大数据流处理架构 | 滴普科技FastData系列解读

在大数据技术发展早期,离线计算(批处理)作为唯一的大数据处理技术,很快在各个场景下取得了惊人成果,吸引了一大批优秀的科学家和工程师,这些因素的叠加使大数据技术快速成熟,形成了以HDFS+YARN+Spark为格局的Hadoop生态体系。
同时,离线计算也成为了大数据的主流技术,但在由Hadoop构筑的离线计算大厦上空,却也飘着几朵乌云,其中一朵就是高延迟。
Hadoop在设计之初便确定了架构目标:高吞吐、高容错、易扩展。而高吞吐和低延迟又在一定程度上对立,因此早期Hadoop在架构上就决定了其高延迟的缺陷,这直接限制了离线计算的使用场景。
而Storm、Spark Stream、Flink等大数据流处理框架的普及,对大数据技术早期的批处理计算逻辑带来了颠覆,解决了高延迟的问题,极大地扩充了大数据处理的使用场景,将大数据处理带到了一个全新的实时计算时代。实时计算的普及再一次推动着技术的进步和人们认知的提升,一些之前离线计算无法解决的低延迟场景开始迅速被实时计算所解决。
然而,在实际情况中,受限于资源性能的因素,很多问题往往需要辅助一些历史数据,因此并不能直接通过实时计算完成。在这些场景下,就要求实时计算需要配合离线计算共同完成某些任务。在这样的背景下,融合离线计算和实时计算的流处理框架应运而生。
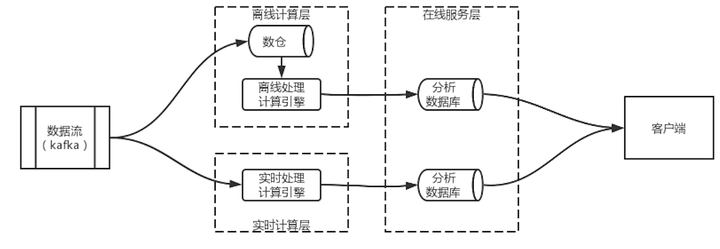
上图展示了一个Lambda架构的示意图,Lambda架构分为实时计算层、离线计算层和在线服务层。其核心思想是事件在被实时计算引擎处理的同时写入到离线计算的存储中,并于在线服务层中合并,得出最终结论。
2.1 离线计算层
离线处理层用于将事件持久化存储到数仓中,并对数仓中的历史数据进行批量计算,将结果保存到分析数据库中。分析数据库不同于持久化的数仓,需要配合实时计算,因此延时必须要低,所以最好选择一些查询速度快的分析型数据库,例如Clickhouse、Elasticsearch等。
2.2 实时计算层
实时计算层在有些文献中也被成为快速处理层,本质上就是用于处理流式数据。这一层的主要职责是提供低延迟的实时计算能力,但由于其能力有限,一般用户计算一个小的时间窗口的增量数据。得出的增量数据会被推送到分析数据库中,或直接触发在线服务层的业务,从而实现实时处理。
2.3 在线服务层
在线服务层可以是业务系统,主要承担合并离线计算和实时计算结果并触发下游业务动作的职责。理论上离线计算得出的历史数据+实时计算得出的增量数据=真实的实时数据。
2.4 案例:智能补货
读者们可以考虑一个门店零售中的智能配补货场景:某连锁品牌鞋店,新上了一批鞋子,需要实时监测鞋子的销售情况,并在合适时机触发补货机制。我们假设一条规则:某个尺码库存数量-过去三个月该尺码日均销量≤1时,触发补货。
在这个场景中,可以将计算分成实时和离线两部分:
离线部分负责每天凌晨统计所有门店过去3个月的销售情况,并将结果写入离线计算的分析数据库中;
实时计算部分负责实时监测当天门店内各个尺码鞋子的库存,将每个销售事件推送到在线处理层;
在线处理层负责接收实时计算层的事件,并读取离线计算的分析数据库来判断规则,最终确定是否需要触发补货机制。
这一案例的规则非常简单,真实世界中的规则会更复杂,但已经能够说明Lambda架构是如何解决需要同时依赖离线计算和实时计算问题的场景。
2.5 Lambda架构总结
Lambda架构的核心逻辑在于,它认为真实结果=增量结果+历史结果。因此,其设计了三个独立的计算层,分别用于计算增量结果、计算历史结果、处理两者的合并。这种架构在很大程度上解决了当数据量太多无法全部实时计算的缺陷。
同时,由于实时计算和离线计算使用两套计算引擎,两套计算引擎的API和抽象都不同,因此原始的Lambda架构也存在着使用和维护难的问题。
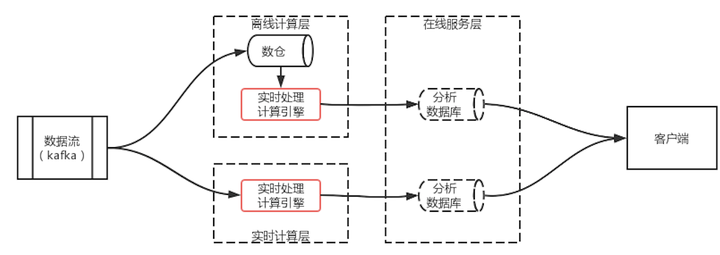
Kappa架构本质上是Lambda的一个变体,目的是为了解决Lambda架构中两套不同的计算引擎导致的使用和维护难的问题。
如图 2 Kappa架构示意图所示,Kappa架构的核心是将两套计算引擎合并成一套。换句话说,要么使用批处理的计算引擎来计算流,要么使用流处理计算引擎来处理离线问题。
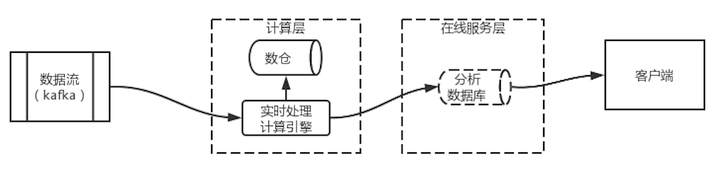
图 2 Kappa架构示意图的架构可以简化成图 3 Kappa架构图中的架构。数据流进入实时处理计算引擎,由实时计算引擎进行运算,将结果保存到分析数据库中,同时将原始数据保存到数仓中。在这一架构中,数仓可以使用对象存储引擎来代替,保存所有历史数据。同时,分析数据库也变为可选。
3.1 极端的Kappa
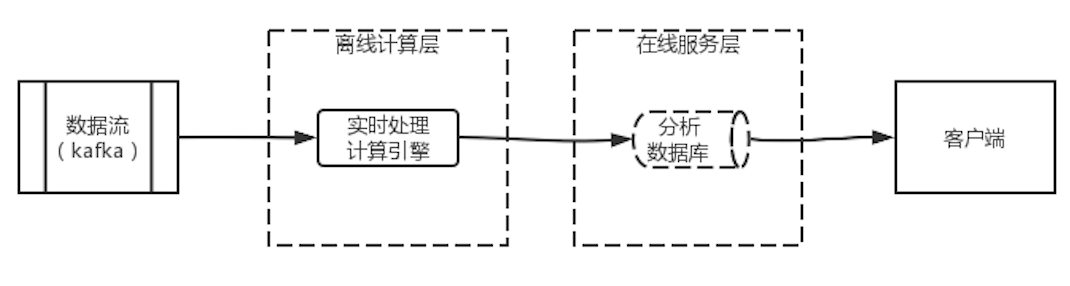
Kappa架构的实际使用中,也有部分企业使用了另一个更极端的Kappa架构的变体。架构图如图 4 Kappa架构变体所示,该变体完全抛弃了数仓,将所有数据都保存在Kafka中。当需要计算历史数据时,对Kafka进行数据重放即可。
这种架构完全抛弃了离线计算,能够降低架构复杂度和维护工作量,但并不适用于所有场景。主要原因在于,此架构在计算历史数据时需要对kafka数据进行重放,而重放的计算效率比较低,会消耗大量的计算资源和时间。因此,若业务需要对历史数据进行计算,就不适合应用本架构。本架构中对历史数据的计算更多的用于偶发错误的纠偏,而不适用于周期或频繁的业务数据计算的场景中。
Kappa可以看成lambda架构的变体。那么为何Lambda架构提出时,没有将两套引擎合并成一个呢?
Lambda架构是由Storm的发起者、Twitter工程师Nathan Marz提出。在实时处理的前期,只有Storm一套实时计算平台,人们对实时计算的认知还处在早期,大家普遍认为实时计算和离线计算就是泾渭分明的两种计算方式。直到Storm Trident的推出,第一次提出了微批的概念,将流计算认为是批处理的特例,因此可以使用批处理的方式来处理流数据。而到了2013年Spark stream的推出,才真正将流处理和批处理都统一到了Spark中。
使用微批处理流数据的优点显而易见,可以将离线和实时统一到一套计算引擎中,这为Kappa的兴起带来了契机,但同时,微批处理的方式也造成了延迟高的缺陷。
而随着人们认知的提升,Flink再次颠覆了人们的认知。与微批思路的不同,Flink将批处理视为流处理的特例,因此只需要实现流处理即可。于是,Flink横空出世,更进一步降低了实时处理的延迟。
纵观流处理的历史,不难发现人们认知的改变带来了技术的变革。在Lambda架构提出的时候,流处理和批处理尚未统一,因此也不难理解为何当时需要设计两套计算引擎。当然,人们认知的改变也并不一定是先进的,即使到现在,Lambda架构依然有着非常大量的使用场景。造成这个现象的主要原因,在于技术的发展并没有能够实现一套架构处理所有问题。目前的流处理技术,对于大数据量的历史数据的处理,还是非常吃力的。
这就对架构师提出了更高要求,一招鲜吃遍天并不适用于架构领域。“没有银弹”这句话在流处理的历史中也频繁展现其威力,那么,作为架构师我们应该如何应对这种挑战呢?
我认为,需要用洞察的视角透过现象看本质。放到本文中,我们再次回到文章开始提到的:在由Hadoop构筑的离线计算大厦上空,却也飘着几朵乌云,其中一朵就是高延迟让我们用洞察的视角再来观看整个流处理的历史进程。
4.1 低延迟与高吞吐的矛盾
文章开头提到了Hadoop设计之初的设计目标是高吞吐、高容错、易扩展。在数据处理领域,高吞吐和低延迟是矛盾的,因此Hadoop在设计之初就无法支持低延迟的实时处理场景。Storm被发明出来解决这个问题,Storm通过全新的架构设计支持了低延迟,但同时也没有逃脱低延迟与高吞吐的矛盾,低吞吐也就成为了Storm的一个缺陷。
微批处理方案的出现,将流数据视为一系列非常小的批组成的集合,一次处理一个微批。这种方案在一定程度上改善了吞吐率。但也在实时性上带来了一些问题,因此其延迟相比较于Storm会变高。
Flink将批数据视为流数据的特例,因此其采用流处理引擎来处理批数据。这也为Flink带来了低延迟的特性,并且由于其具备了处理批数据的能力,因此其吞吐量获得了一定的提高。但看似实现了低延迟和高吞吐同时满足的情况,这其实只是相比较而言的,面对真正的大数据量而言,Flink依旧无能无力,因此在很多场景下依然需要Lambda架构。
其实,无论是Lambda架构还是Kappa架构,本质上就是低延迟和高吞吐之间的选择。在有些场景下,追求低延迟并不需要高吞吐,这种场景就可以选择Kappa架构,其他场景就需要选择Lambda架构。
本文向读者介绍了流处理产生的背景及两种常用的流处理架构,同时向读者剖析了两种架构的本质——低延迟和高吞吐的矛盾,这为读者在未来选择何种架构提供了理论指导。
最后,Kappa架构本质上是一个流批一体架构,关于流批一体更详细的内容,请关注下期专题文章。












