大话3D
编者按:本文作者王进祥,从事云渲染行业,他们现在做的产品叫炫3D,是一个基于云渲染的设计分享平台,让用户分享并传播自己的设计。这是他的微博。
继好莱坞的3D大片风起云涌之后,最近3D打印也来势汹汹。恰巧本人就是吃3D这碗饭的,借着这股3D风,来谈谈我所了解的各种3D技术,发发牢骚,供大家解解闷。
3D的显示
其实自打有2D那天,人们就一直想着怎么搞出3D来。最早算得上3D的发明,按照Wiki上的说法,恐怕是1838年Charles Wheatstone发明的一种利用镜子来让人的左右眼分别看到不同的画面来模拟双眼观察同一场景的效果,并利用视差让人产生3D感的装置,算是现在红蓝眼镜这类视差3D的鼻祖。
Wheatstone mirror stereoscope
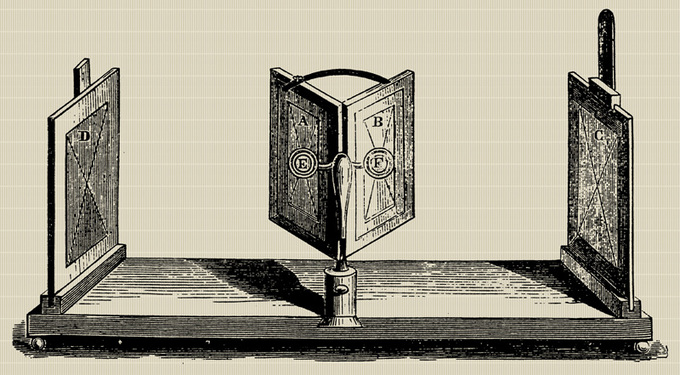
由于3D效果是利用人脑对视差,也就是双眼所观察到的画面有微小角度的差异,进行合成而产生的,并不需要真的有3D数据或者实物,因此算是最简单的一种呈现3D的方式。后来又有了很多改进版本,利用绘画,或者照片等等,但一直只能呈现静态的3D场景。直到摄影技术和光学的发展,可以用两个甚至多个摄像机模拟双眼的位置拍摄,并利用不同颜色或者偏振光来显示,让人借助特制的眼镜来产生3D的动态视觉效果。比如红蓝视频就是用偏红的颜色代表一只眼看到的影像,偏蓝的颜色代表另一只眼看到的,人带上眼镜后再看就能有3D感。
近几年更是有能在不同角度投射出不同颜色光线的3D屏幕,可以不借助任何眼镜等设备,让人眼直接观察到3D效果,也就是所谓的裸眼3D (Autostereoscopy)。但裸眼3D的一个问题是,对于只由对应左右眼的两组影像合成的3D场景,如果你的观察位置稍微有些移动,那么本应该左眼看到的影像可能就会被右眼看到,而左眼看到的却是右眼应该看到的影像,于是会有种错位感,英文叫movement parallax,中文大概翻译成移动视差吧。
2010年,我曾经在一个展会上演示过一台合作伙伴的裸眼3D屏幕,能在8个角度投射光线,也就是说它能模拟8只眼看到的影像。因此如果你在一个小范围内移动观察,也能保证双眼看到的影像是按照顺序的,一定程度上减轻了移动视差,但看时间长了还是会有点晕。
真正炫酷的技术是全息3D,能把3D影像直接投影在空中,并且无论从任何角度都能完美的观察到3D效果,是近年来好莱坞科幻电影的必备元素。

就拿我最喜爱的钢铁侠来说,这张截图中,Tony Stark正在利用全息投影来设计他的新型盔甲Mark II,他甚至还可以在空中操作投影出来的机械模型(这个应该可以用类似kinect的技术做到,后面还会提到)。
不过全息投影的原理可比视差3D复杂多了,在这给大家简单解释一下(涉及一些专业术语,需具备一定物理常识,不喜者可跳过)。
从电磁学的角度来说,光就是电磁波,具有振幅、频率和相位。振幅就是光强,频率就是颜色。一般的2D照相机,能够记录光的颜色和强度,也就是振幅和频率,但无法记录光的相位。而全息投影首先需要可以记录包括光的相位的所有信息,形成一张全息图。这也是全息的意思,光的全部信息。物理上做全息摄影时,一般将一束激光用棱镜分为光强不同的两束,以保证这两束激光频率相同、相位差恒定。强度大的一束作为物光打在物体上并反射到底片上,另一束强度弱的作为参考光直接打在底片上,与从物体上反射到底片的物光发生干涉,并记录在底片上。虽然底片依然只能记录光强和频率,但由于此时光强不止由物光决定,而是由物光和参考光的干涉结果决定,因此,其强度变化就记录了光的相位。而还原相位信息的办法就是,用同样频率的激光打在底片上,将底片记录的干涉条纹作为光栅,利用光的衍射来重现物体。但单一频率的激光只能记录一种颜色,据说彩色的全息图是由多束不同频率激光共同产生的。本人上学时只做过单色激光的全息摄影实验,至于彩色全息,具体技术细节不详。
除了物理上用激光产生全息图之外,还可以用计算机模拟激光干涉的过程计算出全息图(Computer Generated Holography,简称CGH)。这种方式更方便快捷,而且可以为虚拟的3D模型,而不仅仅是真实的物体产生全息图,甚至动态的全息视频。

上图是一张google出来的CGH全息图,同样也是不能直接看的,也要有相应频率的激光来还原才行。我见过一种打印在可以弯曲的特制塑料板上的全息图,在黑暗处用白光手电筒一照,就能看到还原的3D图像,在垂直于板子45°以内的位置都能很好的观察到,而且还可以卷起来放在装羽毛球的筒子里,很方便。
而且全息图一个很有意思的特点是,它的任何一部分都保存了物体上所有点反射的光线的全部信息。因此,哪怕只有半张、甚至一小块全息图,也都能完整的还原出原始的3D场景。这还只是制作全息图,要想将全息图投影出来,并从360°都能看到,也很复杂。一种方式是利用海市蜃楼的原理,将全息图投影在水蒸气上,利用分子的不均衡震动,来产生有层次感和立体感的图像。目前,全息投影的设备还都很贵,相比3D打印而言,还远没到能够普及的时候。但很多领域已经开始有所应用,比如演唱会、展览、产品发布会等等,前途无量,我个人非常看好。
全息3D,尤其是计算机产生的全息3D,和视差3D最大的区别在于,它需要真正的3D数据,而不是用几张2D图片靠人脑来产生3D感。传统上3D数据往往是用CAD或者类似3ds max、maya这样的建模软件做出来的。拿绘画做个类比,如果没经过训练,一般人很难画出逼真的2D画作,直到照相机的诞生。同样,如果没经过训练,一般人也很难用这些专业的建模软件做出逼真的3D模型,直到3D激光扫描仪的诞生。
如何获得3D?
激光扫描最早是从测绘领域发展起来的。大家应该时常能在马路上看到一些测绘人员,用一个架在三脚架上的仪器来测量马路。那种一般用的是全站仪,就是可以测量距离、角度、经纬度等等数据,集多功能于一身,所以叫全站仪。但是这类测绘仪器往往一次只能发射一束激光,测量一个点,并且为了提高精度,测量时间也比较长。激光扫描则是同时发射很多束激光,快速测量很多点的位置和角度,并将这些结果变换到一个统一的坐标系下,形成由很多点来描述的模型。如果给这些包含3D坐标的点加上颜色之类的信息,就是3D的像素,不严格来说也可以叫体素。就像2D图像是由具有2D坐标和颜色的像素组成一样,3D激光扫描仪扫描的结果是由具有3D坐标和颜色的体素组成的3D图像。
用中距离扫描仪扫描的建筑,左下角圆弧状没有点的地方就是扫描仪的位置

别看3D图像只比2D图像多了一维,数据量可是大了好多。一般高清数码相机的照片最多也就十几兆二十兆,可3D图像至少都有几十兆数百兆之大,包含成百上千万的点,因此有个形象的名字叫点云。就像2D图像可以分为光栅图和矢量图一样,激光扫描仪所产生的点云就相当于光栅图,而3D的矢量图则是CAD或3ds Max所产生的网格模型(mesh)。2D图像的矢量图大小一般小于光栅图,3D图像也是如此。而且在激光扫描仪之前的3D软件往往也只能处理网格模型,不能直接处理点云。所以常见的做法是先从点云中计算出网格模型,然后再做进一步处理。这个套路在制造业已经非常成熟,学名叫逆向工程,也就是大家熟悉的山寨。国内那些仿造的手机壳、汽车外壳等等,都是这么来的。
利用点云对汽车车身做逆向工程
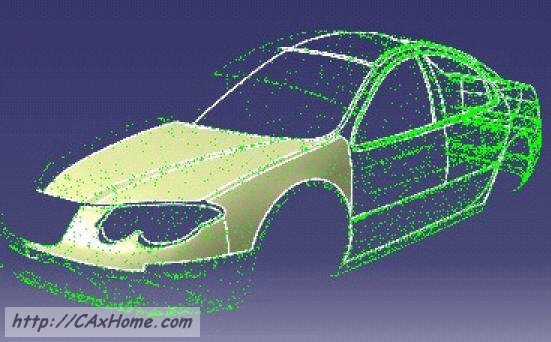
为了更快的扫描更大的范围,还可以把扫描仪安在汽车或者飞机上,将经过的地方都扫描下来。当然,这样扫描一圈回来,数据量肯定是非常非常大了。
说到这,估计有人会想,既然点云数据这么大,动不动上百兆上千兆,那转换成网格模型也会很慢啊。事实的确如此,有一本名字叫《基于点的图形学(Point Based Graphics)》的书,就专门研究如何直接处理点云,而不是网格。本质上,这是一个几何基元的问题。最早在计算机上表达3D模型的方法,其实也不是网格,而是像立体几何课本上所画的那些线框图,现在在一些CAD软件中依然可以看到。这算是用线来作为基元表达3D,后来才出现显示效果更好的多边形网格。而由于三角形是最简单的多边形,并且计算上能做很多优化,用的人越来越多,渐渐成为了网格模型的主流,OpenGL标准也就直接以三角网格作为几何基元,专门处理3D的显卡GPU也都对三角网格的显示做了最多的优化。但点才是几何上最简单的元素,比三角形还要简单。基于点的图形学已经能把点云显示的和网格效果一样好,也能做光线追踪,不用特殊处理就直接可以做粒子系统模拟物理过程的动画,还能做基于点的有限元分析,好处多多。而如今又有了能很容易产生点云模型的设备,那么是否将来会用点来代替三角网格呢?归根到底,无论是网格还是点云,都是为了能在计算机上表达3D模型,只要能够表达好模型,用什么无所谓。
专业的3D激光扫描仪非常贵,一般都要几十万RMB,不是一般人消费得起的,而且其数据后处理也需要一定的学习,不那么容易上手。但微软无意间做了一件好事,发明了kinect,让一切又有了希望。
本来kinect只是被微软用在自己的xbox上做体感游戏的输入设备,也就是在游戏中像钢铁侠里的Tony Stark那样,能够凭空操作机械模型之类的事。但微软的研究人员不满足于此,还建立了一个名为Kinect Fusion的研究项目,利用kinect来进行3D激光扫描,并发表在2011年的SIGGRAPH上。
发布会上的Kinect

很快,开源项目Point Cloud Library也实现了自己的开源版本KinFu,利用GPU的通用计算能力来实时计算扫描的模型。前几天,我在公司的Ubuntu上也玩了一下开源版的KinFu。因为还没发布,所以KinFu要自己从源代码编译才能运行,不过操作起来非常简单,并可以在屏幕上直接看到扫描的中间结果,可以及时调整扫描的位置,几分钟就能熟练掌握,大大降低了激光扫描的门槛。只是目前kinect的精度还比较低,其彩色摄像头的分辨率是640x480,而深度传感器的分辨率只有320x240,使得扫描出的模型比较粗糙。毕竟kinect最开始只是用来玩游戏的,但如果市场需要,相信今后会不断改善。
用PCL KinFu扫描的办公桌,有点乱,凑合看吧

听说微软已经计划把Kinect Fusion集成到其Kinect For Windows中了,以后只要花不到2000块买个kinect,就能自己在家扫描了,比单反相机还要便宜。而最近,新秀创业公司Leap Motion,计划在明年初发布其类似kinect、但精度大大提高的3D动作控制系统。其所公布的参数如果属实,那将可能使kinect fusion这一技术达到传统激光扫描仪的水准,而同时成本却大大降低,非常值得关注。
如果你觉得专业的3D激光扫描仪太贵,而Kinect Fusion的模型又太粗糙,还有个办法,就是照片建模。理论上,通过若干个在两张照片中同时出现的空间点,就可以计算出它们在空间中的相对位置。如果能知道其中某两点的实际距离,则能计算出其它点的绝对距离。类似激光扫描,只要点足够多,就足以从中重建出3D模型。美国华盛顿大学的开源项目Build Rome In A Day就是利用这一方法,通过收集互联网上大量的照片,提取出那些在多张照片中都出现过的特征点,并计算这些点的空间坐标,进而产生很多模型。如果真的照片足够多,可以使所有场景串联起来,就有可能重建出一个城市来。后来微软基于这一项目推出了自己的一个在线照片建模平台photosynth,最近3D领域的巨头Autodesk也推出了自己的123D Catch,也是类似的在线产品。
如果照片分辨率够高够清晰,照片建模确实可以得到比Kinect Fusion更好的模型,而且只要用一般的数码相机即可,不需要特别的设备。但因为照相时往往会有一些死角,或者没法在不挪动目标的情况下一次拍摄到的地方,要想做一个完整的好模型出来,拍摄时就要非常小心,有时还需要挪动目标拍摄多组照片,并在后期将每组照片生成的残缺模型拼接起来,以形成完整的模型。其中有很多技巧,不是很容易掌握。
照片建模,拍了正反两组照片,拼接而成的一只完整的玩具龟

现在我们有了各种制作3D模型的方法,那怎么才能把这些模型方便的分享给好友们呢?
分享你的3D
用3D打印机把模型打印出来,是最直观的方法,而且最好的机器不只可以打印塑料,还可以打印金属,只是成本高了些。或者直接把3D文件发给对方,但据我所知,还没有哪个操作系统像支持2D图像那样,能原生支持某种3D格式。
随HTML5而来的WebGL让通过互联网共享3D模型成为可能。开源项目three.js就是用WebGL实现的一套Javascript的3D图形库,在它的官网有很多示例,体验还是很不错的。
不过WebGL也有一些天生的缺陷。首先,WebGL需要把3D数据下载到浏览器本地才能显示,所以在能看到3D模型之前多少都要等一会儿,时间长短取决于模型大小和网速。如果数据还是用Javascript来解析的,那么别人就有可能复制和破解你的数据,用于他处,这对需要保密或者有版权的3D数据是很不好的。其次,WebGL需要浏览器支持HTML5,其运行性能也严重依赖浏览器的实现。目前chrome的支持是最好的,实现的WebGL性能也不错,其他浏览器就差一些。但即使在理论上,WebGL的性能也不可能赶上直接使用OpenGL的桌面程序。而且WebGL这种通过浏览器来解释执行的方式,也意味着其对用户终端的3D硬件有所要求,尤其是显示大模型、或者复杂的3D效果,都需要更好的硬件支持才行。对于台式机和笔记本,或许还可以配一块好一些的显卡,但对于移动设备,如手机和平板,往往不会有这么好的显卡,所以支持WebGL的移动浏览器好像还没有,反正我还不知道。
但办法还是有的。如果能把3D模型放在服务器端,只在浏览器上根据用户操作,显示渲染好的2D图片,只要网速足够快,使得2D图片的更新足够快,用户用起来就会和在本机查看3D模型是一样的。这个远程桌面就可以做到,只是不能同时支持太多并发用户,因为这是由远端服务器上运行的软件决定的,而这些传统桌面软件往往也不支持并发,远程桌面对此也无能为力。
真正能解决问题的是云渲染。
据说云渲染的概念是AMD在2009年的CES展会上提出的,并预计将主要应用在3D网游上。3D网游本质上也是大量共享3D模型的应用,而且和远程桌面不同,会有很多玩家并发查看和操作这些模型。设想一下,如果只有一个用户,那云渲染就应该和远程桌面差不多,但当并发用户和操作很多时,情况就完全不同了。因此,真正的云渲染就像任何一种云计算技术一样,需要一个服务器集群来为众多并发在线的用户服务。不过和另一种被称作渲染农场的、也是利用集群来渲染3D场景的应用不太一样。渲染农场是专门用来应付像好莱坞大片中那些逼真复杂的3D特效的,它们往往通过模拟真实的物理过程来得到逼真的3D画面,其计算过程非常复杂。如果只有一台计算机,每一帧画面都得需要数分钟甚至数小时的计算才能渲染出来,而集群的分布式计算能力正可以用来加快其速度。也就是说渲染农场的集群是专门用来应对那些很大的、需要多台服务器协作的渲染任务,但渲染的结果往往只供一个或很少的用户使用,很少有并发的情况。云渲染则是要应对那些一台服务器就可以很快处理完的小渲染任务,但很多很多,而且需要将不同的渲染结果返回给不同的用户。需求和目的不同,也导致了两者在架构上很大的不同。渲染农场的工作原理比较接近MapReduce,先是要将一个很大的渲染任务分解,并分发到多台服务器上处理,然后再将处理后的结果汇总,并最终返回给用户,不需要处理并发。而云渲染则更像是一个网站,将很多用户的并发请求通过负载均衡设备,分发给那些有空闲的服务器处理,然后各个服务器只需要将处理结果直接返回给发送请求的用户就可以了,不需要汇总,也不一定需要负责分发的服务器转发,但是一定要能应对大量并发请求。
由于云渲染的显示结果需要通过网络传输,体验起来暂时还不能达到WebGL那么好,但它也有一些无法比拟的优势。第一个就是不需要HTML5,也不需要什么特别的显卡支持,只要能够显示2D图片就可以,而现代的所有浏览器都满足这一点,而且可以连flash、silverlight插件也不需要。第二呢,因为不需要特殊的浏览器,也不需要插件,对硬件也没要求,所以只要带宽足够,任何能上网的设备都可以用,移动设备也没问题,iphone、ipad这样不支持flash的系统也没问题。还有一条很重要就是不需要下载模型,因为渲染过程都是在服务器端完成的,浏览器得到的只是一张渲染好的2D图片,所以也就不可能有机会复制或破解你的3D数据。唯一需要的是网络带宽要够大,足以将渲染的图片快速传输到浏览器显示出来,和网络视频的带宽要求是差不多的。现在电信光纤的带宽已经可以达到20Mbps,足以应对云渲染的要求。看新闻明年国内也可能开始上4G了,到时候即使对移动设备,带宽也根本不是问题。
虽然理论上看一切都很好,但云渲染的实现难度明显大于WebGL,因此目前真正能够实用的云渲染产品还不多。
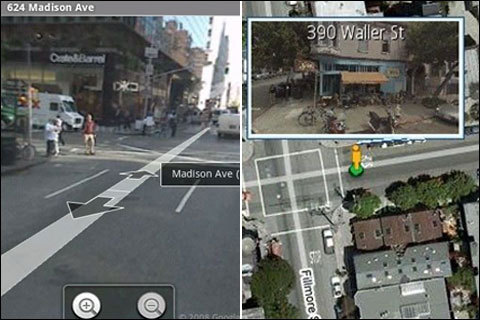
还有一个值得一提的技术——3D全景图。其原理是将站在同一位置、不同角度拍摄的多张照片缝合起来,形成一个可以在定点360°观察的、看起来像3D的图像,所以叫全景图。这也是最廉价的一种伪3D技术,非常适合像Google街景这样,需要大量、低成本、快速制作模型的应用。但与WebGL和云渲染相比,效果也是最差的。
Google StreetView
可以说到目前为止,和2D技术相比,3D技术的发展才刚刚开始。想当年,那些庞大、笨重、难用且只有黑白色的老式照相机器,演变到如今随身携带、高精度的彩色数码相机,以及从胶卷到数码打印、复印,再到各种网络共享方式,2D领域的变化可谓沧海桑田。即使到了今年,也依然有专注于2D图片分享、并被facebook以10亿美元的重金收购的Instagram。而现在的那些昂贵的3D激光扫描仪,就相当于2D中那些笨重、老旧的设备。Kinect Fusion或许代表了新的方向,而3D打印就相当于胶卷和印刷术,WebGL和云渲染就是3D的网络共享,谁又知道3D中的Instagram在哪里呢?
一切才刚刚开始。





行业专家共同推荐的软件
包图网
- 4.2
(241)咨询产品免费试用稿定设计
- 4.0
(193)咨询产品免费试用fotor懒设计
- 4.1
(49)咨询产品免费试用



限时免费的在线作图软件
千图网
- 4.1
(293)咨询产品免费试用创客贴
- 3.9
(243)咨询产品免费试用摄图网
- 4.2
(86)咨询产品免费试用



新锐产品推荐
童虎售后服务管理系统
- 0.0
(0)咨询产品免费试用赛意-大数据BI
- 0.0
(0)咨询产品免费试用赛意业财
- 0.0
(0)咨询产品免费试用赛意·SMES制造执行系统
- 0.0
(0)咨询产品免费试用赛意-IMS国内营销系统
- 0.0
(0)咨询产品免费试用麦金塔科技售后服务管理系统
- 0.0
(0)咨询产品免费试用







