谁来治好AI的「幻觉」?面对众多对抗样本攻击,深度神经网络该何去何从
编者:本文由机器之心编译,作者Tom Simonite,参与者路雪、黄小天,36氪经授权转载。
2 月 3 日,来自 MIT、UC Berkeley 的 Athalye 等人宣布其研究攻破了 ICLR 2018 大会的接收论文中的 7 篇有关防御对抗样本的研究。之前,轻微扰动导致停车标志被无视、把熊猫认成长臂猿、把校车认成鸵鸟等等各种案例层出不穷。那么关于 AI 容易被「幻觉」干扰的现象,研究者又有什么看法?深度神经网络该何去何从?Geoffrey Hinton 的 Capsule 能够解决这一问题吗?
科技公司正在借助机器学习的强大能力,将人工智能推向世界的每个角落。但是令人激动不已的深度神经网络有一个很大的弱点:轻微变动图像、文本或语音数据就可以欺骗这些系统,造成感知误判。
这对机器学习产品是一个大问题,尤其是在视觉方面,比如自动驾驶汽车。研究人员正努力应对上述问题——但结果证明这很有难度。
案例:今年一月,人工智能顶级会议 ICLR 2018 公布了 11 篇将在 4 月份会议上展示的新论文,全部是关于如何防御或检测对抗性攻击的。仅仅在三天之后,MIT 博士生 Anish Athalye 发文称已攻破上述论文中的七篇,其中不乏大机构的论文,比如谷歌、亚马逊、斯坦福。Athalye 说:「一个有创意的攻击者总能绕过这些防御」。该项目由 Athalye 与 Nicholas Carlini、David Wagner 共同完成,后两者分别是伯克利的一名毕业生和教授。
学界对这个三人小组项目的特定细节进行了反复探讨。但有一点几乎没有异议:目前还不清楚如何保护基于深度神经网络的产品(比如消费品和自动驾驶)免受「幻觉」(hallucination)的侵袭。「所有这些系统都很脆弱,机器学习社区没有评估安全性的方法论。」Battista Biggio 说道,他是意大利卡利亚里大学的助理教授,用大约十年时间思考机器学习的安全问题。
人类读者可轻松识别 Athalye 创建的下图,图片上是两个正在滑雪的男人。但是在周四上午的测试中,谷歌的 Cloud Vision 服务却认为 91% 的概率是一只狗。类似的还有如何使停车标志不可见,或者人类认为内容良性的语音却被软件转录为「好的谷歌,浏览不良网站」(okay google, browse to evil.com)。
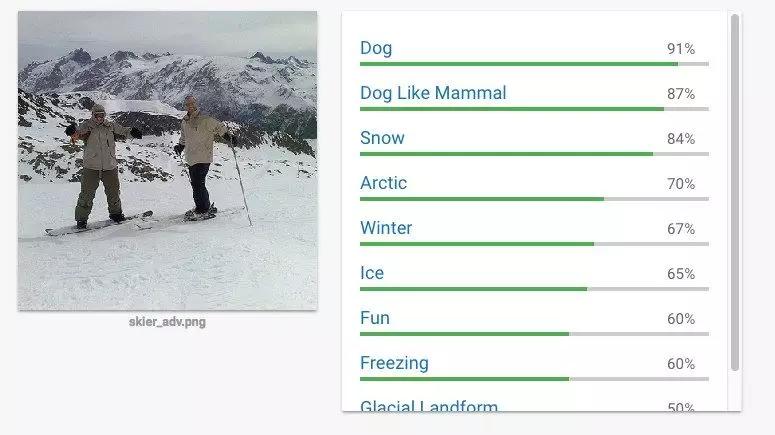
「目前,此类攻击只发生在实验室中,而没有公开测试。但是我们仍需严肃对待」,加州大学伯克利分校博士后 Bo Li 说。自动驾驶汽车的视觉系统和能够执行消费的语音助手、过滤网络不良内容的机器学习系统都必须是可靠的。「这实际上非常危险。」Li 认为,她去年参与了「在停车标志上粘贴纸从而使机器学习系统无法识别」的研究。
Athalye 及其合作者实验过的论文就包括 Li 作为共同作者撰写的一篇论文。她和加州大学伯克利分校的同仁介绍了一种分析对抗攻击的方法,该方法可用于检测对抗攻击。Li 辩证地看待 Athalye 关于防御可攻破的项目,认为此类反馈可以帮助研究者进步。「他们的攻击表明我们还需要考虑很多问题。」Li 说道。
Yang Song,Athalye 分析中涉及的一篇斯坦福研究的一作,拒绝对此进行评价,他的这篇论文仍在接受另一个重要会议的审核。Zachary Lipton,卡内基梅隆大学教授,也是另一篇论文的共同作者(作者还包括来自亚马逊的研究者),称他尚未仔细看 Athalye 的分析,但是所有现有防御可被规避是合理的。谷歌拒绝对此分析作出评价,称计划更新其 Cloud Vision 服务,以抵御此类攻击。
要想更好抵御此类攻击,机器学习研究者可能需要更加严苛。Athalye 和 Biggio 认为应该应该借鉴安防研究的实践经验,更加严谨地测试新防御技术。「机器学习研究者倾向于信任彼此,」Biggio 说道,「而安全问题恰恰相反,你必须一直对可能性保持警惕。」
上个月来自 AI 和国家安全研究者的一份报告给出了类似的建议。该报告建议机器学习研究者更多地考虑他们所创造的技术被错误使用/利用的情况。
防御对抗攻击可能对一些 AI 系统来讲较为简单。Biggio 称,用于检测恶性软件的学习系统更易增强鲁棒性,原因之一是恶性软件是功能性的,限制了其变化程度;保护计算机视觉系统更加困难,因为自然世界变化万千,图像包含那么多像素。
解决该问题(该问题对自动驾驶汽车的设计者也是一个挑战)可能需要更加彻底地反思机器学习技术。「我认为基本问题在于深度神经网络与人脑的巨大差异。」Li 说道。
人类无法对感官欺骗完全免疫。我们会被视错觉蒙蔽,谷歌近期发布的一篇论文创建了一张图像,既可以欺骗机器,也能够迷惑人类(在不到 1/10 秒时间内看到该图像的人错把猫认成了狗)。但是我们在解析图像时看到的不止是像素模式,还要考虑图像不同组件之间的关系,如人脸的特征,Li 说道。
谷歌最杰出的机器学习研究者 Geoff Hinton 试图赋予机器这种能力。他认为 capsule network 这种新方法允许机器学习从少量图像中识别物体,而不是从数千张图像种学习。Li 认为具备更接近人类视角的机器应该会更少地受到幻觉影响。她和加州大学伯克利分校的同仁已与神经学家和生物学家展开合作,尝试从大自然中获取启发。




大厂都在用的在线作图软件
包图网
- 4.2
(241)咨询产品免费试用稿定设计
- 4.0
(193)咨询产品免费试用fotor懒设计
- 4.1
(49)咨询产品免费试用



限时免费的在线作图软件
千图网
- 4.1
(293)咨询产品免费试用创客贴
- 3.9
(243)咨询产品免费试用摄图网
- 4.2
(86)咨询产品免费试用



新锐产品推荐
博优商业管理系统商贸通V6
- 0.0
(0)咨询产品免费试用博优专卖店管理系统V6
- 0.0
(0)咨询产品免费试用博优餐饮管理系统7.0
- 0.0
(0)咨询产品免费试用博优聚客-云POS
- 0.0
(0)咨询产品免费试用科橘
- 0.0
(0)咨询产品免费试用猎吧租车
- 0.0
(0)咨询产品免费试用







