行业首创 !Graph RAG:基于知识图谱的检索增强技术与优势对比(附 Demo)


身处信息爆炸时代,如何从海量信息中获取准确全面的搜索结果,并以更直观、可读的方式呈现出来是大家期待达成的目标。传统的搜索增强技术受限于训练文本数量、质量等问题,对于复杂或多义词查询效果不佳,更无法满足 ChatGPT 等大语言模型应用带来的大规模、高并发的复杂关联查询需求。
在此背景下,悦数图数据库率先实现了与 Llama Index、LangChain 等大语言模型框架的深度适配并在行业内首次提出了 Graph RAG(基于图技术的检索增强)的概念,利用知识图谱结合大语言模型(LLM)为搜索引擎提供更全面的上下文信息,可以帮助用户以更低成本获得更智能、更精准的搜索结果。目前,悦数图数据库推出的这项技术在与向量数据库结合的领域也获得了相当不错的效果。
今天我们就一起来了解下什么是 Graph RAG 以及它与其他 RAG 技术的对比,也欢迎进入 悦数图数据库 官网,通过 Demo 直观感受这一功能。
在传统的搜索引擎中,检索结果通常是基于关键词的匹配。而随着用户对搜索精确度和词汇联想能力要求的提高,传统的搜索结果往往难以满足用户的实际需求,尤其是在处理复杂的问题和长尾查询时,效果会明显降低。
为了解决这类问题,RAG 搜索增强技术应运而生。RAG (Retrieval-Augmented Generation),指的是通过 RAG 模型来对搜索结果进行增强的过程。具体来说,它是将检索技术和语言生成技术相结合来增强生成过程的一种技术,可以帮助传统搜索引擎生成更加准确、相关和多样化的信息来满足用户的需求。
而为了使搜索结果更精准,RAG 技术仍然面临训练数据和文本理解的挑战:
-
训练数据:RAG 技术需要大量的数据和计算资源来训练和生成模型,尤其是在处理多语言和复杂任务时,但是互联网上文本的质量和准确性是有限的,训练数据的不足会直接影响生成内容的质量
-
文本理解:RAG 需要理解查询的意图,但是对于复杂的查询或者多义词查询,RAG 可能会出现歧义或不确定性,从而影响生成的质量
因此,如何找到更强大的检索增强技术,以更高效率获得更符合搜索者的预期的搜索结果的问题就显得更迫在眉睫。
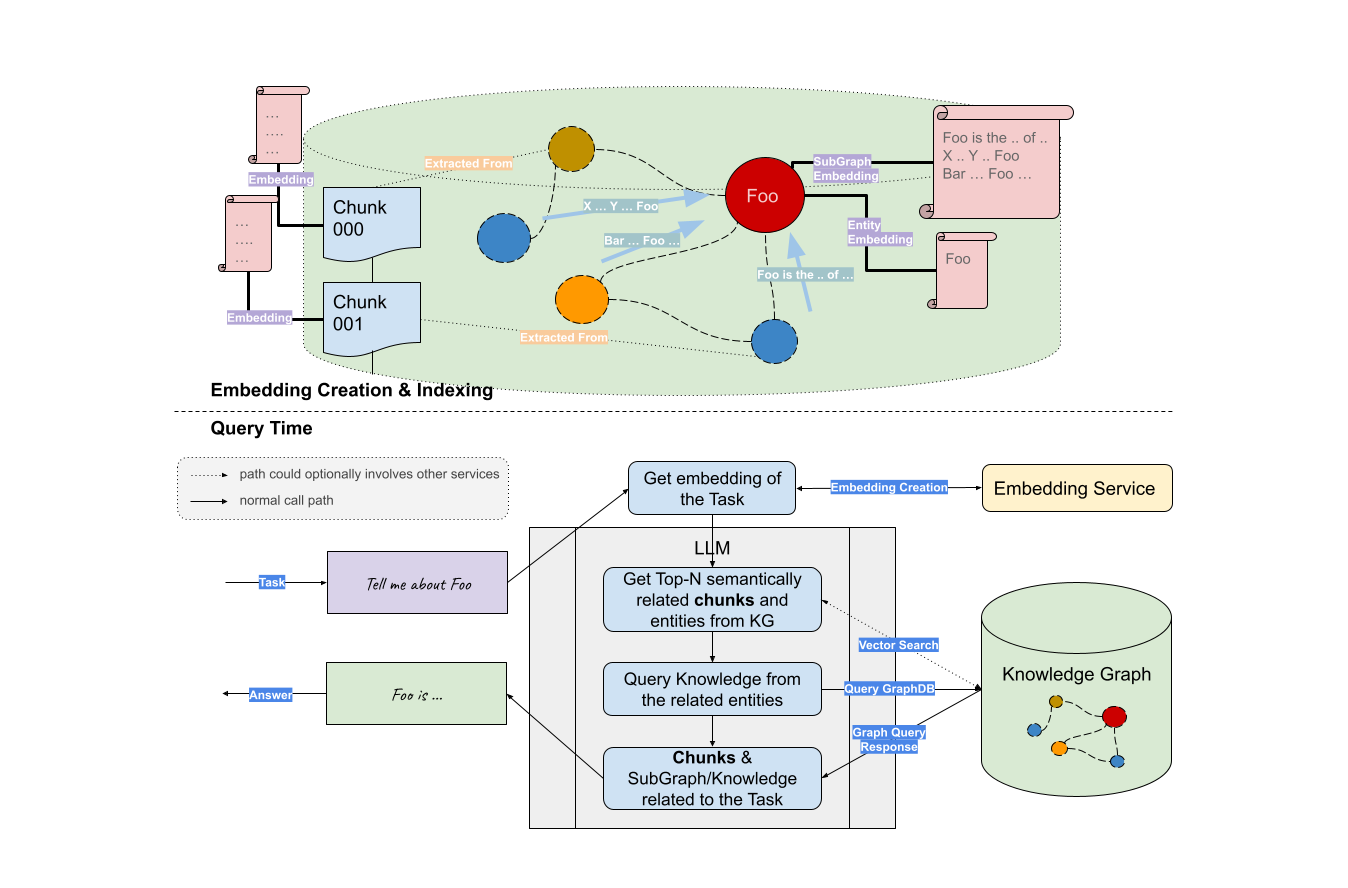
「Graph RAG」是由悦数图数据率先提出的概念,它是一种基于知识图谱的检索增强技术,通过构建图模型的知识表达,将实体和关系之间的联系用图的形式进行展示,然后利用大语言模型 LLM(Large Language Model)进行检索增强。
在之前 和 Llama Index 的直播研讨会 中我们提到,图数据库凭借图形格式组织和连接信息的方式,天然适合存储及表达复杂的上下文信息。通过图技术构建知识图谱提升 In-Context Learning 的全面性为用户提供更多的上下文信息,能够帮助大语言模型(LLM)更好地理解实体间的关系,提升自己的表达和推理能力。
Graph RAG 将知识图谱等价于一个超大规模的词汇表,而实体和关系则对应于单词。通过这种方式,Graph RAG 在检索时能够将实体和关系作为单元进行联合建模,从而更准确地理解查询意图,并提供更精准的检索结果。
下面我们就通过 Demo 演示来直观比较下 Graph RAG 与 Vector RAG、Text2Cypher 这三种检索增强技术的区别和对比——
Graph RAG 与 Vector RAG 的对比
首先是 Vector RAG(向量检索) 与 Graph + Vector RAG(图技术增强的向量检索)的对比。
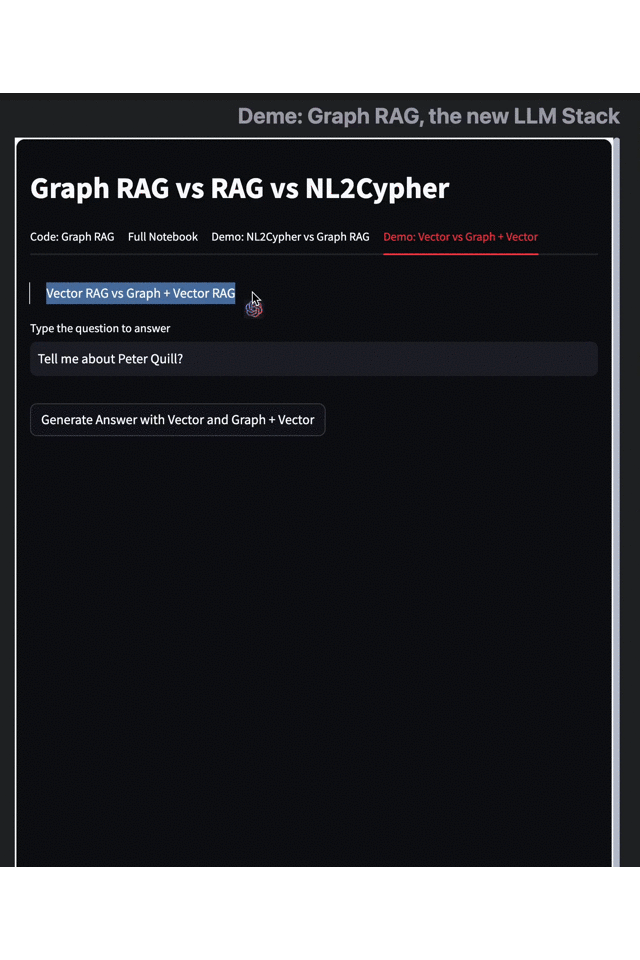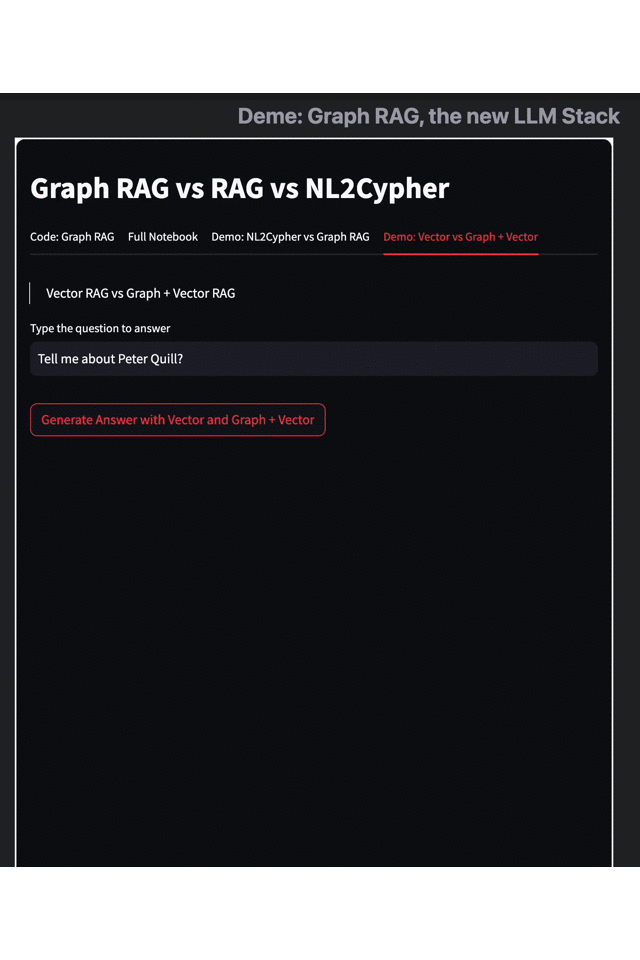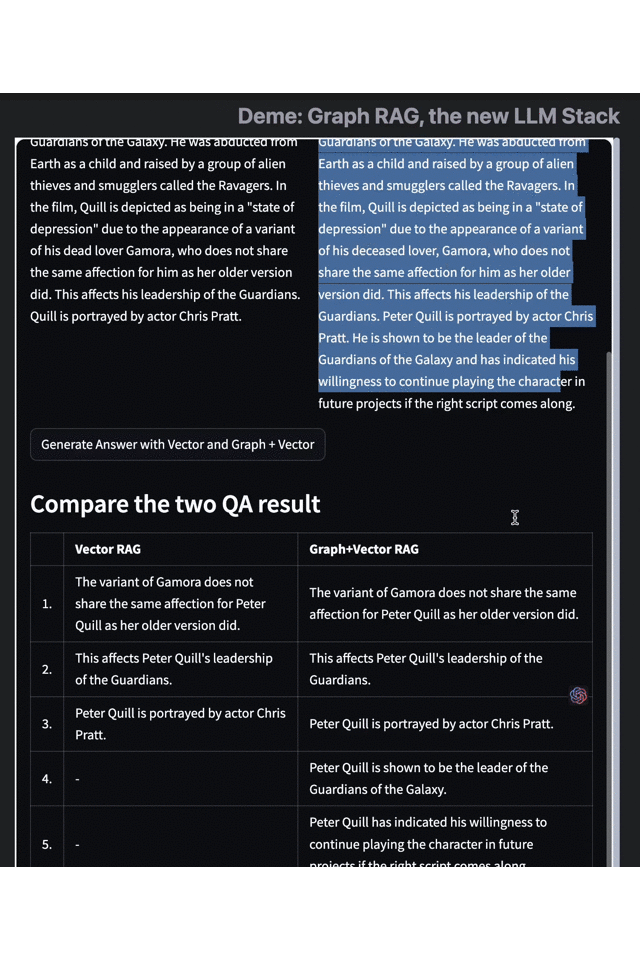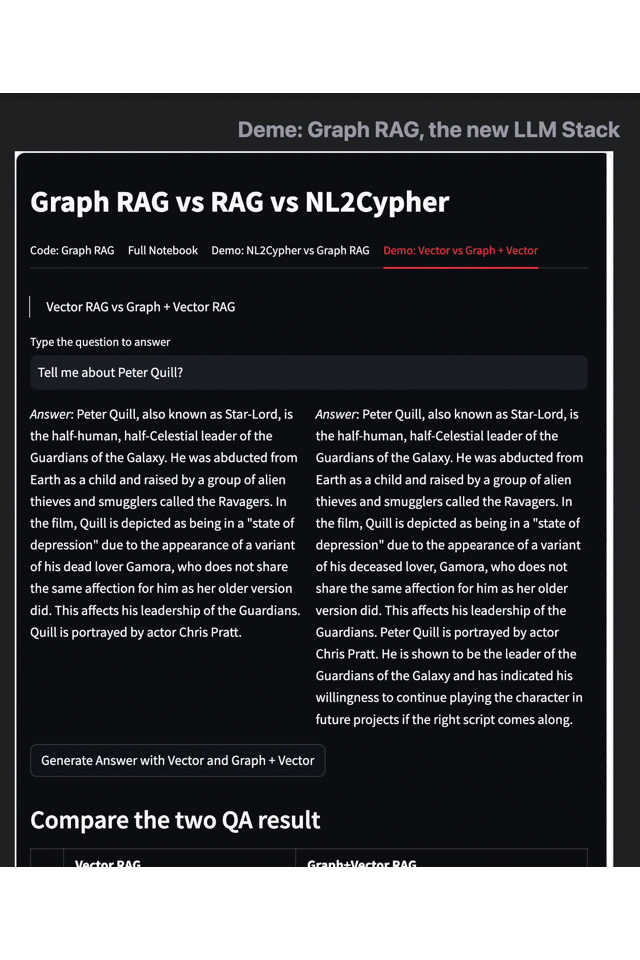
- 左:Vector RAG 右:Graph RAG
以《银河护卫队 3》的数据集为例,当我们询问“彼得·奎尔的相关信息”时,单独使用向量检索引擎只给出了简单的身份、剧情、演员信息,而当我们使用 Graph RAG 增强后的搜索结果,则提供了更多关于主角技能、角色目标和身份变化的信息——在这个例子中我们不难看出, Graph RAG 的方法有效补充了 Embedding、向量搜索等传统手段的不足。
Graph RAG 与 Text2Cypher 的对比
基于图谱的 LLM 的另一种有趣方法是 Text2Cypher,即自然语言生成图查询。这种方法不依赖于实体的子图检索,而是将任务/问题翻译成一个面向答案的特定图查询,和我们常说的 Text2SQL 本质是一样的。
Text2Cypher 和 Graph RAG 这两种方法主要在其检索机制上有所不同。Text2Cypher 根据知识图谱的 Schema 和给定的任务生成图形模式查询,而 (Sub)Graph RAG 获取相关的子图以提供上下文。两者都有其优点,大家可以通过这个 demo ,更直观理解他们的特点:

- 左:Text2Cypher 右:Graph RAG
我们可以看到两者的图查询模式在可视化下是有非常清晰的差异的,基于 Graph RAG 实现的检索明显呈现出更丰富的结果。用户不仅获得了最基础的介绍信息,更能得到“彼得·奎尔是银河护卫队的领导者”、“这个角色暗示自己将在续集中回归”以及角色性格等一系列基于关联搜索和上下文进行推理得出的结果。
悦数图数据库不仅是国内首家提出 Graph RAG 概念的厂商,也率先实现了与大语言模型框架 Llama Index 、LangChain 等的深度适配,因此开发者可以专注于 LLM 的编排逻辑和 pipeline 设计,而不用亲自处理很多细节的抽象与实现,一站式生成高质量、低成本的企业级大语言模型应用。
Graph RAG 技术的出现可以说是为海量信息处理和检索带来了全新的思路。通过将知识图谱、图存储集成到大语言模型(LLM) 技术栈中,Graph RAG 把上下文学习推向了一个新的高度。目前,用户基于悦数图数据库 仅需要 3 行代码就可以轻松搭建 Graph RAG,甚至整合更复杂的 RAG 逻辑,比如 Graph+Vector RAG。
选择相信随着图技术和深度学习算法的进一步发展,Graph RAG 技术在信息处理和检索领域的应用也会越来越广泛。欢迎大家点击【联系我们】获取悦数图数据的免费试用机会,轻松构建您的专属知识图谱应用!




















