客户之声:如何进行客户情感分析,获取潜在机会

你是否曾经想过,你的产品或服务是否真正满足了客户的需求?你是否想知道客户对你的公司、品牌和员工的态度?如果你想要了解这些信息,就需要进行客户情感分析。
01 什么是情感分析
情感分析(或观点挖掘)是一种自然语言处理 (NLP) 技术,用于确定数据是正面、负面还是中立。情感分析通常对文本数据进行分析,以帮助企业监控客户反馈中的品牌和产品情绪,并了解客户需求。
-
情感分析的类型
根据您希望如何解释客户反馈和咨询,您可以定义和定制类别以满足您情感分析需求。以下是一些最常用的情感分析类型:
1)分级情感分析
如果极性精度对您的业务很重要,您可以考虑扩展极性类别以包括不同级别的正负向:

2)情绪检测
使用词典的缺点之一是人们表达情感的方式各不相同。一些通常表达愤怒的词,如 "坏"(bad)或 "杀"(kill)(例如,你的产品太糟糕了,或者你的客户支持简直要了我的命!)也可能表达快乐(如 "这真是个大坏蛋 "或 "你们真是太棒了")。
3)基础情感分析
这就是基础情感分析可以提供帮助的地方,例如在产品评论中:“这款相机的电池寿命太短”,基础分类将能够确定该句子表达了对相关产品的电池寿命的负面意见。
4)多语言情感分析
或者,您可以使用语言分类器自动检测文本中的语言,然后训练自定义情感分析模型,用您选择的语言对文本进行分类。
02 为什么情感分析很重要
也许您想跟踪品牌情感,以便您可以立即发现不满的客户并尽快做出回应。也许您想比较这个季度和下一个季度的情绪,看看是否需要采取行动。然后,您可以更深入地挖掘定性数据,以了解情感下降或上升的原因。
-
情感分析的总体趋势
您能想象手动整理成千上万条的推文、客服对话或调查报告吗?情感分析可帮助企业以高效、经济的方式处理大量非结构化数据。
2)实时分析
情感分析可以实时识别关键问题,例如社交媒体上的公关危机是否正在升级?愤怒的客户是否即将流失?情感分析模型可以帮助您立即识别这类情况,以便您可以快速采取行动。
3)一致的标准
通过使用集中式情感分析系统,企业可以对其所有的数据应用相同的标准,从而帮助他们提高准确性并获得更好的洞察力。
03 情感分析如何工作
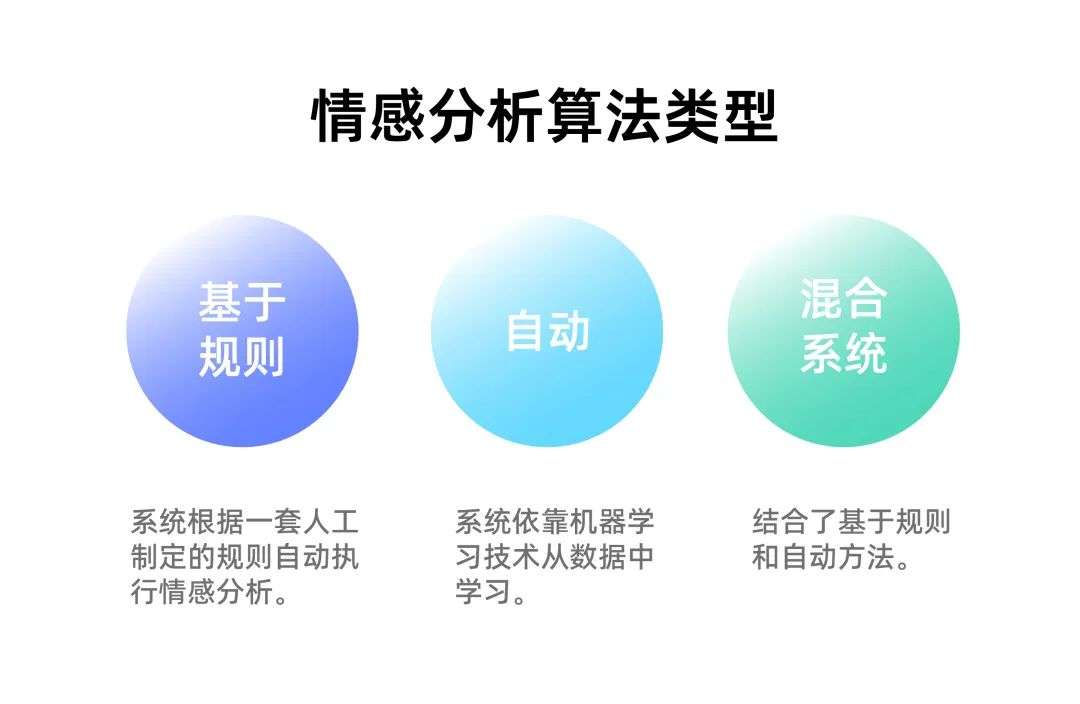
1)基于规则的方法
下面是基于规则的系统如何工作的基本示例:
1.定义两个极化词表(负面词表,如坏、最差、丑等和正面词表,如好、最好、美丽等)。
3.如果正面词语出现的次数大于负面词语出现次数,系统就会返回正面情感,反之亦然。如果两者相等,系统将返回中性情感。
基于规则的系统非常基础,因为它们没有考虑单词在序列是如何中组合的。当然,可以使用更先进的处理技术,并添加新规则以支持新的表达和词汇。但是,添加新规则可能会影响以前的结果,整个系统可能会变得非常复杂。由于基于规则的系统通常需要微调和维护,因此也需要定期投资。
2)自动方法
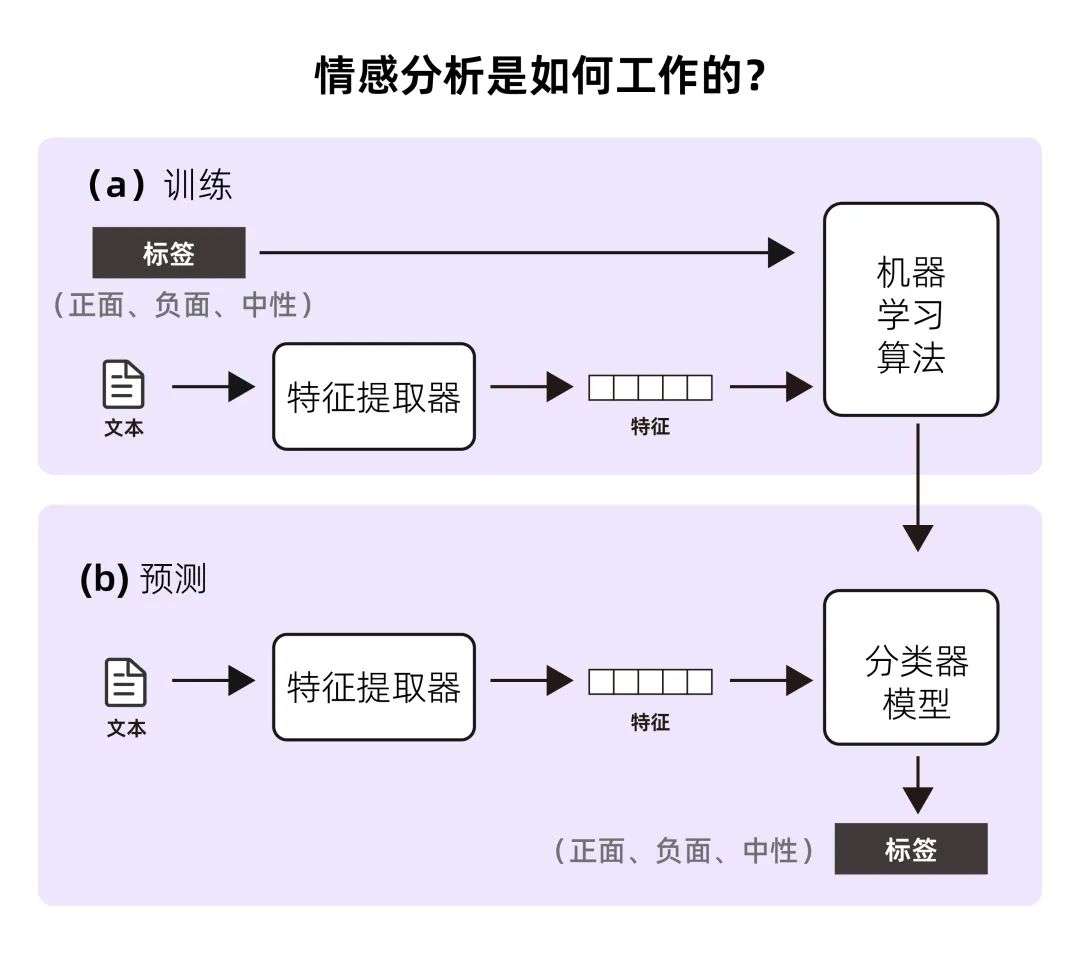
-
训练和预测过程
在预测过程(b)中,特征提取器用于将看不见的文本输入转换为特征向量。然后将这些特征向量输入模型,由模型生成预测标签(同样是正面、负面或中性)。
-
从文本中提取特征
如今,基于词嵌入(也称为词向量)应用了新的特征提取技术。这种表示使具有相似含义的词可以具有相似的表示,从而提高分类器的性能。
-
分类算法
深度学习: 一组多样化的算法,试图通过采用人工神经网络来处理数据的方法来模仿人脑。
3)混合方法
混合系统将基于规则和自动技术的理想元素组合到一个系统中。这些系统的一个巨大优势是结果往往更加准确。
04 情感分析的挑战
数据科学家在创建更准确的情感分类器方面正在取得进步,但还有很长的路要走。
-
主观性和语气

大多数人会说,第一个情绪是积极的,第二个是中性的,对吗?所有谓语(形容词、动词和一些名词)在如何创造情感方面都不应该一视同仁。在上面的例子中,好看比红色更主观。
-
语境和极性
如果我们要至少考虑到产生文本的部分背景,就需要进行大量的预处理或后处理。然而,如何对数据预处理或后处理,以捕获有助于情感分析的上下文信息,并不是一件简单的事。
-
讽刺和挖苦

那么第二个回答呢?在这种情况下,情绪是积极的,但我们相信你可以想出很多不同的情况,在这些情况下,同样的回答可以表达负面情绪。
-
比较

不过,第二和第三文本有点难以分类。你会将它们归类为中性、正面甚至负面吗?同样,语境也会产生影响。例如,如果第二个文本中的“旧工具”被认为是无用的,那么第二个文本与第三个文本非常相似。
-
表情符号
在对推文进行情感分析时,需要特别注意字符级以及单词级,可能还需要大量的预处理。例如,您可能希望预处理社交媒体内容,将西方和东方表情符号转化为标记并将其列入白名单(即始终将它们作为分类目的的特征),以帮助提高情感分析性能。
-
定义中性
1)客观文本
所谓的客观文本不包含明确的情绪,因此您应该将这些文本归入中性类别。
2)无关信息
如果您尚未对数据预处理以过滤掉无关信息,则可以将其标记为中性。但要注意的是,只有当您知道这样做会如何影响整体性能时,才能执行此操作。有时,您会给分类器添加噪音,导致性能变差。
比如,“我希望产品有更多的集成”这种愿望通常是中性的。但是,像 "我希望产品更好 "这样包含比较的愿望就很难归类了。
-
人工注释器准确性

























