美林技术专家团队 | 大数据分析工具构建智能监测与异常预警

前言:
微服务架构在给我们提供强大业务技术支持的同时,给系统运维管理也增加了难度。传统人工系统运维,主要有以下两个弊端:
⇒及时性比较差,大多都是遇到问题才去分析排查;
⇒微服务架构下应用服务之间关系错综复杂,导致问题排查很难精准找到问题点,过程费时费力。
往往等问题出现了再去排查处理,已经对业务流程产生了影响,严重的可能会阻塞生产过程,造成不可估量的损失。因此如何对程序进行持续监测、自动化分析潜在风险,快速通知相关运维人员规避风险,就成了微服务架构体系下一个亟需解决的重点和难点。
本文详细描述了程序监测和异常预警的架构体系设计,包括程序监测分析方法及异常预警范围。
微服务应用程序部署完成后,保障系统能够持续可靠、稳定,需要考虑两方面影响因素:
⇒环境稳定性。如网络连通性、操作系统配置、内存占用情况、磁盘使用率等;
⇒服务健康状态。如Nginx、Redis、Mysql、Nacos、网关等服务,实时监测服务运行状态,通过监测数据分析服务的健康状态。
通过对环境和服务两方面监测分析,可以明确已经发生的异常和潜在的风险,例如环境配置改变、服务器网络不稳定、服务异常下线、服务负载过高等,将这些异常信息通过多种渠道及时通知运维人员,并提供处理建议和方法指引,快速处理异常,保证系统服务正常运行。
因此,程序监测和异常预警就是来保障系统服务持续可用的两大举措,一方面需要对故障和异常及时发现,另一方面及时通知并提供处理措施和方法,及时处理故障和异常。本文将从架构设计及建设内容两个角度出发来阐述所建设的智能监测体系。
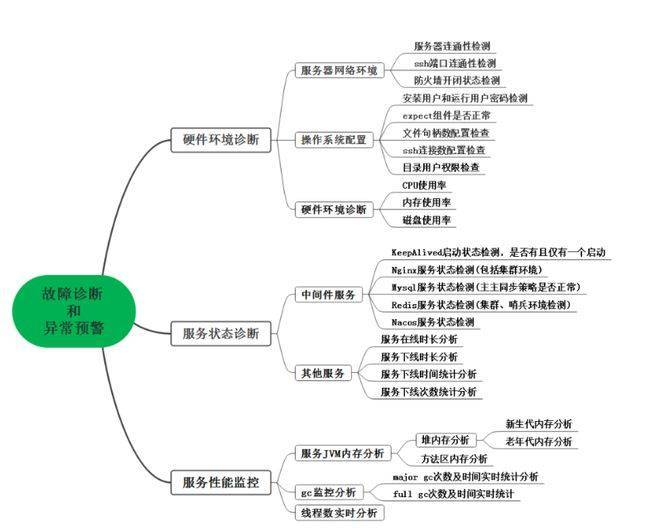 △故障诊断和异常预警导图
△故障诊断和异常预警导图
系统智能监测与异常预警,主要从三个方面入手,分别是:运行环境监测、服务状态监测、服务性能监测。
一.智能监测
▶(1)运行环境监测
程序运行环境的状况关系到微服务架构中的每个服务的运行状态和可用性。运行环境监测主要从三个方面入手:
1)网络环境:如服务器连通性,检查是否有服务器节点是宕机状态或者网络环境有变化导致主机连通性异常,网络连通性异常会导致服务不能注册到Nacos中或者服务访问不到;
2)系统配置: 操作系统配置往往会影响智能运维平台自身功能的使用,如用户名密码被改变了,h2数据库中的密码没有同步修改,会导致远程文件拷贝操作出错;expect等组件缺失会导致shell脚本调用业务失败;ssh连接数、文件句柄数、目录用户权限都会影响文件拷贝的成功与否;
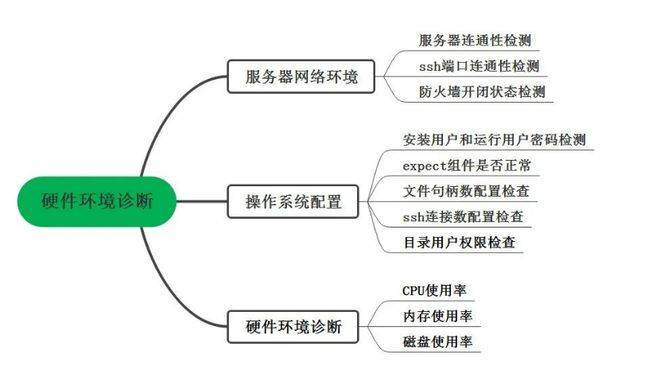 △硬件环境诊断导图
△硬件环境诊断导图
3)硬件资源监控:硬件资源会直接影响服务的执行效率或者直接导致服务不可用,一般从cup、内存、磁盘等方面进行监控。由于cpu、内存、磁盘的使用情况会不断动态变化,因此需要对这些数据进行收集、统计、图表展示,实时监控,通过实时统计,可以分析出来哪台机器的硬件资源比较紧张,如果硬件资源长期处于紧张状态,建议及时处理。比如增减硬件资源配置,或者卸载部分服务,服务迁移等。
▶(2)中间件监测
中间件服务在微服务架构体系中起着至关重要的作用,是微服务产品服务能够正常运行的基础,包括文件共享NFS、代理服务Nginx、内存数据库Redis、关系型数据库Mysql和Oracle、注册中心Nacos、文件传输服务sftp、分布式查询引擎Presto、图数据库Neo4j、文档数据库MongoDB。架构如图中间件架构图所示:
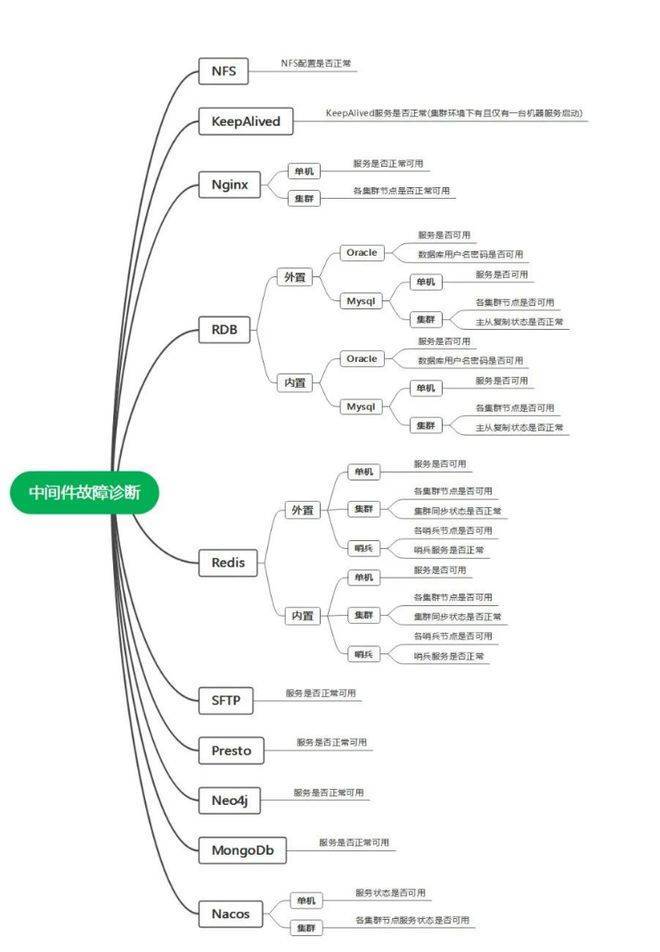 △中间件导图
△中间件导图
▶(3) 应用服务监测
应用服务指的是除中间件外的所有产品服务,应用服务异常监测和分析从三方面入手:服务状态、服务接口及服务性能,具体内容如下:
1)服务状态方面的监控分析:目标是分析出来一些问题,比如主机的服务经常挂掉,由此可以推断出来这个主机性能比较差,不稳定;再比如某些服务在某一天经常挂掉,可能是那一天系统访问量特别大,需要及时采取措施缓解系统访问压力。
2)接口访问监测:主要是捕获执行异常的接口数据,比如响应非常慢的接口,调用出错的接口,哪些接口调用次数比较多等。可能需要存储大量接口请求数据,通过图表统计来可视化反映接口响应情况。
3)服务性能监控:主要是对服务代码运行时数据区的一个动态监测。比如线程数监控、JVM内存使用情况分析、垃圾收集器工作情况等。同样需要动态收集大量时间点JVM各指标数据,以时间维度做数据可视化统计分析。并通过数据分析,及时发现问题。
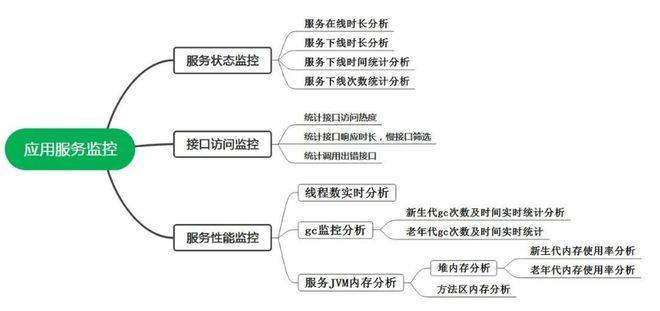 △应用诊断导图
△应用诊断导图
二.异常预警
异常预警智能监测和异常分析的最终目标是及时反馈用户或运维人员,并通过提供的解决措施及方法快速解除异常,让系统在最短的时间内恢复正常状态。
▶ (1)运行环境预警
运行环境异常一般不能系统自动修复,需要运维人员手动处理,比如服务器网络环境异常、磁盘爆满等需要提示出来,运维人员自行处理即可。有些异常需要说明处理措施,比如登录密码改变了,需要同步修改h2数据里面存的密码密文。
▶ (2)中间件预警
中间件异常一般分这样几种情况:集群中某节点服务不可用,集群配置异常(如Mysql主、主同步异常、Redis哨兵异常、Nacos同步异常)。这些异常需要及时提示出来,运维人员线下处理或者通过智能运维平台提供的功能进行处理。
▶ (3)应用预警
应用异常故障分为三类:服务状态、接口响应情况、服务性能。
1)服务状态,指的是应用服务的启停状态,比如某个应用服务挂了,提示出来即可,运维人员可以通过智能运维平台的功能或者后台启动服务即可。但是更为重要的是需要通过长时间监控分析出来哪个主机的哪些服务经常掉线,哪些时间段经常掉线等。
2)接口响应预警,是通过大量接口响应时间数据,过滤出经常响应比较慢的接口,这些接口应该及时反馈给开发人员进行接口性能优化。
3)服务性能状态指的是服务所在的JVM实例中资源使用情况,比如老年代内存快满了,需要提示出来,及时调整JVM资源配置参数或者重新启动服务。
通过智能监测和异常预警,提高系统运维效率,减少系统故障率,可以让用户在体验微服务架构的便利性的同时,让系统运维工作更加轻松,不断提升用户体验。
美林数据——释放数据潜能,激发企业活力
为你带来最新大数据资讯
欢迎关注与评论!




















