DeepMind进军星际争霸2,谷歌Facebook打响通用AI战争
编者按:本文来自微信公众号“新智元”(ID:AI_era),内容来源:deepmind.com/blog 等,译者:熊笑 弗格森;36氪经授权发布。
7日,Facebook刚刚宣布开源史上最大的《星际争霸》游戏数据集STARDATA。今天(10日)DeepMind在官方博客上宣布开源星际争霸2 研究训练平台SC2LE。AI 巨头挑战星际争霸的角逐愈演愈烈。乌镇围棋峰会上,DeepMind CEO 哈萨比斯曾说,星际争霸将成为AI进步的下一个大考验。
国内AI 资深专家袁泉此前曾深入研究过星际争霸中的若干AI问题,和UCL共同发表了多智能体协作网络BiCNet,第一次展现了AI在星际微观战斗中的五类智能协作方式。新智元对此做过专门报道。此次DeepMind 和暴雪最新发布的星际争霸 2 AI开放研究平台的论文中,也多次引用了袁泉团队的工作。因此,袁老师应新智元之邀做了特别点评。他指出了此事的两点意义:
第一点:星际 2 的搜索和决策空间比 AlphaGo 围棋大了多个“数量级”,DeepMind、Facebook 等越来越多的优秀团队参与到这项研究中,很可能创造出更好的下一代AI的新技术。因为按之前玩围棋的技术框架的话,蒙特卡罗树搜索加深度强化学习,应该是不能完全解决星际中的问题,尤其是full game智能策略方面的难题。此次DeepMind和暴雪在AI开放平台、API标准化、性能架构上做了不少细致卓越的工作,为今后的研究打下了好的基础,希望国内有志于此方向的老师同学积极投入到此项研究工作中。
第二点: SC2LE 开放平台,相对于大家之前做的星际1的平台,最大的一个优势是提供了很多端到端的内容操作的接口,发展出来可以通过接口像人一样打星际,进行控制,这种接口是在之前的星际1平台上不提供的。基于这一点,未来有可能大家可以会看到机器人像人一样坐在电脑前,操作鼠标打星际和高手对决,对机器人等相关领域也是很好的促进!
DeepMind 最新发布 SC2LE,推动星际争霸 2 AI 研究
DeepMind 刚刚在博客中宣布,与合作伙伴暴雪一起,发布了一套名为 SC2LE (StarCraft II Learning Environment)的工具组件,这套工具组件将加速即时策略游戏星际争霸 2 中的 AI 研究。

星际争霸 2 是 2010 年发布的即时策略游戏
根据 DeepMind 的博客所说,SC2LE 包括:
一个由暴雪开发的机器学习 API,能够让研究者和开发者参与到游戏中来。其中还包括面向 Linux 的工具的首次发布。(GitHub 地址)



一篇 DeepMind 和暴雪的联合论文,论文对作为研究环境的星际争霸 2 进行了概述,报告了在迷你游戏上的初始基准结果,基于回放的监督式学习,以及对抗游戏 AI 的 1 v1 ladder 游戏(论文介绍见文后)。

星际争霸 2 AI 研究进一步瞄准通用人工智能和真实世界的任务
DeepMind 一向以开发能够学习解决复杂问题的 AI 系统、推进 AI 边界为使命。从设计用来研发通用人工智能和机器学习系统的第一人称视角 3D 游戏平台 DeepMind Lab ,到围棋、Atari 这样的游戏,DeepMind 一直在广阔多样的环境中设计智能体并测试其能力。
星际争霸和星际争霸 2 一直以来都位列最成功的大型游戏之中,相关比赛已经举办了 20 多年。其原始游戏就已经被 AI 和机器学习研究者所用,每年都有 AIIDE bot competition。星际争霸长盛不衰的部分原因在于其丰富、多层面的游戏过程,这也使得其成为 AI 研究的理想环境。
关于星际争霸作为 AI 研究和智能体“竞技场”的历史,可以参见这篇文章:星际AI 争霸 6 年简史:通用人工智能角斗场,DeepMind 确认应战。
实际上,早在2016年11 月,DeepMind 工程师 Oriol Vinyals 就在公司博客公布,DeepMind 将和暴雪合作,让星际争霸2 成为人工智能研究场景,并开放给所有的人工智能研究者。
Oriol Vinyals 少年时期曾是西班牙的顶级星际争霸玩家,他当时坦言,“要打败人类职业选手,机器尚有很长的路要走。
他当时在博客中写道,DeepMind 之所以选择星际争霸2作为人工智能研究的目标,是因为它的复杂性:玩家必须做出高级战略决策,同时还要控制数百个元素,并快速做出各种决定。Oriol Vinyals 认为,跟国际象棋和围棋相比,星际争霸更能模拟真实世界的混乱状况。他说:“如果要让智能体程序学会玩星际争霸,它需要有效利用记忆,还要能制定长远计划,而且能根据最新信息调整计划。”他认为,如果能开发一套机器学习系统,让它掌握操作星际争霸的技巧,这种技术将最终可以用来执行真实世界的任务。
此后,《星际争霸》的制造公司暴雪娱乐建造总监 Tim Morten 对媒体确认,AlphaGo 将挑战《星际争霸2》。
AI研究者现在可以使用开放工具构建自己的模型,来应对星际争霸的技术挑战
此次 SC2LE 的发布,无疑是 DeepMind 将之前的宣言付诸了行动。在这篇最新的博客中,DeepMind 又阐释道:
举例来说,如果游戏的目标是击败对手,游戏者必须采用并权衡一系列子目标,比如采集能源或修建建筑。另外,一局游戏的时长可能长至一小时,这意味着游戏早期采取的一些行动可能长时间得不到回报。最后,地图上有很大一部分是隐藏的,这意味着智能体必须结合其记忆力和规划能力,才能获胜。
这款游戏还有其他吸引研究者的特质,比如每天都有人数众多的狂热玩家在线比赛,这保证了训练智能体所必需的回放数据,也保证了 AI 智能体不缺有实力的对手。
星际争霸的动作候选空间里有高达 300 种基本动作可被采用,Atari 游戏则大概只有 10 种(如上、下、左、右等)。不仅如此,星际争霸中的动作还是有层次的,可以被调整和增强,其中许多都要在 screen 上占据一个 point。即使screen 尺寸只有 84x84,可选动作也约有 1 亿个。
本次发布意味着,研究者现在可以使用暴雪自己的工具来构建自己的任务和模型,来应对上述挑战了。
这次发布中的 PySC2 环境提供了灵活易用的强化学习智能体界面。在这一初始发布中,DeepMind 将游戏分解成了“feature layer”,其中诸如单位类型、血量、地图可见度这样的元素彼此是孤立的,同时也保留了游戏的核心视觉和空间元素。
AI 在迷你游戏和完整游戏中表现差异巨大
本次发布还包括了一系列迷你游戏(mini-games),这是一种将游戏分解成更可控的部分的技术,可以用于测试智能体在特定任务中的表现,例如移动视角(camera)、采矿或是选择操作单位。DeepMind 在博客中表示,希望研究者能够在这些迷你游戏上测试其技术,同时也为其他研究者提供新的迷你游戏,用以竞赛和评估。
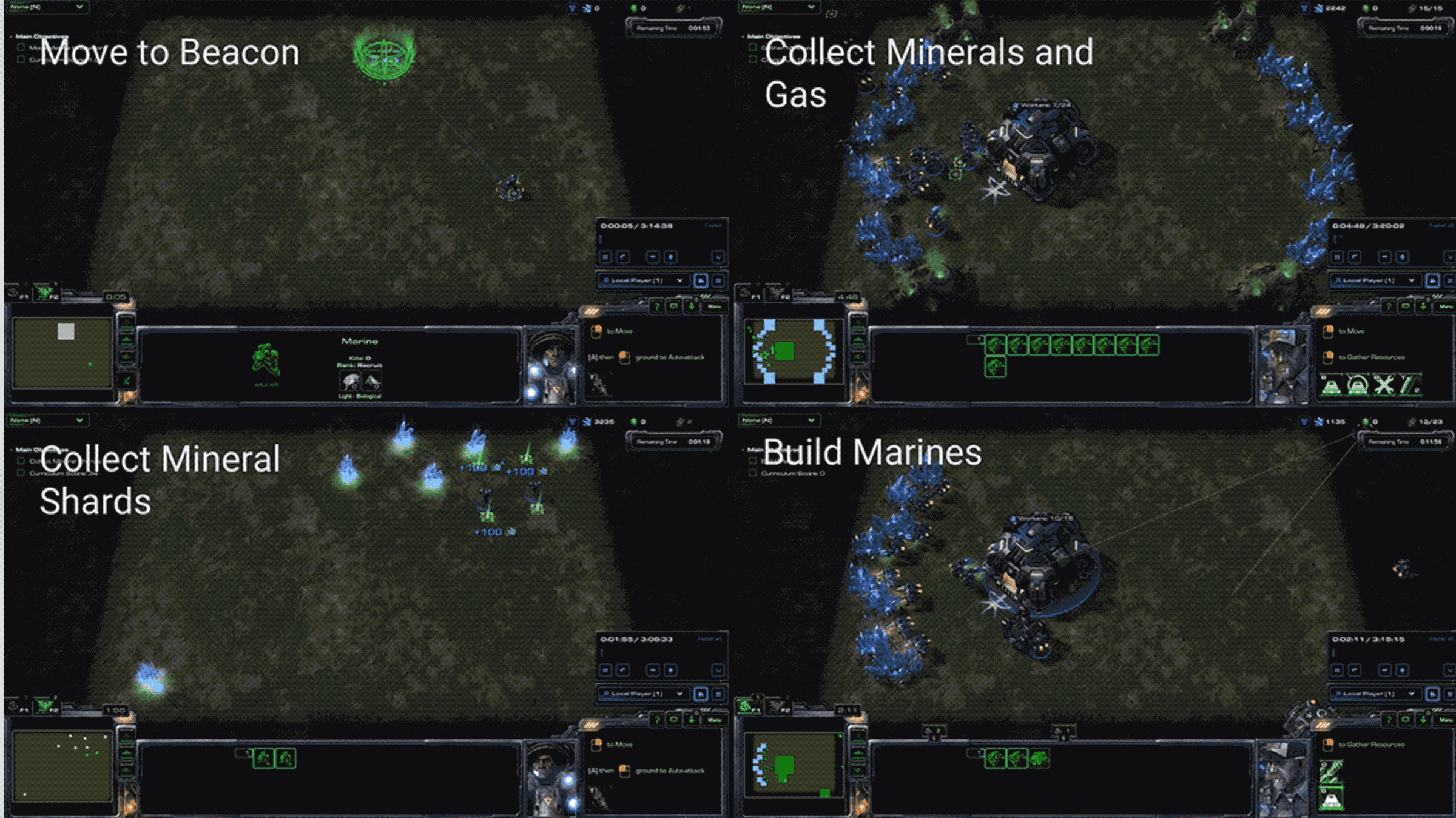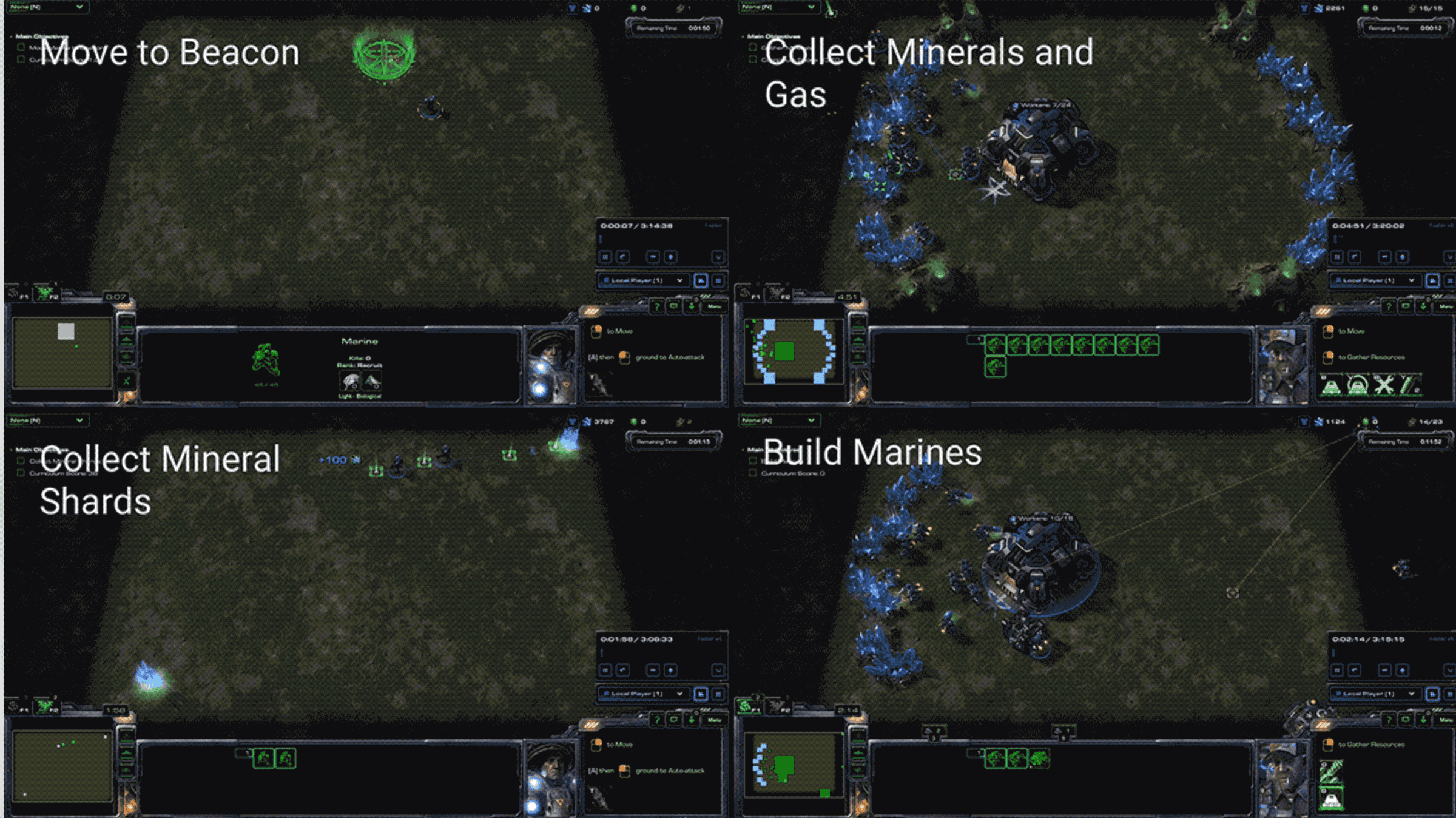
DeepMind 在博客中说,初始研究显示其智能体在迷你游戏上表现良好,但在完整游戏中,即使强大的baseline 智能体,比如 A3C,也无法打败最简单的游戏 AI。下面的视频展示了一个早期训练智能体(左),无法让其农民采矿,而这对于人类来说完全不成问题。训练之后(右),智能体采取的动作更为合理了,但还需要在深度强化学习和相关领域取得更多的突破,才能让其真正应对竞赛要求。
DeepMind 最后在博客中表示,使得他们的智能体学习更强大策略的一个技术是模仿学习(Imitation Learning)。暴雪将持续放出成千上万收集自星际争霸 2 ladder 的匿名游戏回放,多亏这一点,这种训练方法变得容易很多。这将不仅使研究者可以训练有监督智能体进行游戏,而且也将打开其他有趣的研究领域,例如序列预测和 long-term memory。DeepMind 希望此次新工具的发布将进一步推动 AI 社区已经在星际争霸 1 中所做的工作,鼓励更多的深度强化学习研究,使研究者更轻松地聚焦领域前沿研究。
DeepMind 论文:星际争霸 2,强化学习的新挑战

本文介绍了SC2LE(StarCraft II Learning Environment),这是基于“星际争霸2”游戏的强化学习环境。这个领域为强化学习提出了一个新的大挑战,提出了以前大多数工作未考虑到的更具挑战性的课题。
这是一个多智能体问题,并伴有多个玩家的互动。由于智能观察地图中的一部分,所以存在着不完全的信息;它具有涉及数百个单位的选择和控制的巨大的动作空间;它的状态空间巨大,只能从原始输入特征面观察;它需要超过数千步的长期战略,延迟了credit 分配。
我们描述了星际争霸2 的观察、动作和奖励参数,并提供了一个开源的基于Python 的界面,用于与游戏引擎进行沟通。除了游戏的主地图,我们提供了一系列迷你游戏,聚焦于星际争霸2 的不同元素。对于游戏的主地图,我们还提供了一个来自人类职业玩家(匿名)的游戏回放数据的附带数据集。
我们给出了从该数据训练的预测游戏结果和玩家行为的神经网络的初始基线结果。最后,我们给出了一些权威的深度强化学习智能体应用于星际争霸 2 的初步基线结果。在迷你游戏中,这些智能体学习达到了与新手玩家相当的游戏水平。但是,在主游戏训练中,这些智能体无法取得重大进展。SC2LE为探索深度强化学习算法和架构提供了一个新的、具有挑战性的环境。




本论文考虑的基础智能体的网络架构
此前,Facebook 刚刚公布了史上最大的《星际争霸:母巢之战》游戏数据集
2017年8月7日,Facebook 的四名科学家 Zeming Lin, Jonas Gehring, Vasil Khalidov, Gabriel Synnaeve 公布了史上最大的《星际争霸:母巢之战》游戏数据集:365GB,包含6万游戏记录,15亿帧,4.9亿玩家操作。
Github链接
在提交的论文中《STARDATA: A StarCraft AI Research Dataset》中,研究者们介绍,他们发布的STARDATA是一个包含了65646条星际争霸游戏记录的数据库,包含了15.35亿帧和4.96亿玩家操作。
“我们提供完整的游戏状态数据以及可以在“星际争霸”中查看的原始重播。游戏状态以每3帧为频次进行记录,确保它们适用于各种机器学习任务,如战略分类,反向强化学习,模拟学习,前向建模,部分信息提取等。我们使用TorchCraft来提取和存储数据,它可以将数据格式标准化,用于从重放中读取和直接从游戏中读取。此外,数据可以在不同的操作系统和平台上使用。数据集只包含了有效的,非损坏的重放,其质量和多样性通过一些启发式来确保。我们用各种统计数据来展示了其数据的多样性,并提供从数据集中受益的任务的例子。”
未来机器人像人一样坐在电脑前,操作鼠标打星际
国内AI 资深专家袁泉此前曾深入研究过星际争霸中的若干AI问题,和UCL共同发表了多智能体协作网络BiCNet,第一次展现了AI在星际微观战斗中的五类智能协作方式。新智元对此做过专门报道。此次DeepMind 和暴雪最新发布的星际争霸 2 AI开放研究平台的论文中,也多次引用了袁泉团队的工作。因此,袁老师应新智元之邀做了特别点评。他指出了此事的两点意义:
第一点:星际 2 的搜索和决策空间比 AlphaGo 围棋大了多个“数量级”,DeepMind、Facebook 等越来越多的优秀团队参与到这项研究中,很可能创造出更好的下一代AI的新技术。因为按之前玩围棋的技术框架的话,蒙特卡罗树搜索加深度强化学习,应该是不能完全解决星际中的问题,尤其是full game智能策略方面的难题。此次DeepMind和暴雪在AI开放平台、API标准化、性能架构上做了不少细致卓越的工作,为今后的研究打下了好的基础,希望国内有志于此方向的老师同学积极投入到此项研究工作中。
第二点: SC2LE 开放平台,相对于大家之前做的星际1的平台,最大的一个优势是提供了很多端到端的内容操作的接口,发展出来可以通过接口像人一样打星际,进行控制,这种接口是在之前的星际1平台上不提供的。基于这一点,未来有可能大家可以会看到机器人像人一样坐在电脑前,操作鼠标打星际和高手对决,对机器人等相关领域也是很好的促进!
人工智能的下一个大考:星际争霸
过去十年 AI 领域取得了巨大进展。借助标签数据监督,机器在一定程度上超过了人类的视觉认知和语音识别能力。同时,单个 AI 单元(又名智能体)在多项游戏中击败了人类,包括 Atari 视频游戏、围棋和德州扑克。
然而,真正的人类智慧包含社会和协作智能,这是实现通用人工智能(AGI)宏伟目标的基础。集体的努力可以解决个体无法解决的问题。即使像蚂蚁这样弱小的个体,当其形成社会组织时,也可以完成例如猎食、修建一个王国甚至发动一场战争这样有高度挑战性的任务。
有趣的是,在即将到来的算法经济时代,在一定程度上具有人工集体智能的 AI 智能体开始在多个领域出现。典型的例子包括股票市场上的交易机器人游戏,广告投标智能体通过在线广告交易平台互相竞争,电子商务协同过滤推荐者通过人群的智慧预测用户兴趣等等。AGI 的下一个重大挑战是回答大规模多个 AI 智能体如何从激励和经济约束共存的环境中吸取经验,学习人类水平的合作或竞争。随着深度加强学习(DRL)的蓬勃发展,研究人员开始借助增强后的学习能力,着手解决多代理协作问题。
Fortune报道称,DeepMind的目标是让计算机击败最顶级的人类星际争霸玩家。“这样的胜利将是人工智能的重大突破,但由于掌握游戏所需的复杂性,这可能还需要很长的时间。虽然DeepMind已经成功地创建了在玩经典Atari游戏时表现非常出色的AI软件,但星际争霸却带来了更加困难的挑战。”
Fortune的报道还说,DeepMind CEO Demis Hassabis 2017年5月在乌镇围棋峰会上曾表示, 他的团队认为,星际争霸是推动人工智能进步的一个大考验。
原文地址





大厂都在用的在线作图软件
包图网
- 4.2
(241)咨询产品免费试用稿定设计
- 4.0
(193)咨询产品免费试用fotor懒设计
- 4.1
(49)咨询产品免费试用



限时免费的在线作图软件
千图网
- 4.1
(293)咨询产品免费试用创客贴
- 3.9
(243)咨询产品免费试用摄图网
- 4.2
(86)咨询产品免费试用



新锐产品推荐
法大大
- 3.9
(319)咨询产品免费试用石墨文档
- 4.0
(89)咨询产品免费试用Teambition
- 3.7
(90)咨询产品免费试用微盟微商城
- 3.8
(36)咨询产品免费试用有道云笔记
- 4.0
(73)咨询产品免费试用聚水潭erp
- 4.1
(5)咨询产品免费试用







