流批一体架构的必要性 | 滴普科技FastData系列解读

上篇文章讲解了大数据流处理架构的技术迭代与演变历程,重点提到Lambda架构。但此架构相当复杂,整体存在三大特点:其一,流处理(speed)和批(batch)处理两套代码;其二,batch 与 speed存在计算结果不一致的情况;其三,两套技术栈,增加运维工作量。而Kappa架构则可以很好地解决Lambda存在的问题,实现了技术栈以及业务代码的统一,但也带来一些新问题。
1. Kappa架构面临的新问题
1.1数据重处理(re-processing data)
比较常见的情况是,处理算法或者Schema发生了变化,或者修了一个bug,这种情况下都需要把新版本的作业重新跑一遍,以获得正确的结果。若只是重跑几天的数据,也不是个大问题。但如果需要重新运行一年的数据,问题就会变得复杂起来。
1.2数据乱序
这一问题在移动App和IoT场景中常见,主要原因是网络延迟或者中断导致数据被延迟送达。如何处理这些迟到的数据,是Kappa架构要解决的问题。
1.3计算成本增加
流式计算相比批计算,虽然开发、维护成本和存储成本降低了,但是可能会占用更多的计算资源,导致计算成本的增加。
1.4 难以支持复杂join
少量的join操作通常不会产生问题,但如果join的维度表数量增加到几十个的时候,使用Kappa就会让开发变得异常复杂。
总体上来说,Kappa架构也不是银弹,无法粗野照搬,必须重新思考业务数据逻辑,结合周边技术架构等实际情况来分析和解决Kappa带来的新问题。
2. Kappa架构新问题的解决办法
结合上节Kappa架构的问题,可以从架构内部、外部两个方面分析和解决问题。Kappa架构的核心特征是事件驱动与实时,尽管周边模块会采用更适合自己的批处理模式或者其他编程模式去处理这些事件,并不一定强求使用流式处理。
在Kappa架构实践中,通常使用Apache Kafka作为核心部件实现。接下来,可以看一下Kafka社区如何解决这些问题的:
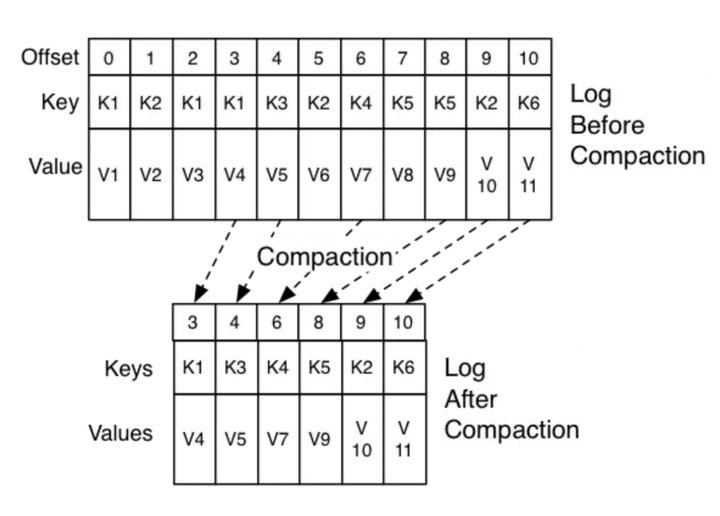
2.1 数据保留(retention):Compacted Topics, Tiered Storage
为解决数据重处理问题,Kafka需要支持时间跨度长的历史事件的回放,其实就是log的存储问题。目前,社区有Topic合并方案(Compacted Topics)和Tiered Storage方案。其中,Tiered Storage被认为是颠覆性的,可惜离发布还有一段时间,大家可参考KIP-405
2.2 数据一致性和可靠性: Exactly-once semantics
流处理引擎需要支持精确一次(Exactly-once)语义保证数据最终一致,同时在集群可控性上,需要支持跨数据中心的集群管理与数据同步。
2.3 处理迟到(late-arriving)数据
流处理引擎(Kafka官方提供了confluent流处理方案)需要完善的状态管理以及配套的Sink,包括重新加载和重放事件的能力。当然,除了Kafka配套的流处理引擎,其他引擎也可以与Kafka一起使用,如Apache Flink。
2.4 数据重处理(backfill)
数据重处理对Kafka集群的计算资源的要求是很高的,灵活的资源管理与调度系统是很有必要的。
2.5 Kappa架构的扩展模块
Kappa架构是以流式处理为基础的,但也不意味着靠一个流处理平台就能包打天下,还需要其他工具或数据库的配合,以共同解决相关的问题。使用合适的工具干合适的事情。例如,复杂SQL需要其他SQL引擎甚至数据库处理。特别是由于Kafka集群管理功能现有的限制,更需要其他工具来配合完成。
到目前为止,我们简单描述了Kappa架构“内核”需要具备的能力,以及Kafka作为内核之一要解决的问题及技术方案。
扩展模块包括应用、数据存储以及分析平台:
- 数据消费组件: 从流处理平台消费数据,需要支持不同类型的消费速率,实时、近实时和批量。
- 存储组件: 内置或者通过社区提供不同的存储组件(内存数据库、关系数据库、NoSQL等)Sink连接器,并且根据业务要求,需要支持流式接口(changelog)或者批量接口。
- 数据处理: Kappa流处理平台需要支持各种流应用,需要指出的是,对于计算资源要求特别多的工作负载,可能还是需要求助批处理引擎。Flink提供流式处理和批处理两种模式,可以满足不同工作负载的需要。
基于与多个同行的交流,实时流式普遍有需求,而且认为Kappa架构在架构上优于Lambda架构。然而,实践中部署Kappa架构在国内还是比较少。
造成这种叫好不叫座的局面,这里存在技术推广周期的因素,但也有技术问题未解决,有两个原因:其一,在缺少长远规划的前提下,在批处理基础上加上流处理的应用快速推出流式应用,这是比较保险的做法;其二,Kafka在这个解决方案中也存在相关未解决的问题。
3. Kappa架构的扩展性与成本
本文接下来的篇幅就着重描述它的几个重要问题,以及我们的一些观点。
3.1 扩展性与成本问题
将大规模的数据保存到Kafka中是有很大问题的,在PB级的时候存在成本与可扩展性问题:
在存储成本方面,与数据湖方案或者私有化环境上的HDFS都差很多,特别是在公有云上,云服务提供商(例如AWS S3,阿里OSS)提供的对象存储方案成本优势非常明显,估计成本相差5倍以上;
Kafka在存储扩展方面也是非常繁琐,这里的技术原因是当前版本的存储与计算是耦合的。
上文提到过采用Topic Compaction的方法压缩数据,从而减少存储空间。但此方法限制比较大,且在扩展能力方面无法满足要求,因为大部分人希望的是instant elastic能力,现有的扩容机制在数据量大的时候需要等待很长时间,这个期间系统可能无法提供服务,流计算对此通常是无法容忍的。
为了彻底解决上述问题,Kafka社区也在抓紧开发Tiered Storage特性。Tiered Storage采用存储与计算分离的架构,社区对这个特性非常期待。需要指出的是,Kafka的竞品Pulsar已经实现了存算分离,但为什么Kappa架构没有真正流行起来呢?也许还有其他原因。
3.2 需要更多计算资源
这个问题的本质是流式计算引起的,也是为“实时”付出的代价。然而,在企业中并不是所有的业务都是需要实时处理的。
合适的工具干合适的活,下面这个图来自Uber,该方案把Kappa的使用局限在数据集成部分,这在一定程度上解决了计算资源的问题,同时也是一种架构演进的思路。
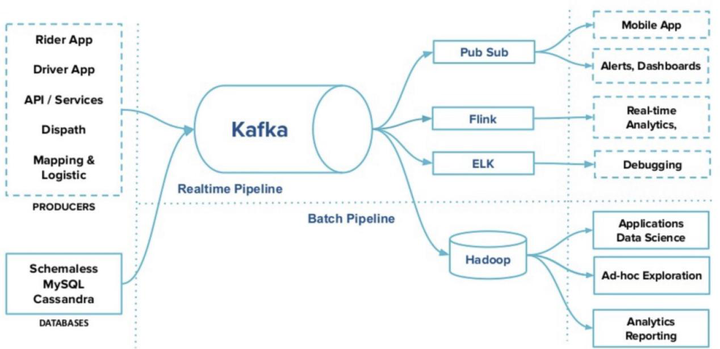
虽然业界也在解决Kappa架构中Kafka固有的一些问题,但在实践中,大部分人把Kappa的实现局限在数据集成这一环节的。导致这一结果的原因就是所谓天下没有免费的午餐,所有环节使用流处理是不切实际的,毕竟流式计算需要的计算资源会比较多。
因此,使用流批一体的计算引擎综合两种不同业务需求,是比较自然的做法。滴普科技构建的一站式云原生数据智能平台Fastdata,在流批一体相关功能特性上已经做了尝试,关于流批一体的具体方案我们在后续的文章中展现给大家。












