墨芯发布32倍稀疏AI计算卡,性能对标英伟达 | 甲子首发

搭载墨芯首款芯片ANTOUM,面向数据中心AI推理应用。
又一家对标英伟达的AI芯片公司发布新产品。
2022年3月22日,墨芯人工智能宣布即将发布两款面向云计算市场的AI计算卡:SparseOne™️ S-100和SparseMegatron™️ S-300,这两款AI计算卡均搭载墨芯首颗英腾处理器(ANTOUM),是全球首款高达32倍稀疏率的AI计算芯片。
其中SparseMegatron™️ S-300对标英伟达A10和A30(全高全长),计算标准模型ResNet50,算力超90000 FPS;SparseOne™️ S-100对标英伟达T4(半高半长),算力达31031FPS,运行ResNet50时,SparseOne™️ S-100与T4相比,算力超后者的6倍,而功耗则不到后者的1/2。

截止目前,墨芯已经完成五轮融资。最近一次融资是发生在2021年底的A轮融资,金额数亿人民币,由基石资本、大湾区共同家园发展基金领投,同威资本、中科华盛、及深圳天使母基金跟投。2021年初墨芯依次获得浪潮云海基金和智慧互联产业基金战略投资。
借产品即将发布之际,「甲子光年」采访了墨芯人工智能创始人兼CEO王维,和他聊聊墨芯用稀疏化算法做AI计算卡的一些思考。
墨芯人工智能所在的AI芯片市场前景广阔。根据公开资料,2020年全球AI芯片市场规模约为101亿美元,年复合增长率达52.1%。其中中国云端AI芯片市场规模为111.7亿元人民币,是AI芯片的主要细分市场。
然而近年来,芯片的算力发展逐渐跟不上算力的需求。王维告诉「甲子光年」,目前AI计算对算力的需求每3.5个月就要翻一番,与此同时,根据摩尔定律算力需要每18个月左右才能翻一番。
于是,传统的算力供给模式将要被打破,市场不再按照算力供给方来配套设计上层的软件和应用场景,而需要根据具体的应用场景,打通算法、软件和硬件,在立项之初就做一体化的设计。
业内有人将这种模式定义为“AI芯片2.0时代”。
新的时代离不开技术的创新与发展。本次,墨芯发布的AI加速卡,搭载了首款芯片ANTOUM,并应用“稀疏化计算模式”,尝试突破算力极限。
“稀疏化计算”的原理不太复杂,是指在原有AI计算的大量矩阵运算中,将含有0元素或无效元素的计算剔除,以加快计算速度。
比如在人脸识别的场景中,传统的算法会直接计算图片中的每一个元素与现有图片模型的关联,从而得出结论。而应用稀疏化计算,先在图片中找出需要比对的元素,而后只需计算这些元素与现有图片模型的关联。
在王维看来,一项好的新技术,需要有足够的创新性、创新的可持续性和可商业化三个方面。而墨芯的“稀疏化”正是这样的创新技术。
在创新性方面,业内的共识是,一项革命性的技术需要比现有的技术强10倍以上,比如性能高10倍、功耗低10倍、或者成本降低10倍等。王维介绍,应用稀疏化算法,能够为客户提供 4~32 倍稀疏化压缩能力,计算速度能够达到原有的10~20倍。
在可持续性方面,王维觉得,随着AI模型参数越来越大,算力增长得越来越快,模型的稀疏性也将越高,未来的模型可以稀疏50倍甚至100倍。
在可商业化方面,墨芯做了更多前置思考。
随着AI芯片赛道的逐渐成熟,除了技术与产品性能方面的竞争,“商业化落地”方面的考量变得愈发重要。
具体来说,墨芯希望通过降低客户的TCO(单位算力的硬件拥有成本),让客户更愿意使用。TCO主要可以分为两个方面,包括硬件购买成本和使用的能耗成本。
互联网及科技企业对于数据中心的需求非常大,大型的互联网公司每年在数据中心建设方面的投入能够达到数十亿的规模。由于墨芯的计算卡拥有目前GPU的5~10倍的等效算力,在单卡价格相当的情况下,可以大幅降低客户整体的采购成本。
除此之外,客户的使用和迁移成本也较低。墨芯开发的编译器已适配其计算卡,支持通用的AI开发平台TensorFlow、PyTorch或MXNet等。在具体的应用,墨芯软件栈Moffett NNKit 中特有的 Moffett NNCompressor 为客户模型提供 4-32 倍稀疏化压缩能力,客户依旧可以在熟悉的TensorFlow或PyTorch环境里进行开发,方便迁移与交付。
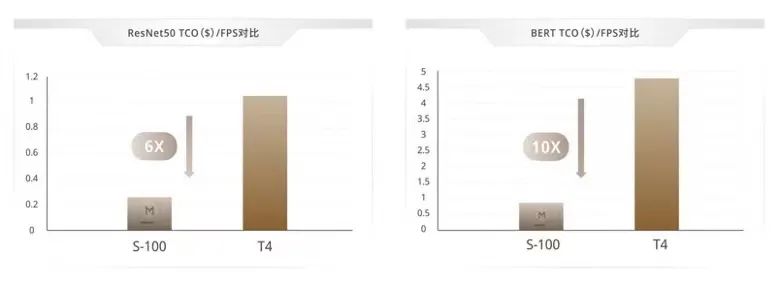
在使用成本方面,墨芯更关注能效比。王维介绍,相较于市场旗舰产品,S-100运行ResNet 50时,每FPS的能效TCO可以降低6倍;运行BERT时,每SPS的能效TCO可以降低10倍,可以有效地降低能耗。
更进一步,在面向业务的使用方面,由于客户能够便捷地使用墨芯的编译器,同时稀疏化算法又具有通用性,在具体场景下,客户往往只需要改几行代码,就能适配新的计算卡,完成优化。
目前,墨芯的主要客户面向数据中心AI推理应用,在互联网、运营商、安防、生物制药和FinTech等场景下已有了具体的实践。
对于互联网客户来说,墨芯高性能芯片能够帮助客户提高内容推荐精准度、广告投放精准度。普通消费者在日常生活中经常需要AI芯片提供算力,高性能的芯片能够让社交媒体更懂你心、更精准推荐;在线翻译场景中,墨芯高性能芯片可以让翻译更实时更精准。
在三年多的发展过程中,墨芯受到了产业资本和财务资本的共同助力。王维告诉「甲子光年」,“产业资本、财务资本的助力,帮助墨芯产品能更好地落地。但同时,一家科技企业,核心还是将技术创新转化为生产力,水到自然渠成。” 王维相信,稀疏化计算将为墨芯带来无限的发展空间和机遇。
本文来自微信公众号 “甲子光年”(ID:jazzyear),作者:范文婧,36氪经授权发布。


























