估用户在这个时间打开我的视频网站,我预估出来在某个时间点,有多少用户看《甄嬛传》第三集,知道了这个数据,才能知道卖多少合同出去,所以这是非常重要的。
我们媒体类 APP,其实跟这个有点像,合约广告,它会 push 一个内容,只是它是广告,我们是新闻。Push 这个内容给用户,一个是说 push 的内容一定是个性化的,因为广告内容个性化,还有一个就是 push 的时间是不是个性化的,不是运营的 push,运营的一个重大实时事件,那是运营类。个性话的 push 是指你现在应该看一些内容,然后给你 push 个性化的内容,这个时间要去分析一下。
这是艾媒传媒公开的数据,用户什么时候使用 APP,乘坐交通工具、睡觉前、午休、上洗手间的时候,这里问题就是每个人的时间都不一样,你怎么做到将每个人 push 的时间都千人千面呢?
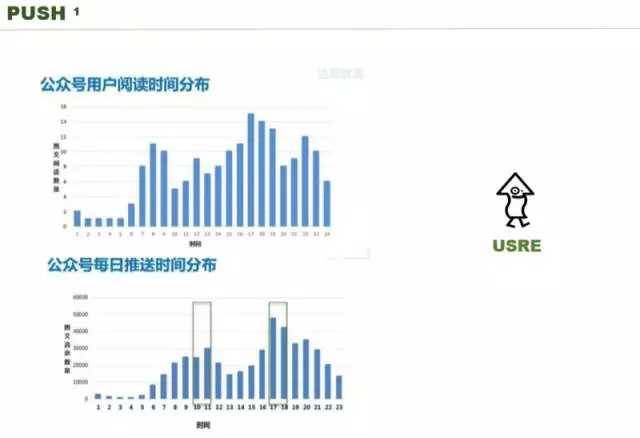
我们看一下,这是微信的公开数据,上面是公众号用户阅读时间分布,每个时间点用户阅读文章数量,下面是我们腾讯的公众号每日 push 的时间。微信公众号每天 push 时间集中在 10 点 12 点,下午在 17 点到 18 点,这是公众号所有人自己上班时间吗,不是,这是摸索出来微信用户的习惯是这样。微信用户在这两个时间点比较活跃,所以他选择两个比较保守的时间进行 push。
如果选一个时间,你大概选 17-18 点,两个时间,肯定选早上。如果三个时间呢?这张图表你选三个时间,你怎么选,选不了。四个五个呢?一个 APP 给用户 push 的内容不是越多越好,如果用户反感,你就不要 push 了。现在就有这么多的 environment,你在合适的时候 push 一个,并不反感。我们怎么得到这个数据呢,一个用户 push 多少次、什么时间 push,这都是我们需要解决的问题。
 这里需要引入一个模型,就是我们之前在学习的时候不知道 push 几次,什么时间 push,这个可能 deep learning 并不能很好的告诉我们。我们假设一个场景,一个学生,这个学生每天使用手机的一个集中时间段是哪里?可能是早上起来,如果他觉得课无聊的会刷一下,中午刷一下,下午他大把的时间他会刷,他社交娱乐的时候就不刷了,这是学生。上班族肯定是早上刷、中午刷,下午忙工作,晚上一直在刷,这是上班族。这几类人都是不同的画像,怎么获取每个人会有几个频繁刷的中心点,他们有大半的时间刷这个东西,只要刷手机的中心点 push 就可以了,因为他们不会反感,不要在学生上课,上班族开会的时候给他 push。
这里需要引入一个模型,就是我们之前在学习的时候不知道 push 几次,什么时间 push,这个可能 deep learning 并不能很好的告诉我们。我们假设一个场景,一个学生,这个学生每天使用手机的一个集中时间段是哪里?可能是早上起来,如果他觉得课无聊的会刷一下,中午刷一下,下午他大把的时间他会刷,他社交娱乐的时候就不刷了,这是学生。上班族肯定是早上刷、中午刷,下午忙工作,晚上一直在刷,这是上班族。这几类人都是不同的画像,怎么获取每个人会有几个频繁刷的中心点,他们有大半的时间刷这个东西,只要刷手机的中心点 push 就可以了,因为他们不会反感,不要在学生上课,上班族开会的时候给他 push。
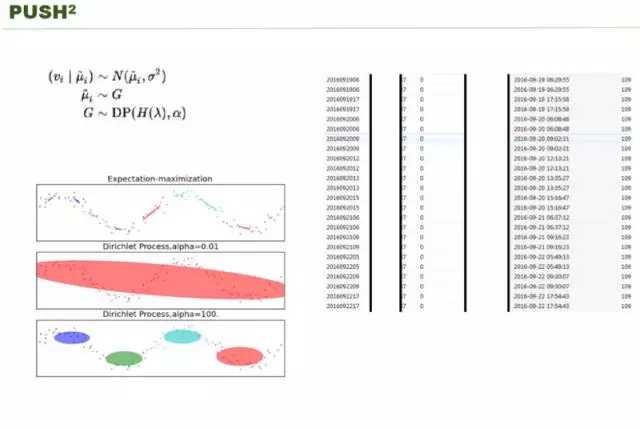
你怎么通过用户的历史行为得到它这几个时间点?刚才我举了两个 case,有的人可能是说我一天刷三次,有人刷六次,有人刷七次,如果你要通过传统的聚类技术来做的话,普通的聚类技术必须实现设定好 K 是多少,要聚多少类,一定要设定好,不同用户其实 K 是不一样的。我们一开始把所有的数据送到 deep learning,让它给我们选 K,但是我们发现基本上都会过拟合。很多同学可能用过 LDA,LDA 比较好的地方是其中用到了共轭,它二项式分布跟狄利克雷的分布过程是共轭的。
狄利克雷过程是不需要你指定 K 是多少,这个过程是说你只要指定一个参数,通过这个参数就可以告诉你,在这个参数的情况下,它是趋近于产生多个类别,或者趋近产生少的类别。如果是一个参数,看我们最上面的图。如果你α是 0.01 就是一个类,如果设置成 100 或者更多的话,就会把你的类分的越多。如果一个 APP 推两次,设小一点,推四次,设大一点,就可以帮你自动产生类别。我们看右边的图。这是腾讯收集的用户打开 APP 的数据,把 QQ 和微信的时间合并起来,19 号 -27 号打开腾讯 APP 的数据,怎么从中学出它的类别,就是直接用 Dirichlet Process 就可以了。
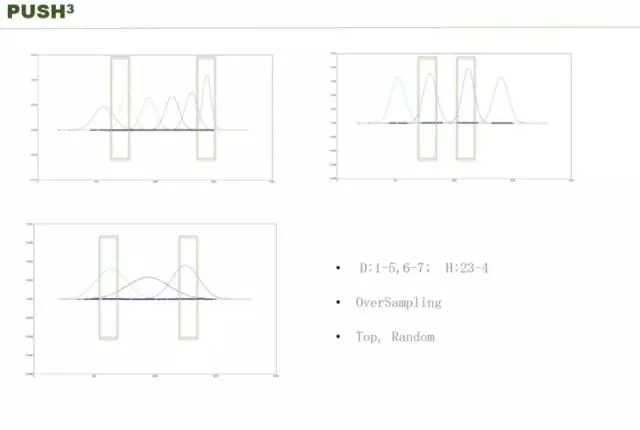
最终取得的效果,左上角是上海在校的一个男生,右上角是在校的女生,左下角是腾讯的项目经理,如果都推两次,怎么分?我们通过一些技术,取 1-5 天,6-7 天分别做,将 23 点和凌晨 4 点的数据连起来,通过过采样的技术和一些其他的方式得到了这张曲线,图上,越高说明这个时间点使用行为越密集,这么基本上得到这么几个结果。在同样的参数情况下,男同学每天刷手机非常之多,他在晚上有一个高峰,右上角的女生,刷的比较平均,腾讯的同事只是早上跟晚上,中午基本上很少刷,这样就可以选出给用户 push 的时间,你作为一个媒体的 APP 你可以选择 push 的时间,而不是所有的用户统一的时间。
如何选择和展示封面图片
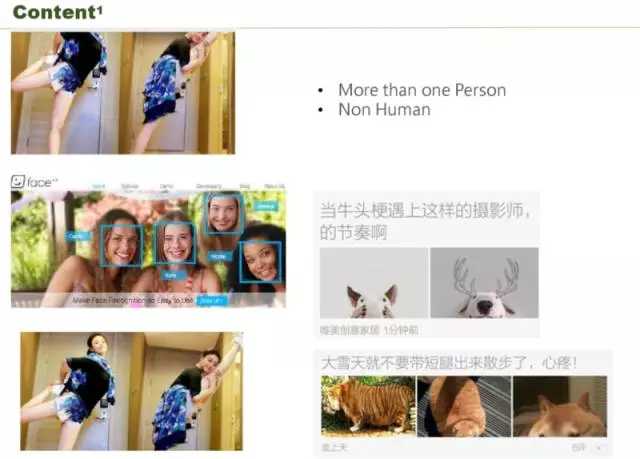
图片会影响文章的点击率。左上角是一个明星,这是我们竞品的效果,把明星的头截掉了,在 APP 展示的时候没有显示出头像,这种图大部分用户都不愿意去点,因为眼睛都没有,不知道是谁。这种可以通过什么方式解决呢?通过人脸识别可以解决,人脸库识别出来,就可以解决了,形成了左下的图。如果是多个人呢?每个角落都是人,大合影,人脸识别就选不出来了。第二个如果不是人呢?你看右边这个狗,这是它实际截的两个图,你可以看到狗都没有截出来,左下是一个动物也没有截出来,右边的秋田犬也只露出一个头,眼睛没有,这种文章你基本不会点。
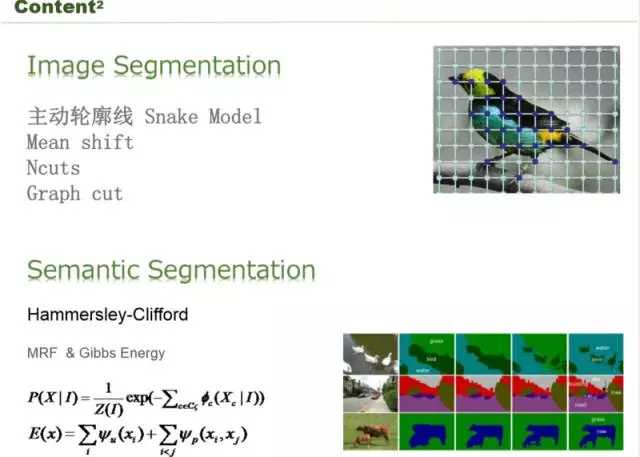
那么怎么通过一个合理的方式把图片选出来呢?我们主要从以下两点考虑这个问题,第一个首先我们类别一定要全,包括人、各种重要的物体、食物、动物、风景等要全,第二个识别重点的区别,画面上比较重点的区域,这个在传统的技术上,像图像分割做的比较好,像 Snake Model、Mean shift、Ncuts、Graph cut 等一些图象分割的技术把这个鸟分割出来,这是传统的一些方式。
进入了深度学习之后有一个语义切割,深度学习让语义分割变得更加的精确,整个指标都有很大的提升。右下有很多的鸭子,你截图会对着鸭子截,而不是对着湖面截。这里涉及到一个 deep learning 的技术,能把图像分割出来,然后把物体识别出来,这样就可以进行截图。这里首先识别出物体,caffe 肯定是可以帮你识别出物体。第二个要识别出轮廓,这两个结合起来,就帮你做一些事情。我们就是这样做的,用传统的技术识别轮廓,再用机器学习技术识别轮廓对应的物体,然后通过 end-to-end 端到端的训练得到了所关注的物体,这样的话对刚才的一些图片基本上都能得到很好的解决。国外很多技术都是通过这个方式解决的,可复用性很高。
内容评级
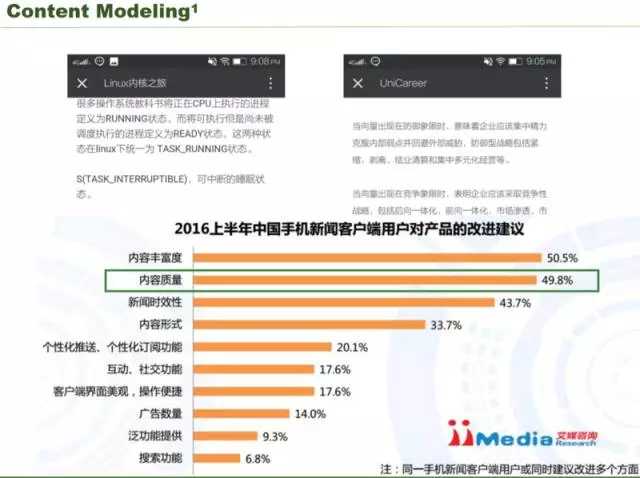
媒体的内容,我们希望看到的是更多比较高质量的内容。我们看这两个内容,左边是技术类,右边是金融方面的文章,从排版和格式来看,大家更愿意阅读哪一个?更愿意阅读第二个。左边虽然是技术方面的,右边的给你阅读感受更好,所以它的质量是更高的,这里需要给内容进行评级。这里艾媒传媒的一个数据,2016 年中国手机新闻客户段用户对产品的改进建议,其中内容质量占比很高,有接近一半的用户他觉得 app 的内容质量非常低,经常给他推送一些质量低的内容。
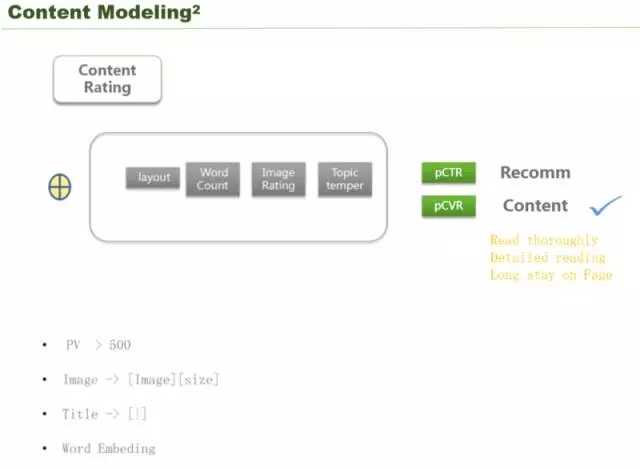
腾讯怎么解决的,就是将内容进行分级,把内容分为五档,或者六档、七档,这就是分类的问题,分类的问题通过深度网络解决。这里需要传入的一些特征,包括布局、字数、图片的质量、话题的火热程度。那么右边的评价指标到底是选点击率,还是阅读完成率?评价一篇文章的质量,一定是用户花在上面的时间比较多,用户越愿意完成这篇阅读,它的质量越高,也就是深度阅读、沉浸式阅读。如果一个文章点进去就跳出去了,点击率高有什么用呢?说明标题和图片很好,但是里面的内容没有阅读的欲望,这就不能说内容的质量很高。评价内容的质量,你最终拟合到的目标函数一定是阅读完成率。
怎么学习出一个文章的阅读完成率呢?首先采样的时候,因为我们跟用户无关,希望这个我们选的内容跟用户没有任何关系,因为我们要抛去个性化推荐的问题。我们这里只关注内容的建模,PV 大于 500,这样可以帮你洗去很多异常因素,图像、标题做变换,把图像和标题作为占位符,然后对 word 做一个 word embeding。
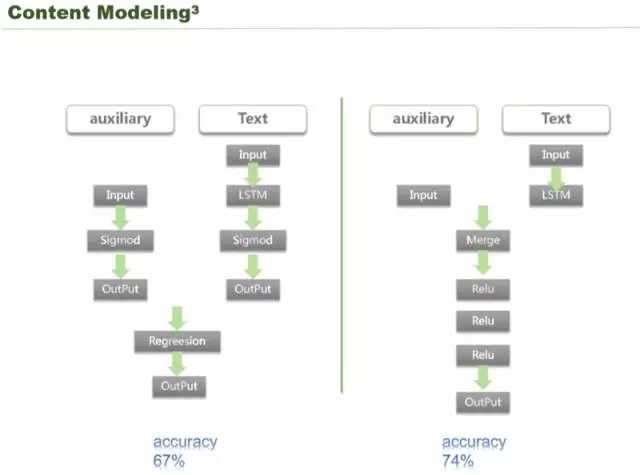
这里又有两个技术,左边是页面的布局、字数、话题热度的信息,还有一些是文本本来的一些描述信息,就是文本的内容的一些信息。这两个信息放到一个网络中很难学出来,因为一个神经网络去学文字特征的时候,比如对所有的 word embeding 都可以,但是像排版布局并不是文字,没有办法同时的做 training,这时候有两个选择,附属的信息用一个模型圈定出来,再把文字的信息用 deep learning、LSTM 圈定出来,圈定出来之后,把这两个输出做一个 regression,就把这两个模型放在一起,这是一个方式。
一开始我们这么做的,最后发现我们的准确率只有 67%,说明效果不太好。后面就是把原来的固有信息和文本信息做一个融合,做一个同样的网络,这样整个网络就是 end-to-end,深度学习有一个前向反馈和后向反馈,可以同时同步调整两个网络参数,最后实现的准确率是 74%,这个效果非常好。直接用 kores 深度学习网络框架就可以把传统的一些特征跟文本的特征放在一起进行圈定。
图片推荐
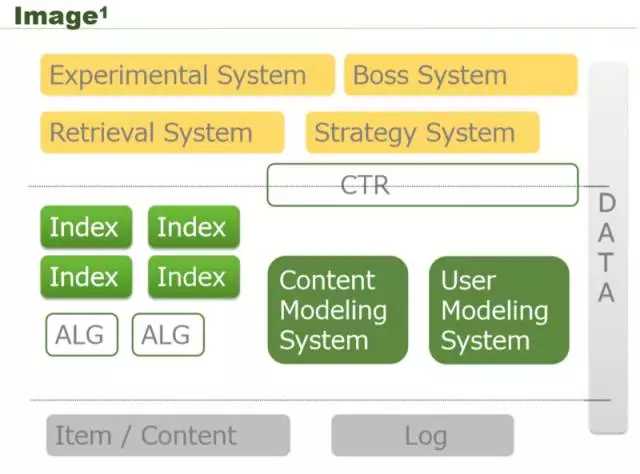
图片的推荐是一个比较宽泛的推荐系统结构,图中黄色部分就是在线服务的实验检索系统,最下面是它的内容和一些流水日志,然后中间是内容建模、用户建模,我们这里最关注的是绿色的部分,就是一个推荐引擎想给用户做推荐,肯定不是一个推荐,比如说有协同固定推荐、兴趣推荐、点击率预估推荐,这些肯定不是一个推荐引擎就够的,因为一个推荐引擎没法做到多样性,所以需要多个推荐引擎并行工作。业内今日头条有 300 多个推荐引擎同时工作,通过流量系统去分流量。如果是图片的话,更多的是关注怎么将图片从底层的 content 检索出来,因为图片没有太多的文字信息,那怎么通过图片检索出相关的文章,相关的内容呢?
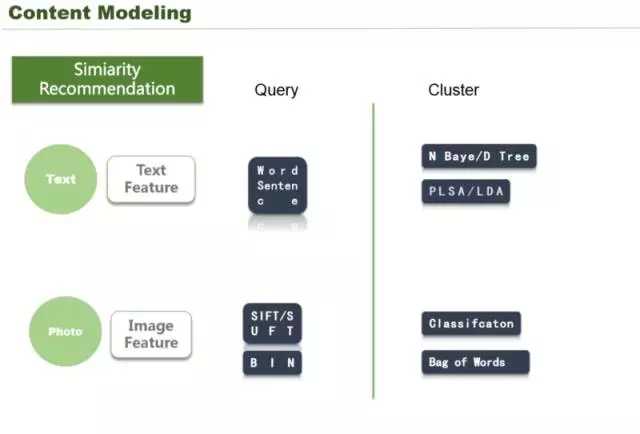
这里我们看一下在文本怎么做的。文本特征可以做 query,可以用字、句做搜索引擎。图像的话,传统的图像有一些算子比如 SIFT,也可以用 query,还有一些可以通过聚类的方式,PLSA 把文章进行聚类,它需要一些特征,还可以通过图片,也是类似通过前面说的一些特征做一些分类技术,这样可以做到一个召回,我这张图的 index,这其实都是可以召回的。
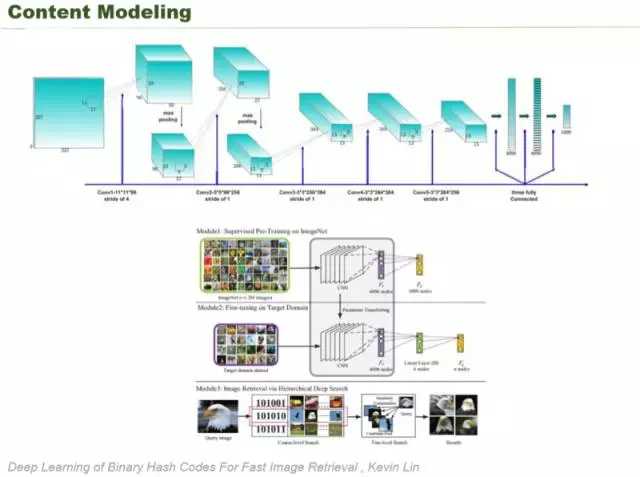
深度学习的时候,有了图象描述的 feature 可能还不够。左下角是这篇 paper 的题目,他们在原来的经典的 AlexNet 网络的基础上多加了一层,把这一层专门用于图片的召回检索,如果不加一层直接进行检索问题也不大。我们发现这里加了一层更适合搜索引擎,比如说搜范冰冰就会出来范冰冰,搜一个鸟,就会推荐一个同类型的鸟。当然这不是推荐引擎,这有点类似于搜索引擎的以图搜图,都是一些细节的东西。
我们在检索的时候,采用两种模型,一种就是我们对 object 搭建了一个 CNN 网络,对 style 也搭建了一个 CNN 网络,不同 CNN 网络做不同的事情,一个识别物体,一个识别画风。
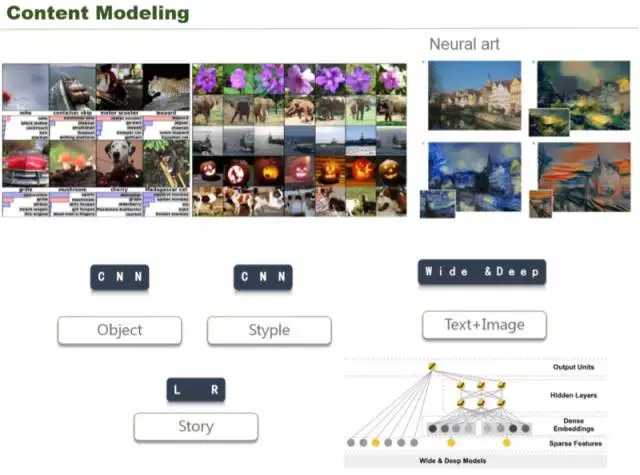
画风,就是类似右上的梵高的画,识别画面风格的 CNN 是不一样的,因为在训练 CNN 的时候,神经元权重不一样,这是两件事情。比如说给用户检索出一个风景的时候,它一定是风景,同时它的画风类似,拍摄手法类似。我们分了两个 CNN 来做,我们把这两个 CNN 网络 LR 之后,形成一个 story,这就是更高层次的抽象,比如心情,类似激动。给用户推送阅读,应该避免推荐惊悚的,我们通过两个模型做一个 LR 融合,形成一个 story,我们会把所有惊悚的 story 帮用户过滤掉。
这是检索的时候,除了刚才说的 object 的检索、style 的检索,还有两个融合起来 story 的检索之外,因为有的内容有简单的描述,我们把文本和图象做了一个融合,就是用 tensorflow 中的 wide&deep 网络,把传统的一些特征,比如说像文本的或者说用户的一些阅读兴趣的特征,还有无关的网络合在一起进行一些检索,或者进行一些圈定。这里其实就做了四个 index(object/style/story/text、image),最后实现了一个图片的推荐。我们可以跟用户推荐它更感兴趣的图片。
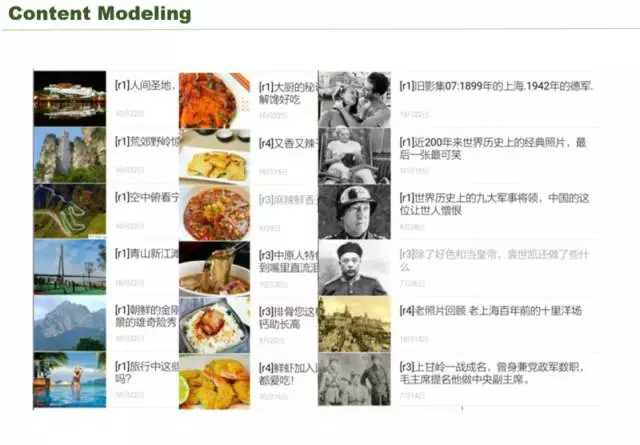
这是我们的效果,左边是一些风景,基本上都是同一类风景,同样的山水蓝天。中间喜欢吃辣的用户,push 的都是这些辣的。后面的是老照片,点进去都是上海老照片,这种的图片跟用户的关联性更大。单从文本来说,作为短的文本很难分类,因为里面是没有什么内容,全是图片,图集,第二个短文本分类会有很大的问题。
作者介绍
孙子荀,09 年毕业后从事内核和分布式系统的开发工作,11 年在百度从事过高性能计算方面的工作。12 年加入腾讯,从事 QQ 群广告系统的开发,随后负责腾讯云加速的带宽调度系统的设计研发,获得公司多个业务奖项。14 年开始手 Q 公众号项目,负责构建公众号平台和内容平台。现在从事个性化阅读内容方面的处理和挖掘工作。
更多干货内容,可关注AI前线,ID:ai-front,后台回复「AI」、「TF」、「大数据」可获得《AI前线》系列PDF迷你书和技能图谱。


新锐产品推荐
Hoo选电商
- 3.9
(8)咨询产品免费试用船长BI
- 4.5
(4)咨询产品免费试用ThingJS低代码
- 0.0
(0)咨询产品免费试用飞榴科技-针聪明
- 0.0
(0)咨询产品免费试用会否
- 0.0
(0)咨询产品免费试用101智慧课堂
- 0.0
(0)咨询产品免费试用







