ChatGPT4的超高“智力”,依靠什么来养成?

在ChatGPT的GPT-3.5推出的第105天之后,它的新“大脑”GPT-4已经把美国的模拟律师资格考试考到前10%了,并且顺利的在美国高考题(SAT考试)中,拿到了进入哈佛大学的成绩。
ChatGPT怎么变聪明了?依靠的是什么?
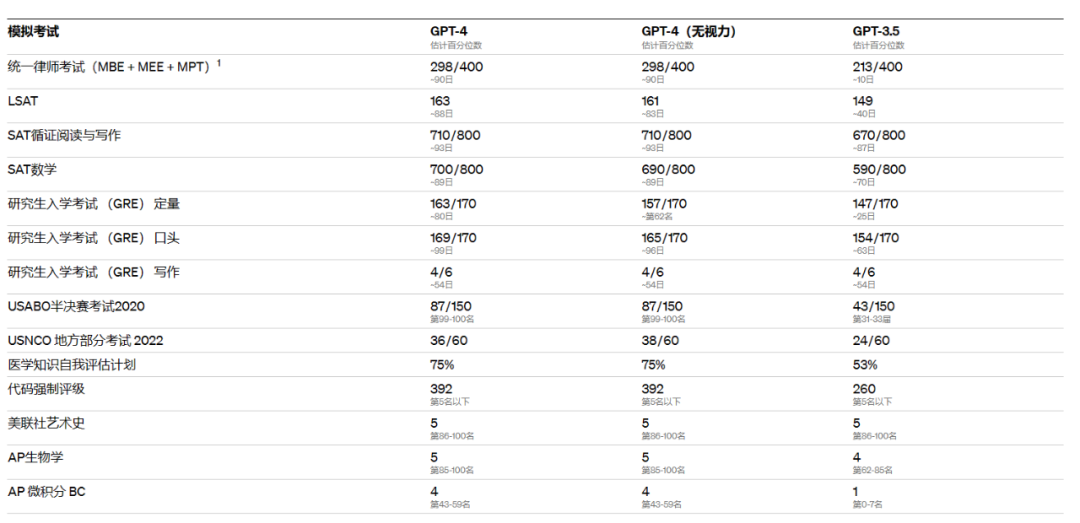
GPT-4的成绩单(图来源于网络)
今天A君想要和大家简单聊聊,关于ChatGPT的“大脑”运作的关键。
ChatGPT中被大家关注最多的语言能力,其实就是GPT的语言模型。最近新推出的GPT-4,就相当于这个AI的“大脑”。
而这个新的大脑要比GPT-3.5的更加“大”,单词输出限制提高到了25000个单词。“神经元”(计算系统)更多,能计算识别更多的文字内容,甚至是图片内容,所以“智力”也就更高。
当ChatGPT的“大脑”工作时,大脑中的“神经元”就会运作,也就会产生数据参数,而更多的参数产生,往往就会带来更精细的结果。

普通计算机处理数据的CPU(图片来源网络)
2018年的GPT,参数量是1.17亿。
2019年的GPT-2,参数量是15亿。
2020年的GPT-3,乃至后来基于GPT-3.5的ChatGPT,参数量是1750亿。
2023年最近发布的GPT-4,虽然官方没有公布具体参数量,但一定是千亿级别的参数量。
当我们在和AI进行互动且抛出问题的时候,屏幕那边的ChatGPT,是怎么做这道题的?
比如我们在对话框里问AI:“AI的智力是什么水平?”
作为一个人工智能,ChatGPT从一开始答题的思路,会和我们一样:先看问题。
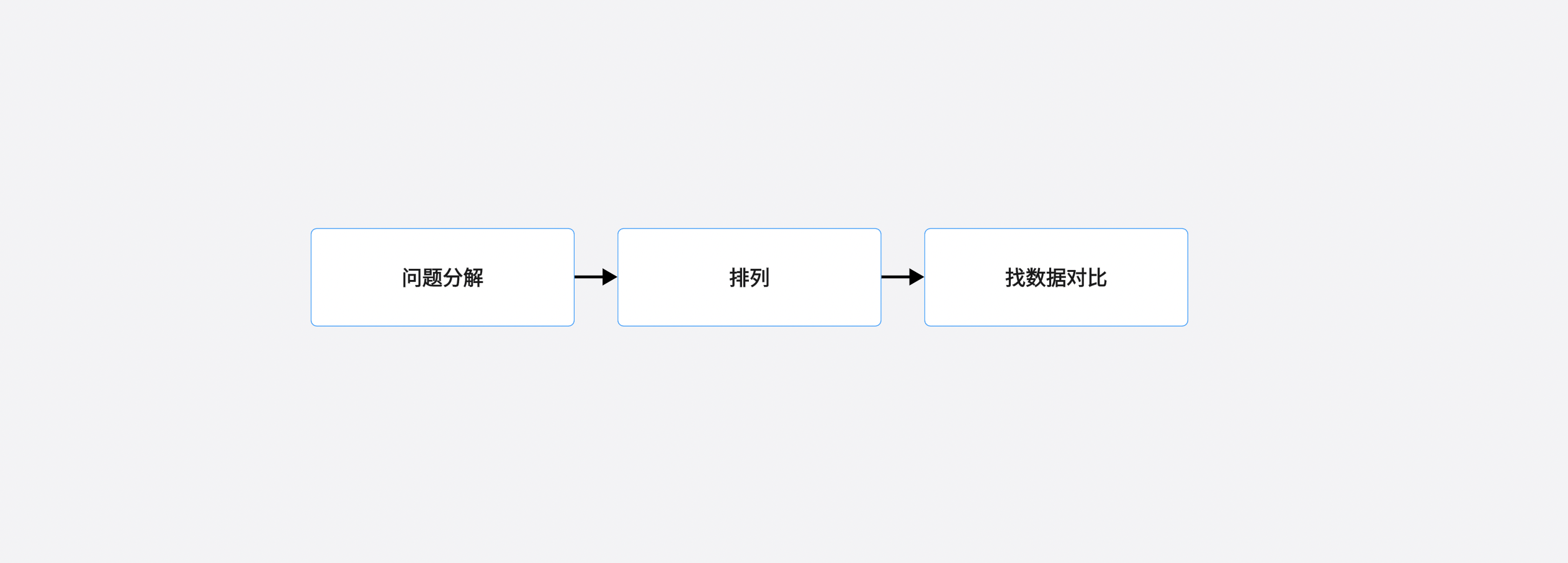
但是看完后,它会把这个问题分解、排列。再去网上抓数据对比,看看都有哪些地方出现了“AI的智力”相关的内容。
同时再用它那上亿个参数的“脑子”分析计算,正确内容的可能性。把所有搜集到的数据,根据上下文,进行新的排列、组合,最后把概率最高的答案选出来,在对话框里回复你。
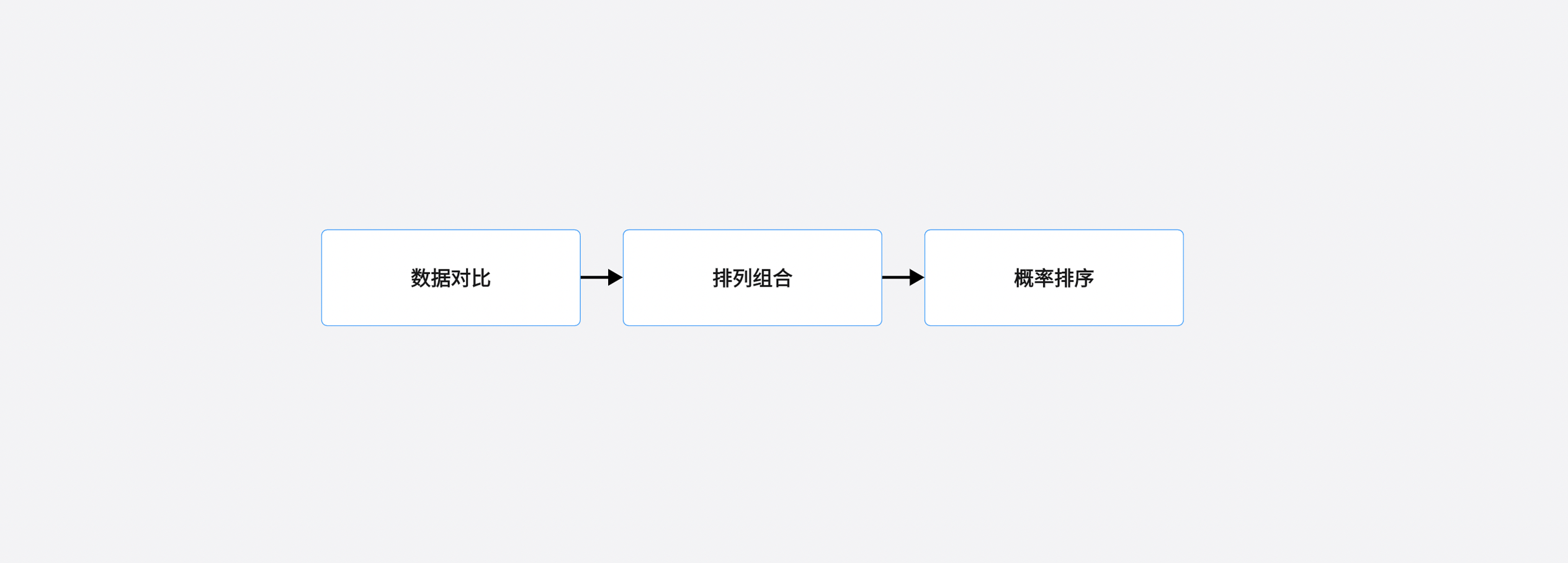
所以你以为人工智能在利用它的智慧回答你,其实它在用它的“体力”来回答你。
在一个足够大的数据库中,它会用最快速的方式,把可能性最高的答案找出来。
所以一个聪明的AI,一定是能在单位时间内,做足够多的事情。(AI比人卷太多了)
而人干一天活,消耗三顿饭,AI干一天的活,要消耗多少的算力?
简单来说,当AI的那颗上千亿级别参数“大脑”运转起来的时候,可能要花掉北上广深的几套房子。(全是钞能力)

一些服务器的样貌(图片来源网络)
比如Open AI,微软专门为其打造了一台超级计算机,用来在公有云上训练超大规模的人工智能模型。其中这台超级计算机拥有28.5万个CPU核心,超过1万颗GPU。
以目前比较主流的英伟达A100芯片为例,一颗价格约8万元。每颗8万元,一共要1万颗,光是芯片的花费,就在8亿元以上。
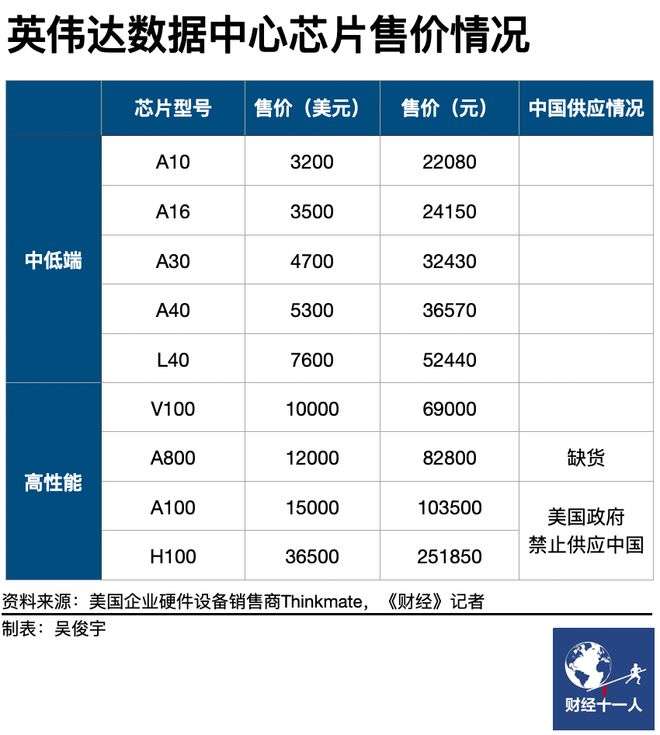
图片来源网络
所以初步估算,要达到相应的算力,训练一次的成本:以GPT-3.5为模型的ChatGPT模型,都要460万到500万美元。
在国内,云计算技术人士公认的一个说法是,1万枚英伟达A100芯片是做好AI大模型的算力门槛。
据OpenAI测算,自2012年以来,全球头部AI模型训练算力需求3-4个月翻一番,每年头部训练模型所需算力增长幅度高达10倍。
但,与此同时,这种算力快速的增长的需求也必将对传统的摩尔定律形成冲击:
摩尔定律认为:芯片计算性能大约每18-24个月翻一番,因此两者间的不匹配势必将带来对算力基础设施需求的快速增长。
相比之下,AI算力需求主要拆落到训练和推理两个主要方面:
1、训练方面:根据OpenAI训练集群模型估算结果作为参考,1746亿参数的GPT-3模型大约需要375-625台8卡DGX A100服务器(对应训练时间10天左右),对应A100 GPU数量约3000-5000张。
2、推理方面:以A100 GPU单卡单字输出需要350ms为基准计算,假设每日访问客户数量为2,000万人,单客户每日发问ChatGPT应用10次,单次需要50字回答,则每日消耗GPU的计算时间为972,222个运行小时,对应的GPU需求数量为40,509个。
而这一切,还没有包括每天都要用掉的几万美金电费,和线下需要购买“机房”的成本。比如算力和数据的成本,就要近20亿元人民币。
而GPT-4, 作为“更聪明”的“大脑”,算力成本又是一个新的台阶。这些,全部都是“聪明”的价格,也是使用高性能计算要付出的成本。
最后提一嘴:我们青椒云云桌面,也可以用来做AI“大脑”的部署,所以青椒云桌面=半个AI“大脑”,使用青椒云=使用“人工智能” 哈哈哈哈哈哈哈哈哈~























