数据智能提升产品分发效率

随着互联网的发展,产品的分发方式也在逐步演进。
本文主要介绍四种常见的产品分发策略,并且讲述如何通过数据智能的方式提升各种分发策略的效率,助力精细化运营;同时,结合具体案例进一步说明如何进行推荐策略的迭代与优化。
为了更好地理解产品分发,我们以最常见的支付宝 APP 为例。
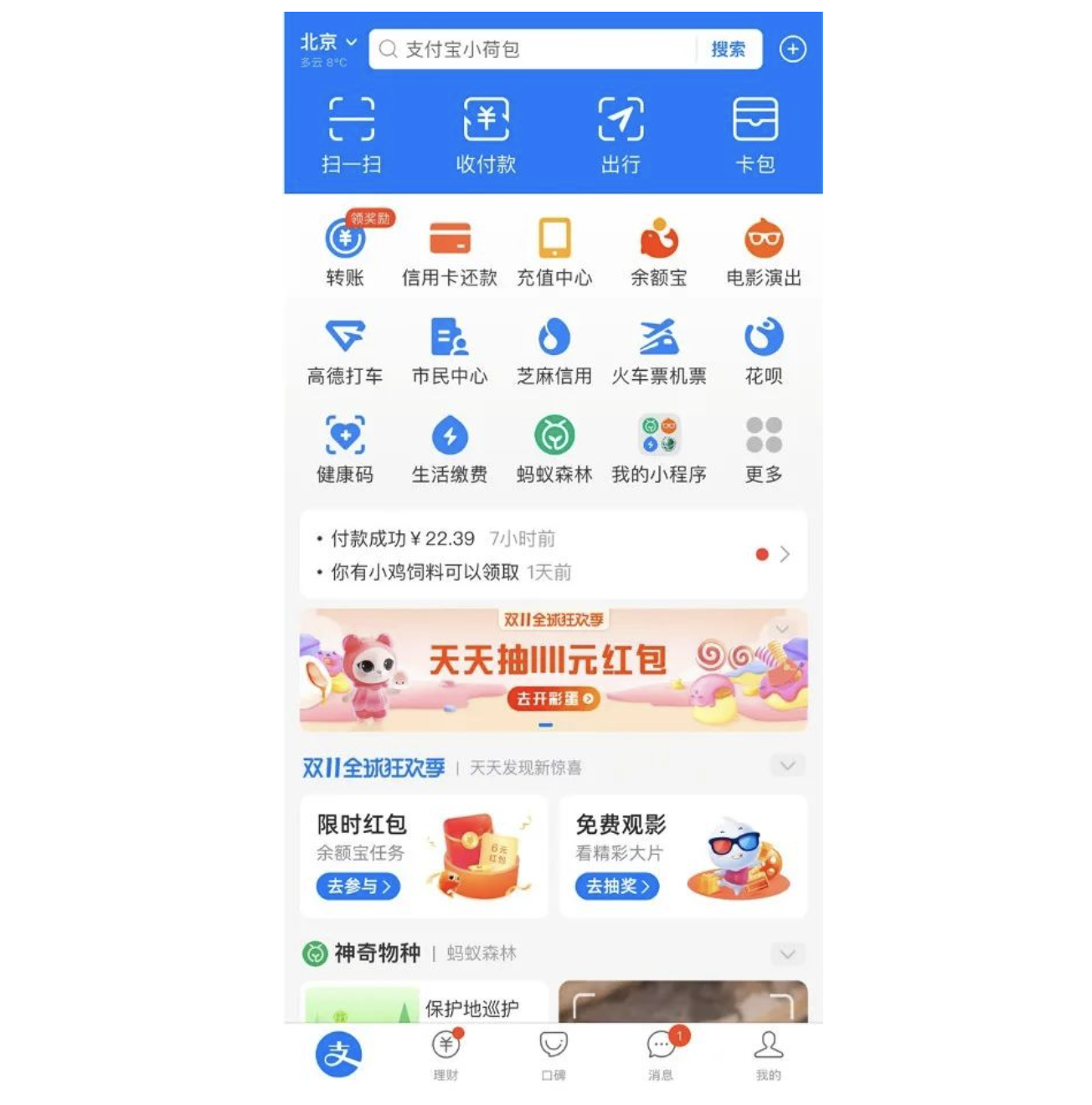
- “扫一扫”“收付款”“出行”“卡包”四大“金刚位”,是用户进入 APP 的视觉焦点,这四个位置只承接公司的战略业务,因此基本所有人看到的都是一样的。一旦这些位置的内容有所调整,说明支付宝甚至阿里的经营战略可能已经发生了变化
- 下方的五大“罗汉位”,之前是无法编辑的,因为承接的是支付宝仅次于战略业务的方向性业务,后来综合考虑用户的使用效果进行了调整,因为即使是方向性业务,用户不点击也是流量的一种浪费
- 再下方的宫格位承接的是诸如餐饮、出行、缴费等生活服务入口,其位置也可以进行排序。
- 再下方的“消息”,并不通过规则分发,而是由业务逻辑触发,比如商品到货、退款到账等
总结来说,支付宝首页既有完全一样分发的战略业务,又有基于规则排序的宫格位;有基于运营和投放的 Banner,还有基于个性化推荐的 Feed,基本涵盖了互联网产品主流的分发逻辑。
如果某个互联网产品所能够提供的服务较少,核心沟通场景只有一个,原则上不用考虑分发策略,但当产品开始出现运营需求,就要开始考虑人工运营的分发。
而随着服务能力的增多,需要通过简单的规则进行排序,比如高点击率、高曝光、高转化的页面排在前面;当服务能力进一步增强,内容逐步增多,简单的规则排序已经不能满足分发效率,这时可以通过搜索帮助用户直达某项服务;当用户圈层越来越多,用户体量越来越大,单纯的搜索可能也无法满足需求,这时可以考虑个性化推荐。
简而言之,随着互联网的发展,分发规则也在逐步演进。
通常,产品的分发策略总共分为 4 类:人工运营、规则分发、搜索分发、算法分发。
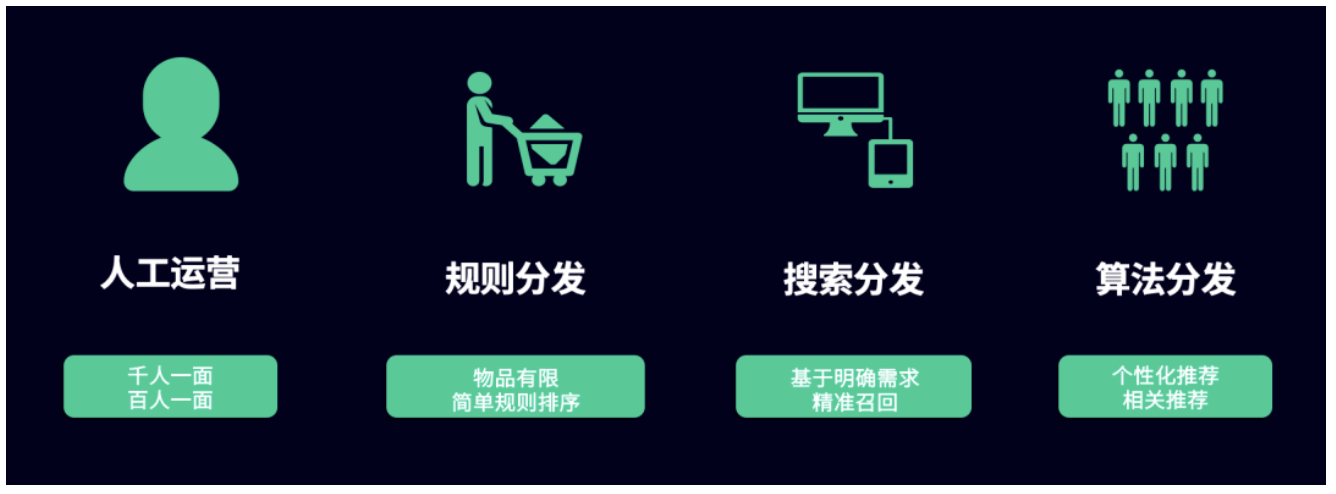
- 人工运营:可以实现千人一面(即所有人看到的是相同的版本)或者百人一面(通过圈人的方式提高某些页面的效率)
- 规则分发:当服务的品类变多,需要通过简单的规则提升效率
- 搜索分发:基于明确的需求,进行精准的召回
- 算法分发:个性化推荐或相关推荐
那么,产品分发究竟是什么?产品分发本质上是用户需求的分发。
当用户打开一个产品,其需求是比较明确的,比如打开抖音就是要看短视频、打开淘宝大概率要买东西、打开腾讯会议是要开会等,产品分发原则上要以最短的路径把想看的内容展示给用户。对平台而言,用什么样的分发方式可以将用户导流到业务线一、业务线二等,如何提高匹配的效率就变得比较重要。
同时效率不单只针对用户,也要平衡平台效率,比如当前战略目标是做好某项业务,站在平台的视角,适合什么样的分发规则?解决匹配效率时,要实现产品战略和平台收益的最大化。
人工运营、规则分发、算法分发,从前到后三类分发方式的智能化程度越来越高,效率也是越来越高。接下来分别讲述如何通过数据智能提升三种分发方式的效率。
1、人工运营
举个例子,某金融 APP 运营要在首页增加理财弹窗。
通常,首页弹窗的用户体验不太好,原则上是能不弹就不弹,但如果必须进行弹窗的话,建议只对那些对弹窗内容感兴趣的用户进行弹窗触达,避免对其他用户的打扰。
过去的做法一般是基于地域、性别或年龄对人群进行定向筛选,比如过去购买此类理财产品的用户大多为北京、年龄在 25-30 岁,那就基于这些静态特征将这批用户圈选进行弹窗展示。
但更高效的分发方式其实是只给对相关活动感兴趣的用户弹窗,那么目标就是如何找到感兴趣的用户?如果只基于用户过往行为,比如过去参加过类似活动而展示,可能会错失一些虽然没参加过活动但可能同样感兴趣的潜在客户,这时可以基于特征挖掘找到站内相似的用户。
如果之前平台没有做过类似活动,没有相关特征该如何挖掘呢?平台在进行相关活动推广时,通常会先进行小规模放量的灰度测试,比如先切 10% 的流量给到相关活动,在这 10% 的用户中,如果有人点过相关弹窗,说明他们对弹窗是感兴趣的。这时便可以从 10% 的用户中筛选出种子用户,基于他们进行全站特征挖掘,从而把对活动感兴趣的用户全部圈选出来。
在人工运营的分发方式中,提效的主要路径是从粗放式运营到用户分群运营。用户分群如何分?主要有三种:基于静态属性分群、基于行为分群、基于用户行为特征挖掘分群。
2、规则分发
规则分发该如何提效?
假设用户点开某金融 APP 后,同时命中 10 个弹窗规则,到底应该弹哪个?
通常针对这种情况都会制定相关规则,比如点击率(CTR)最高、上线最久或是即将下线等等,但这往往会陷入一个逻辑陷阱:所有排序的规则大都基于不同弹窗的表现情况,而并没有考虑用户偏好。
如果想找到用户爱看的弹窗,首先要对用户进行更细颗粒度地洞察,比如过往是否买了理财、是否贷过款、是否领过赠险……根据过往的行为,为用户打上偏好标签,从而对他们有进一步的认知,然后基于标签匹配进行规则分发,比如为有理财偏好的用户弹出理财体验金;为已通过授信但尚未提现的用户弹出免息券等。总之,通过更细颗粒度的用户标签为规则分发提效。
3、算法分发
如果相关分发规则颗粒度更细,其实就进入到个性化算法分发模式。我们对用户的理解越细致,分发的效果就越好。
通常个性化算法分发比较依赖数据,用户是谁?有什么特点?用户特征如何?这些是做运营,甚至是做个性化推荐的基础。
用户特征通常分为两类,一类是静态特征,一类是动态特征。
静态特征:一段时间内不会发生变化的特点,比如性别、年龄、地域、渠道等。
动态特征:基于用户行为来提取的特征,他和用户当前场景下的兴趣和爱好息息相关。比如:
-
用户手动输入的信息:包括用户在搜索引擎中输入的关键词,用户反馈的信息,对推荐对象的喜好程度等;
- 用户基于 Item 的行为:包括浏览、点击、停留时长以及互动行为(转评赞等);
- 负反馈:不喜欢、不感兴趣。
除了对用户特征的刻画,还需要对物品特征进行刻画。比如对视频内容、运营物料等有所了解,这些称之为 Item,Item 也分为静态和动态特征。
物品静态特征:指内容自身的属性特征。例如:视频时长、图片宽高比、安全等级、风控等级、作者、内容字数、一级分类、二级分类……
物品动态特征:指的是基于用户行为抽象的特征,动态特征又分为正反馈和负反馈。例如:点击率、完播率、点赞率、分享率、评论率、收藏率、负反馈……
知道了用户和物品的特征后,只有做好中间的匹配,才能做好个性化分发。
1、个性化分发的逻辑框架
个性化算法分发涉及的逻辑结构主要有三个:召回、排序、重排。
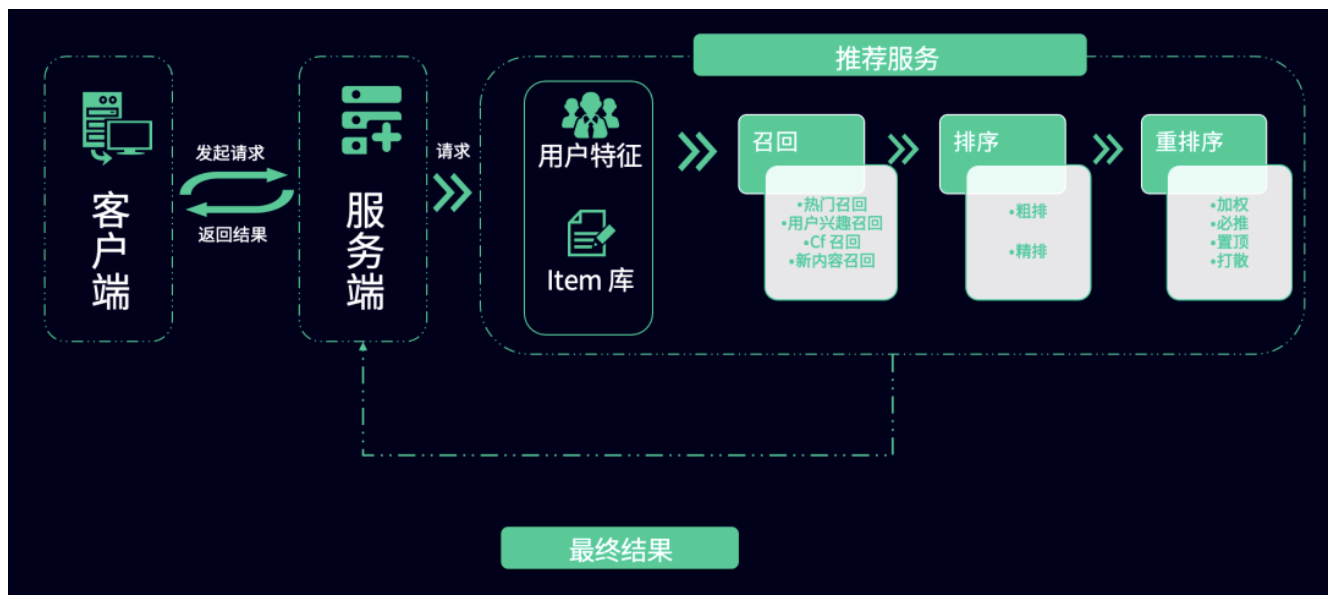
召回
比如某个新闻资讯 APP 对站内内容按照热门来排序,高点击率的内容放在前面,即热门召回;比如有的 APP 会基于用户偏好进行排序,即基于用户偏好召回;此外还有基于地域的召回等。
召回指的是基于什么样的规则或特征,把内容从库里检索出来进行排序分发。
排序
排序的目标要结合具体的业务场景确定,即业务上达成什么样的目标,最有可能实现目标的物料会被排到前面。
比如业务目标是提高新闻资讯流 CTR,那么就按照 CTR 预估排序,用户最可能点哪个,就把哪个放前面;比如电商的推荐目标是提升购买转化率,哪个对用户来说最可能成单,哪个就排前面。
重排
因为召回和排序的过程是一个算法黑盒,没有办法控制。当算法排序结果不符合预期时,可以进行策略干预,这被称为重排序。
比如某个作者比较热门,其内容表现都很好,如果按照正常运算的排序,很可能多次刷到的都是他一个人的内容,而平台希望用户看到更多元和丰富的内容,这时就需要打散重排。
2、策略迭代的 SDAF 原则
个性化算法该怎么优化?
基于神策 SDAF 原则,所有策略优化都要基于数据洞察,明确要优化的方向和目标,进行策略方案迭代,通过 A/B 试验展开行动,最终基于试验结果进行归因。
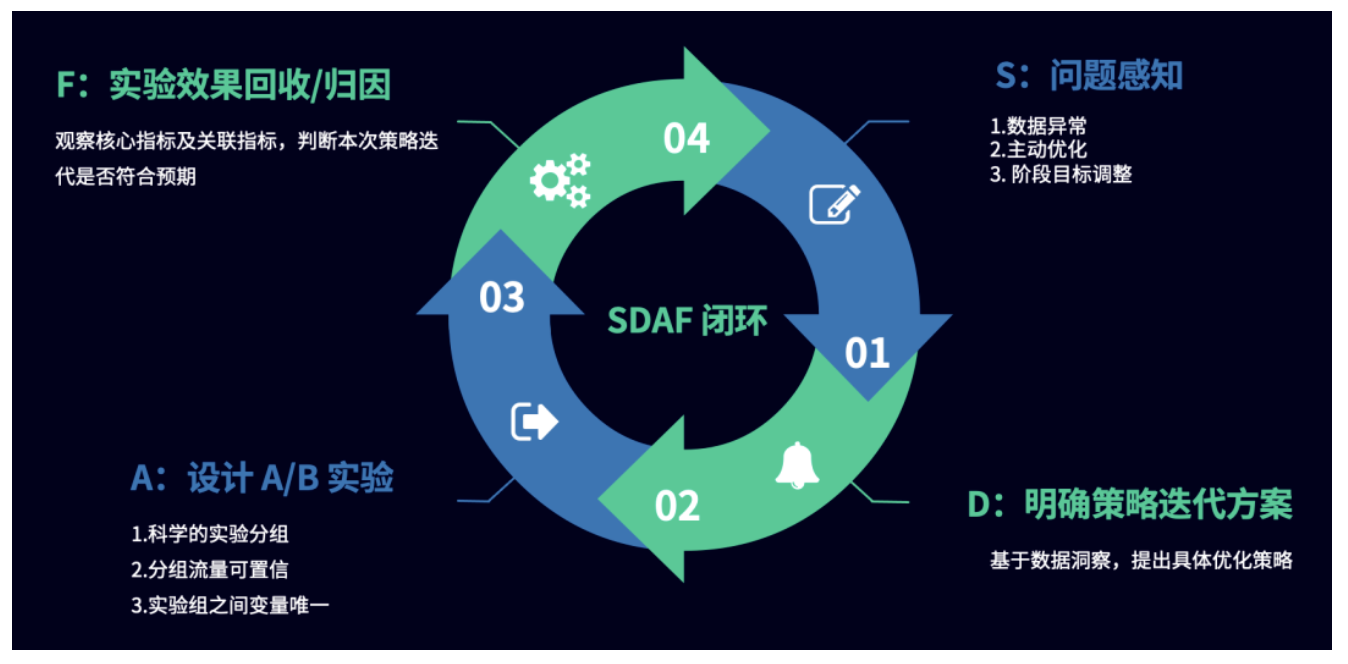
Sense:问题感知
对于推荐策略的数据洞察,包含三部分:数据异常、主动优化、阶段目标调整。
数据异常:包括核心指标 CTR 下降,要去看为什么会下降,与哪些因素有关等。
主动优化:比如想把当前 CTR 由 15% 提升到 30%,优化哪些维度可以实现。
阶段性目标调整:当完成 CTR 优化后,接下来想优化互动率这个指标,那么排序的目标就要从 CTR 转为互动率,这影响的是底层的算法逻辑。
Decision:明确策略迭代方案
以电商为例,如果只优化 CTR,对曝光和点击进行埋点即可;而如果要优化成交率的话,那么就要看与成交相关的行为,比如收藏、加购等,这些都需要进行埋点,获取数据后进入到模型训练流,只有获取到数据,模型才能基于目标进行优化。
数据洞察的主要目标是拒绝拍脑门的需求,每个需求在进行 A/B 实验前都需要拿数据先验证一轮。基于数据洞察,提出具体的优化策略。
Action:设计 A/B 实验
设计 A/B 实验时要遵循三个原则:科学的实验分组、分组流量可置信、实验组之间变量唯一。
Feedback:实验效果回收/归因
当实验结果不符合预期,要进行归因分析。但神策认为即使试验的收益是正的,也要进行归因分析。
案例 1:某 UGC 平台要求仅召回高评论内容
某 UGC 平台要求召回高评论的内容。在评估这个需求时,我们可以思考两个问题:是否进行了数据洞察?高评论内容一定是好内容吗?
好内容具有 CTR 高、消费表现好、互动率高的特点,而高评论只是互动率这个指标的体现,并不是整体好内容的指标,因此评估高评论内容的消费表现,需要进行数据洞察。
假设优化了高评论的排序后,能够提升社区消费的深度,那么就要把高评论的内容选取出来,并对他们的消费表现进行数据洞察,如果比大盘表现好,那么就可以进行优化。
但这里还有一个问题需要明确,即什么是高评论的内容?它的标准是评论数量超过 20 还是 100,还是评论率超过 20% 等,需要明确清楚,因为不同标准的表现也不同。
假设确定完高评论的标准后,还要看符合标准的内容到底有多少,比如要召回的评论数量要大于 200,那大于 200 的内容到底有多少,如果只有 20 条,那这样排序是否还有必要?
经过以上指标拆解和数据洞察,就能大概判断改变策略之后的效果。
案例 2:陌生人交友平台回复率优化
某陌生人交友平台,通过用户的动态匹配提高用户沟通成功率,从而帮助用户建立关系。具体来说,这个动态匹配的过程大致分为五步:
第一步,系统以男用户的身份给女用户发送一条消息;
第二步,消息曝光,女用户看到消息;
第三步,女用户回复该条消息;
第四步,男用户看到女用户回复的消息,即回复的消息被曝光;
第五步,男用户回复这条消息。
为了提升双向沟通的概率,通过对这个链条进行漏斗分析,发现在第二步的漏斗转化率偏低,即大部分女用户都没有看到这条消息。
通过数据洞察发现:
- 系统为女用户推荐男用户时,女用户大多数都处于未登录状态
- 用户平均使用 APP 的时长为 15 分钟
基于这样的洞察,提出策略优化方案:召回最近登录时间在 15 分钟之内的女用户,即给最近登录时间在 15 分钟之内的用户发送系统默认消息。
有了这个迭代策略后,随后随机抽取 25% 的用户进行 1 天实验观察。通过实验组和对照组效果对比,发现第二步的漏斗转化率有明显提升。
为了继续优化第五步/第一步的转化率,按小时查看最终转化率发现:下午的转化率明显下降。
此时,通过数据洞察发现:
- 由于推荐策略中限制了每个女用户最多只能收到 50 个男用户的推送,而上午已经完成 50 个用户的推送,因此下午没有新的男用户可推荐给女用户
- 女用户 push 次数与第五步成功率成正比
于是,可提出策略优化方案:15 分钟内最多只推 5 个男用户,并取消 50 个推送限制。接下来,随机抽取 25% 的用户进行 2 天实验,经过实验组与对照组效果对比,发现策略调整后全时段回复率均有提升,达成预期。
总结起来,进行个性化策略迭代的方法论是:首先根据数据洞察得到策略迭代的方向,进行 A/B 实验,再基于试验结论进行正向和负向归因。
























