【数据挖掘算法分享】机器学习平台——回归算法之随机森林

关注
随机森林回归算法是决策树回归的组合算法,将许多回归决策树组合到一起,以降低过拟合的风险。随机森林可以处理名词型特征,不需要进行特征缩放处理。随机森林并行训练许多决策树模型,对每个决策树的预测结果进行合并可以降低预测的变化范围,进而改善测试集上的预测性能。
算法思想
随机森林是决策树的组合,将许多决策树联合到一起,以降低过拟合的风险。
随机森林在以决策树为机器学习构建 Bagging 集成的基础上,进一步在决策树的训练过程中引入了随机属性选择。具体来讲,传统决策树在选择划分属性时, 在当前节点的属性集合( 假设有 d 个属性) 中选择一个最优属性;而在随机森林中,对基决策树的每个节点,先从该节点的属性集合中随机选择一个包含 k 个属性的子集,然后再从这个子集中选择一个最优属性用于划分。 这里的参数 k 控制了随机性的引入程度。若令 k=d ,则基决策树的构建与传统决策树相同;若令 k=1 ,则是随机选择一个属性用于划分。
随机森林回归的过程如下:
►对训练集进行有放回随机抽样以获得p个样本形成训练集的一个子集作为新的训练集;
►当每个样本有K个属性时,在决策树的每个节点需要分裂时,随机从这K个属性中选取出k个属性,满足条件k<K。然后从这k个属性中采用方差来选择一个属性作为该节点的分裂属性;
►决策树形成过程中每个节点都要按照步骤2来分裂。一直到不能够再分裂为止,利用该子集训练一棵决策树,并且不对这个决策树进行剪枝;
►按照步骤1~3建立大量的决策树,直至训练出m个决策树;
►把测试样本给每棵决策树进行回归预测,统计所有决策树对同一样本的预测结果,所有的结果的平均值作为最终预测值。
随机森林算法的很好的利用随机性(包括随机生成子样本集,随机选择子特征),最小化了各棵树之间的相关性,提高了整体的性能。
数据格式
►必须设置类属性(输出),且类属性(输出)必须是连续型(数值);
►非类属性(输入)可以是连续型(数值)也可以是离散型(名词);
参数说明
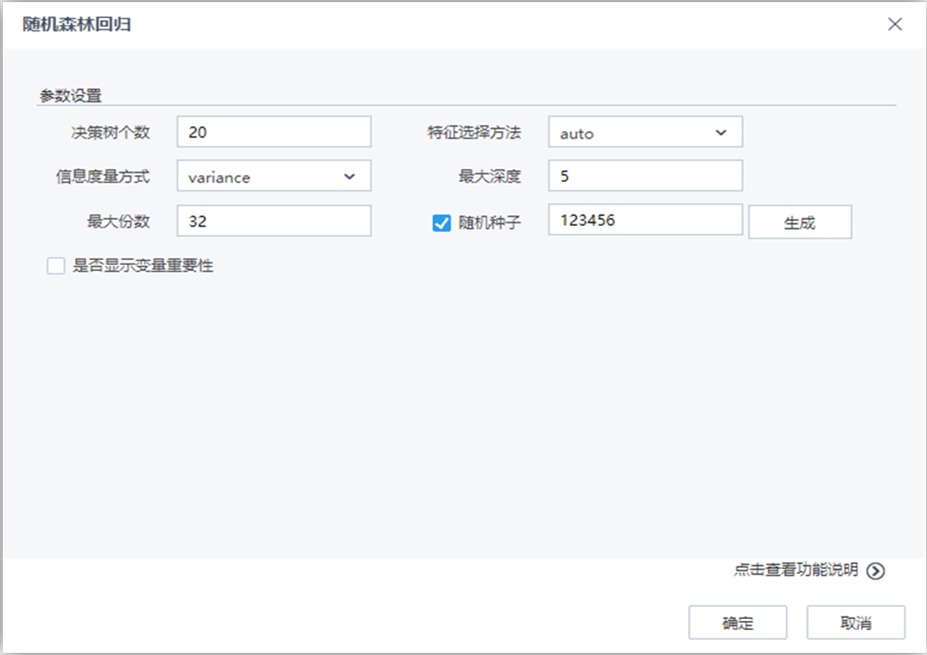
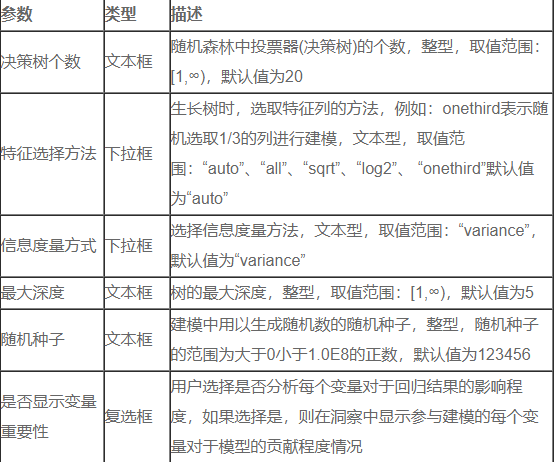
结果说明
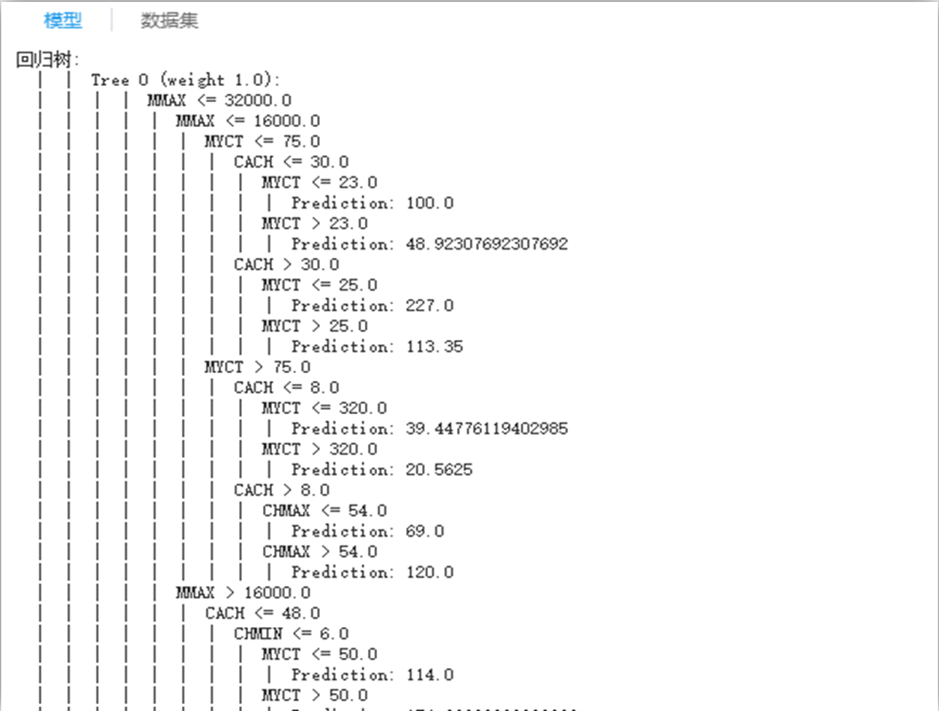 生成的决策树
生成的决策树
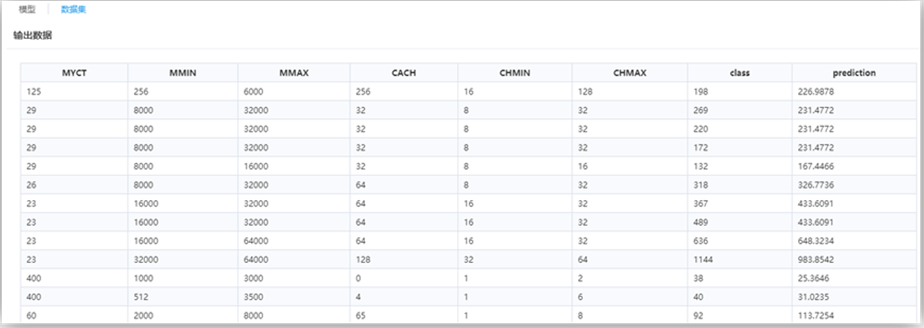
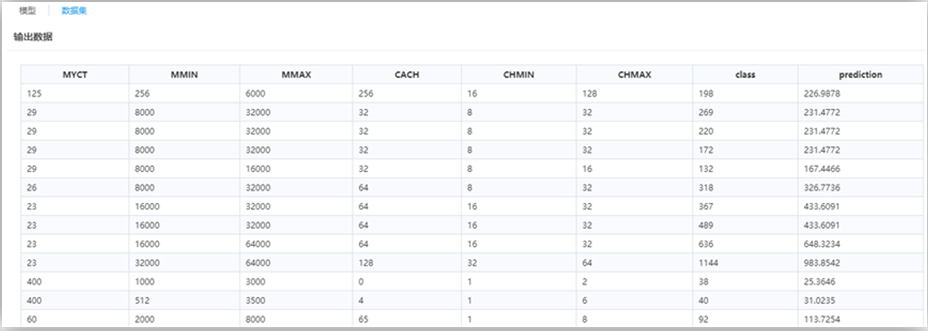 最后一列属性“prediction”为回归预测列。
最后一列属性“prediction”为回归预测列。
构建如下流程:
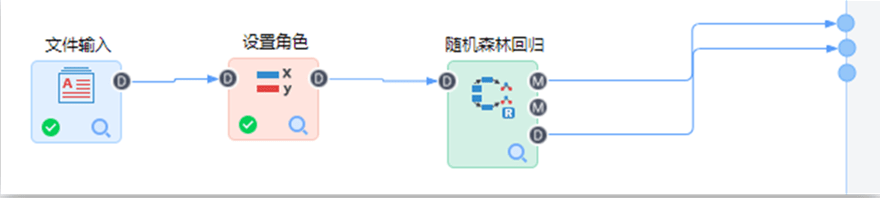
【文件输入】节点配置如下:
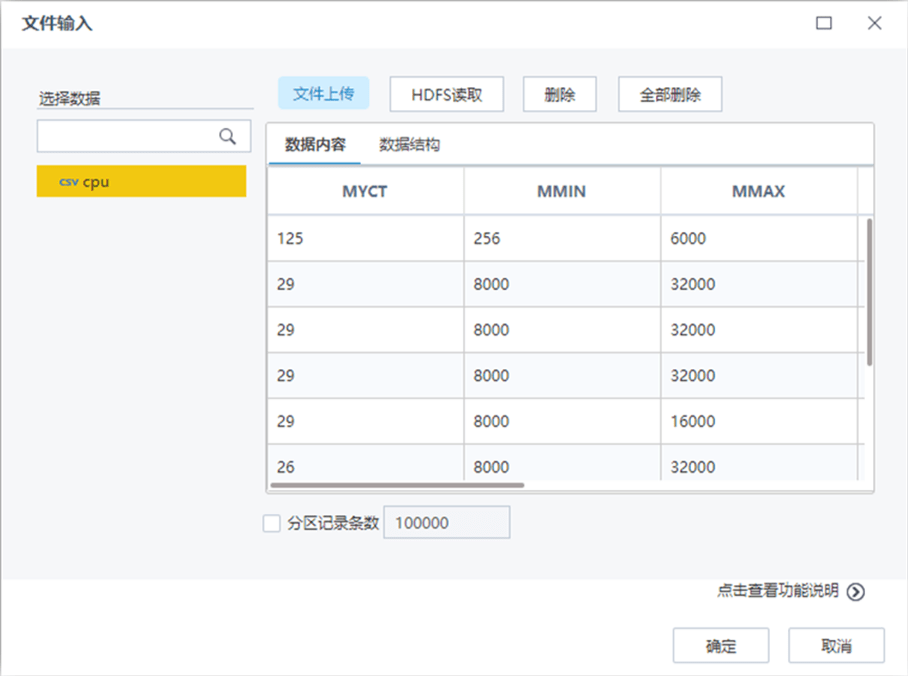
【设置角色】节点配置如下:
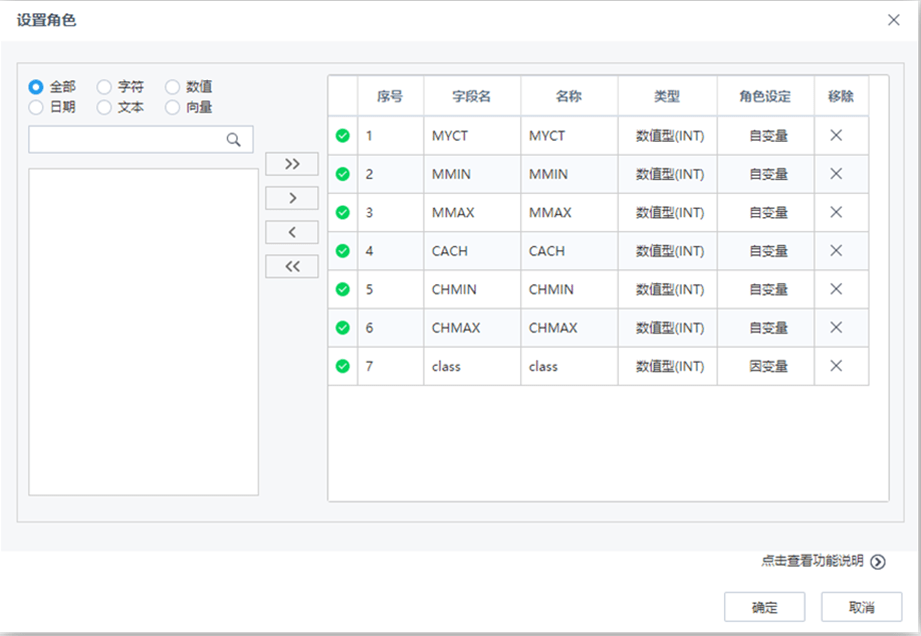
【随机森林回归】节点配置如下:
流程运行结果如下:

美林数据——释放数据潜能,激发企业活力
为你带来前沿最新大数据资讯
欢迎关注与评论!

美林数据技术股份有限公司
+
关注



0
2条点评
咨询产品
免费试用
面向企业级用户的一体化大数据分析平台
客户案例
暂无
















