 AI测评网
AI测评网
干货分享|基于实时图技术的信用卡申请反欺诈应用

本文整理自普适智能 CTO 刘元弘在《图创价值·图+AI在金融行业的应用实践》的现场分享,一起来看看图数据库在信用卡反欺诈场景的应用与优势。
常见的信用卡欺诈风险主要包括欺诈申请、伪卡盗刷、套现等。其中,信用卡申请欺诈通常指犯罪分子使用不正当手段进行信用卡申请、为获得信用额度伪造申请信息、冒用他人信息申请信用卡,或申请人信息真实但恶意骗取信用额度不还。
在信用卡业务实践发展过程中,欺诈申请的金额损失往往在欺诈损失案件中占据了非常大的比例,因此欺诈申请识别,是所有信用卡发卡机构风险管理的一个重要组成部分。

随着近些年金融线上化和渠道化的发展,信用卡申请欺诈逐渐呈现出两大发展趋势:
一个是犯罪分子集团化,越来越多欺诈是有组织的犯罪团伙行为,团伙案件对银行造成的金额损失大、而且盗用信息还对银行声誉造成较大范围影响;另一个是欺诈手段专业化,犯罪团伙的欺诈手段越来越专业化,为了保证申请提交率和申请通过率,在批量申请时,对申请信息、申请设备等进行专业包装,加大了银行反欺诈的难度。
在新发卡贷前审批反欺诈策略中,常见的做法是查询申请人的人行征信、工商信息、学历信息等,在自动化审批环节对一部分还款能力和还款意愿较好或较差的申请人进行通过或拒绝,剩下的部分流转至人工审批。常见的流程如下:

在这个过程中,金融机构往往需要处理大量的申请信息和用户数据,同时还涉及到人工审核效率及准确度的问题,因此需要我们搭建一套更智能且具有实时性的智能反欺诈系统来帮助金融机构实现更高效、更精确的新发卡贷前审批。
为什么用图技术进行新发卡反欺诈
基于业务背景的介绍,传统的信用卡审批流程中所使用的数据主要是统计学原理的规则或者模型,更多的是针对独立个体的分析挖掘,但是当个体的特征稀疏时,则难以对个体做出全面有效的判断。
特别是现在随着欺诈手段呈现多样化、专业化、团体化等特征,传统的专家规则和机器学习模型对通过多层关系进行掩饰的复杂欺诈手段或者团伙欺诈难以识别。
另外,由于目前发卡、运营、催收等各个环节的数据之间缺少必要的逻辑视图和交叉校验,容易导致金融机构信息割裂,没有统一的框架和视图描述客户的信用卡业务全生命周期,使得风控决策/人工审核时缺少必要的数据支撑。
而图技术具有将实体间的复杂关系直观展示并纳入模型学习的特性,能够为信用卡业务真实性审核提供更多维度的分析技术手段,恰好能弥补刚刚提到的传统反欺诈手段的这些短板。

图在新发卡反欺诈场景中的应用流程
首先是用户发起进件流程,用户申请进件后信息会进入到进件中心,进入进件中心的同时,系统会做两个事情,一个是走实时流,另一个是离线流。
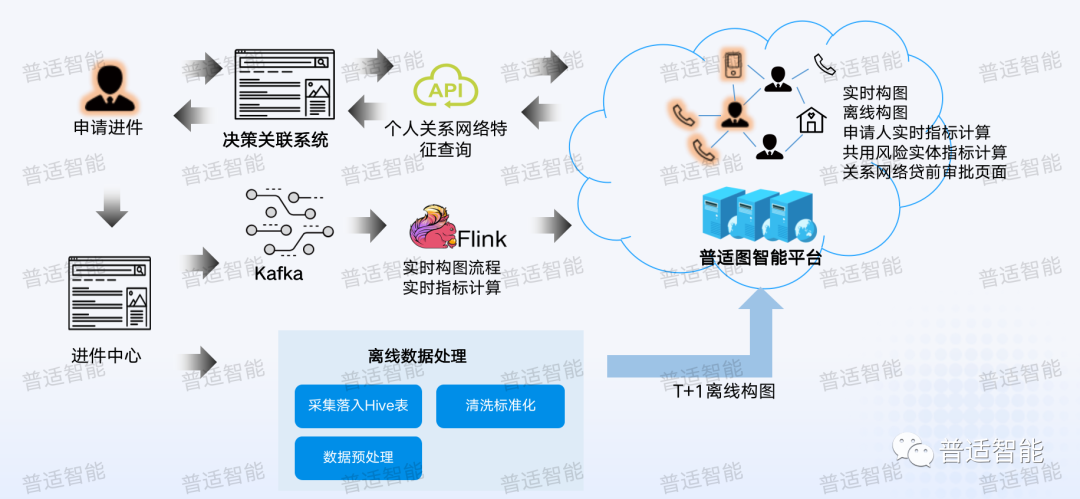
- 实时流
如果按照传统走批的数据处理方式,可能第二天才会发现一些欺诈或作弊行为。像我们之前碰到有个团伙10分钟之内提交了100多张新发卡申请,通过实时流是有可能在他们申请前几张的时候就把它拦截下来,这就是实时的必要性。
走实时流,我们会让进件中心把数据写入到 kafka 里,然后通过一套实时引擎去监听kafka,一旦监听到有用户提交进件,接下来就用我们的图平台快速地配置各种各样的规则和指标,快速地用图引擎扫一遍所有的指标来看看有没有命中,并把结果写入到消息队列中,然后提供给下游的一些决策系统进行消费,同时会提供 API 给其他业务部门进行调用,帮助业务人员进行关联决策。
- 离线流
除了走实时通道,我们也使用离线数据处理通道,就是下面的流程会进入到底层数仓,然后走Hive去进行T+1的离线构图,主要是防止实时流程中存在数据冲突,我们可以通过离线进行校验,之后再去进行整体更新。
所以我们实际在帮客户做图的时候,并不是静态图,或者每天更新一次的一个流程。我们一般会起多个流程,包括实时流,各种全量的离线流,去保证我们图库数据处理的及时性和有效性。
如何构建新发卡欺诈的图谱
首先是本体模型,里面分为「点」代表的实体类型和「边」代表的关系类型。实体类型包含个人、信用卡申请进件、公司、地址、联系电话、设备号、地址、网格化坐标、车牌、营销员、代理人等实体;关系类型则主要包含父母、子女、担保人、家庭住址等关系的本体模型。
我们构建图谱的数据来源主要是多个业务线的客户数据,以及客户标签数据,另外包含一些外部数据。拥有丰富的数据源,一方面提高网络的关联程度,另一方面丰富实体的属性,能够为关系网络特征挖掘提供良好的数据基础。
利用图技术的反欺诈应用
我们常用的图的反欺诈分析主要通过四大类型完成,包含图规则校验、图指标分析、社群分析和图机器学习。
一、图规则校验 所谓“图规则”本质上是一段判定的逻辑,这段逻辑是基于本体模型构建一个复杂图的拓扑结构来进行表示和使用。业务可以使用图规则功能,快速实现复杂关联欺诈逻辑的可视化开发,校验申请人提供的信息和数据库中数据是否一致或不一致。
以下图为例,我们看到图1这个人和另外一个人是关联的,它们同时关联同一个电话和工作地址,所以我们就可以去构建这种图的规则,然后去做一些规则校验。比如图1可能表示工作地址相同,电话是相同的,代表他填写的信息是有效的。
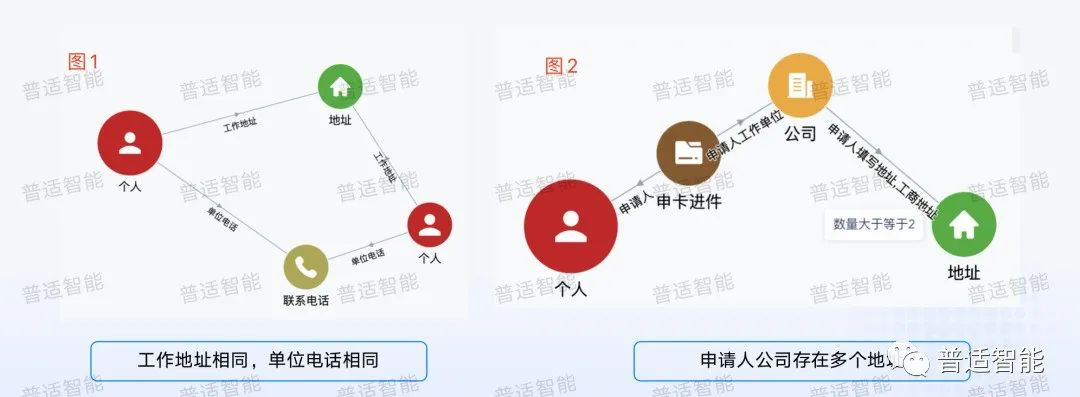
再看图2,右边红色的点代表一个人,这个人申请了一张信用卡,他填写资料后又拉出了一个地址,地址的条件数量大于等于2,也就是这个人一张申请卡,却存在两个不同的地址,这对风控来说也是比较有效的指标。
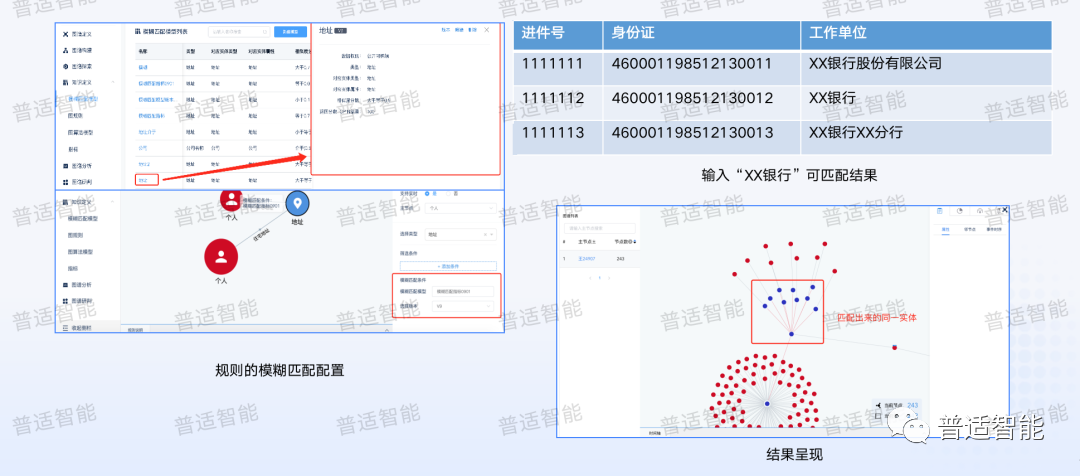
能把图规则做好,尤其是在银行,重点在于两个数据维度,一个是企业的维度,另一个是地址的维度,但是金融用户一般有个痛点,就是每个人填写信息时,每次填写的地址不一定是一样的,以前很多引擎没办法准确判断这两个地址是否是同一个。
为了强化反欺诈引擎的效果,在图规则引擎之中引入了文本相似度算子,我们早期做过一些NLP的东西,所以我们把一些NLP尤其是关于地址对齐和企业名称对齐的类型,构建了自己的算法,把这个算法加入到了模型中,它就可以配置一些更有意思的东西,比如:我个人关联的地址,关联的同事A、同事B、同事C等等,我们的地址可以填的不一样,有的填了路,有的没有填路,有的填了区,有的没填区,其实这个很常见的,那我们就可以把所有填写不同的地址聚合到一块,去构建一些高质量的规则,帮助业务构建更强大的欺诈校验能力。
地址和企业对齐准确率经过大型股份制银行的业务校验,准确率在98%以上。
二、图指标分析
图指标其实和原本的指标体系是完全一样的,只是构建这个指标时会有几个特殊点,通过维度、标签、客群。逻辑就是先构建一个有效的关联性,常用的一些构建关联性的维度包括:同一单位、同一家庭、同一设备、同一LBS、同一联系方式、同一推荐人、同一亲属等等,这就是我们说的关系维度。

我们会在关系维度上增加一些标签,比如:用左边和右边关联放到一块,我们就可以构建成一个有效的规则。
举例:
「同一单位」(左)关联出的人在「黑名单」(右)的一个数目
「同一家庭」(左)关联出了「申请被拒绝」(右)的情况
「同一设备」(左)关联出其他人「逾期」(右)的情况
我们就可以把这些信息全部组合起来,结合我们自己的一个考虑,用维度关联右边这种常用的标签和指标,构建一些有效的规则和逻辑,从而识别资料异常的申请人,或申请人关联的特定客群。
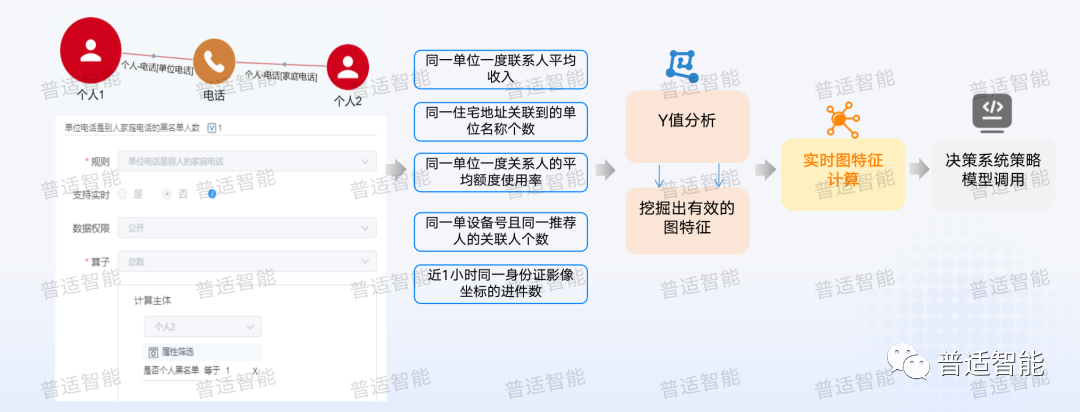
我们在用图的过程中,规则是全局的,需要有业务经验,所以这种方式还是有缺陷的。我们常用的规则是强关联关系的维度,比如:「电话设备」,很难出现一个电话被很多人使用的情况。但在平时采集的数据是有很多的弱关联,也是很有效的维度,比如:「WiFi 设备」,几个人同时接入到相同的 WiFi设备,并不能代表他们之间有强关系,但是起码代表有弱关联。可能在一个办公楼,也可能住的是同一个地方。再比如说「IP」也是很典型的弱关联,还有很多其他的弱关联,包括同一个单位,并不能够代表你们就一定认识,尤其是对一些规模比较大的单位,这个时候我们就可以用图算法,通过平台可视化界面构建规则和图指标。
三、社群分析(Louvain)
图算法的核心主要是帮助我们整合一些弱关联,尤其是有像Louvain 这种,在我们紧密相连的大图中,就可以拿 Louvain 去切一些客户圈和客户之间的社群,比如:有10个人,不可能10个人都是单线相连的,A认识B,B认识C,C认识D,Louvain 切出的结果基本上就是A认识B,B认识C,然后A也认识C,这才是Louvain里面跑出来的结果,就可以通过这个算法,再加上边的权重,比如:家庭亲属的关联性设成1,同一IP设置成0.1,再去进行社群的切分,就可以得到业务想要的社区结果。

既然我们用了社区切分算法去得到一个好的社区,社区里面的人必然是紧密关联的,就可以用社区做一些有意思的指标,比如:整个社区进入黑名单的概率是多少,就是所谓的黑名单的浓度,逾期的浓度,业务通过计算不同维度下的客群指标,就可以挖掘可疑的个体。
四、图机器学习
首先图可以帮助我们机器学习去更快速构建特征。在没有做机器学习之前,传统的做法是需要人力把很多特征整合成一张宽表,再传入到建模平台。但是图从本质上来说,就是连接了一张又一张的表,这种表的关联性完全可以通过图进行整合,再去拉取特征(Feature)的时候就可以用前面说的图指标,放到机器学习里面指标就是一个特征(比如:指标是某个人的逾期率为0.6,那0.6是一个数值,但它放到对应的机器学习就是一个特征),拉取的指标就可以作为其中一个特征浓度进行训练。
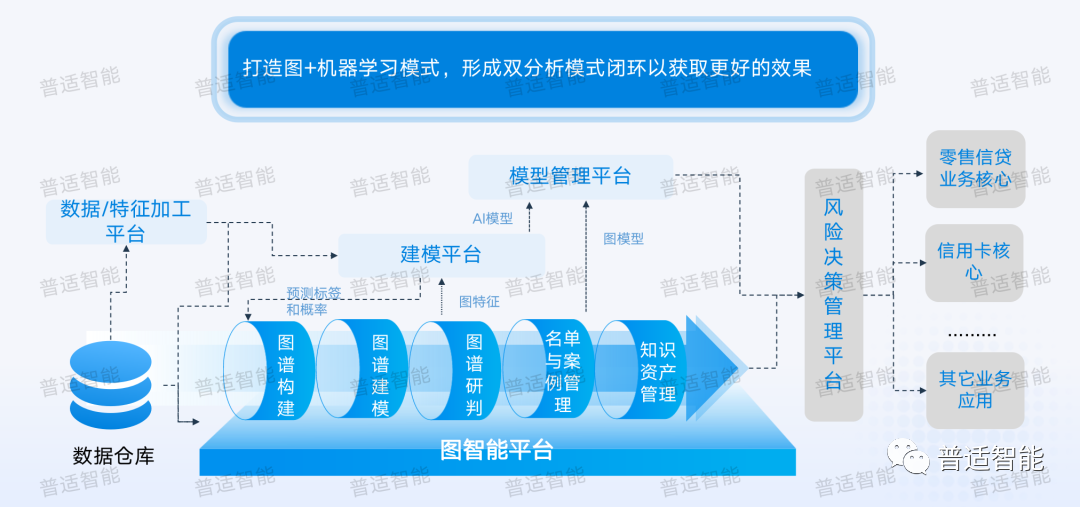
对于我们客户行为来说,或者客户特征特别稀疏的时候。很多企业都会维护潜在客户名单,既然是潜在客户,就可能存在不知道他的姓名,或者说只知道他碎片化的信息,可能他只是点了一个广告或者一个链接,但实际上我们获取到了他的IP,就可以通过图机器学习平台,挖掘有效的特征,在决策系统上部署策略,运用于新发卡实时审批环节。 另外我们还在做一些有意思的事情,我们把机器学习的一些结果放回图里去看。就拿预测VIP来说,模型得出大于0.5,你会认为它是VIP,小于0.5你认为它不是 VIP,如果我们再度回图里,我们给是否是VIP这样的概率,增加一个属性,预测结果放回图里看,就可以识别高概率的VIP客群,高可能的关联圈,这也就是下期我们要分享的【潜在VIP挖掘】的场景应用。
普适的图智能平台在某股份制银行上线后取得了不错的成效。使用图技术,进行实时构网和实时图指标计算,优化决策系统。风控效果提升近3倍,预计每年挽损1000万以上。



















