AI靠语意理解把照片变抽象画,无需相应数据集,只画4笔也保留神韵,有毕加索内味儿了

行早 发自 凹非寺
量子位 | 公众号 QbitAI
只用几笔,如何勾勒一只动物的简笔画,很多人从小都没整明白的问题——
如今AI也能实现了。

下面图中,左边是三张不同的动物照片,右边是AI仅用线条来描出它们的外形和神态。
从32笔到4笔,即使大量信息都抽象略去了,但我们还是能辨识出对应动物,尤其是最下面的猫猫,只需4笔曲线也能展示出猫的神韵:

再看这匹马,抽象到最后只保留了马头、马鬃和扬蹄飞奔的动作,真有点毕加索那幅公牛那味儿了。

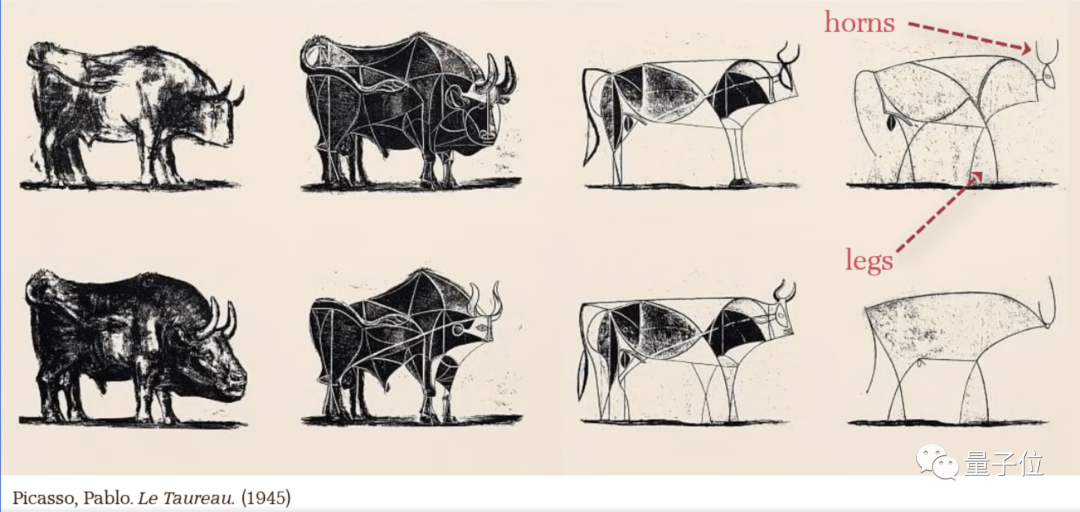
更神奇的是,其背后的模型CLIPasso并没有在速写画数据集上训练——
等于说,没“学”过怎么画抽象画,按照文字描述就能完成简笔速写。
要知道,日常速写都比较抽象,即使是人来画,要想抓住物体的“灵魂”,也需要经过很久的训练。
那为什么这个CLIPasso甚至连速写画数据集训练都没做,就能get到抽象简笔画的“灵魂”呢?
其实AI画抽象简笔画比人更难。
既要准确地理解语义,又要在几何上相似,才能让抽象画看起来有“像”的感觉。
具体实现上,模型会根据图像的特征图先生成初始线条的位置,然后靠CLIP构建两个损失函数,来控制抽象画几何相似、语义理解准确。
其中CLIP就是OpenAI发布的一个重排序的模型,它会通过打分排名来筛选出和文字匹配度最高的图片。
这样一来,CLIPasso的整体结构就比较清晰了:
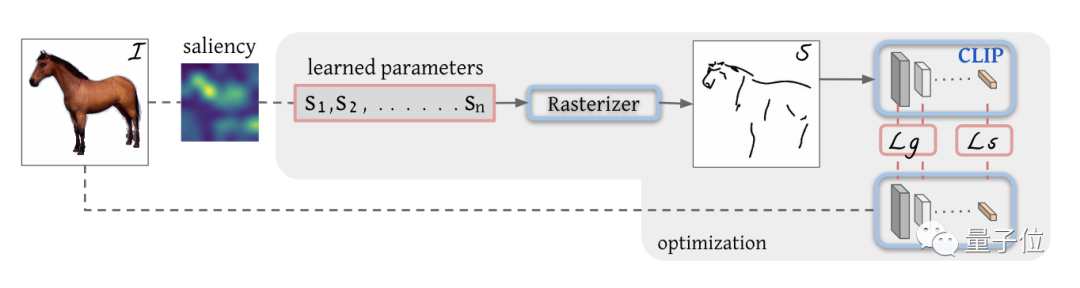
例如我们要画一匹马,首先通过特征图(saliency)标记一些初始线条(S1,S2…Sn)的位置。
然后通过光栅化(Rasterizer)把线条投影到成像平面:

接下来就是优化线条参数了。把初始图像导入CLIP模型,计算几何损失(Lg)和语义损失(Ls)。
其中语义损失通过余弦相似度来判断两图的差异,而几何损失通过中间层来控制。

这样就能保证在准确理解语义的情况下保持几何准确,再通过反向传播不断调整线条参数,直到损失收敛。
那速写的抽象程度是怎么控制的呢?
就是靠设置线条的数量。
同样画一匹马,用32笔去画和只用4笔去画,抽象效果肯定是不一样的:

最后,我们来看一下CLIPasso画出的画辨识度怎么样。
下图中这个柱形图代表的是五类动物的辨识准确度。
不过在猜测的时候还有第六个选项:这五种动物都不是。
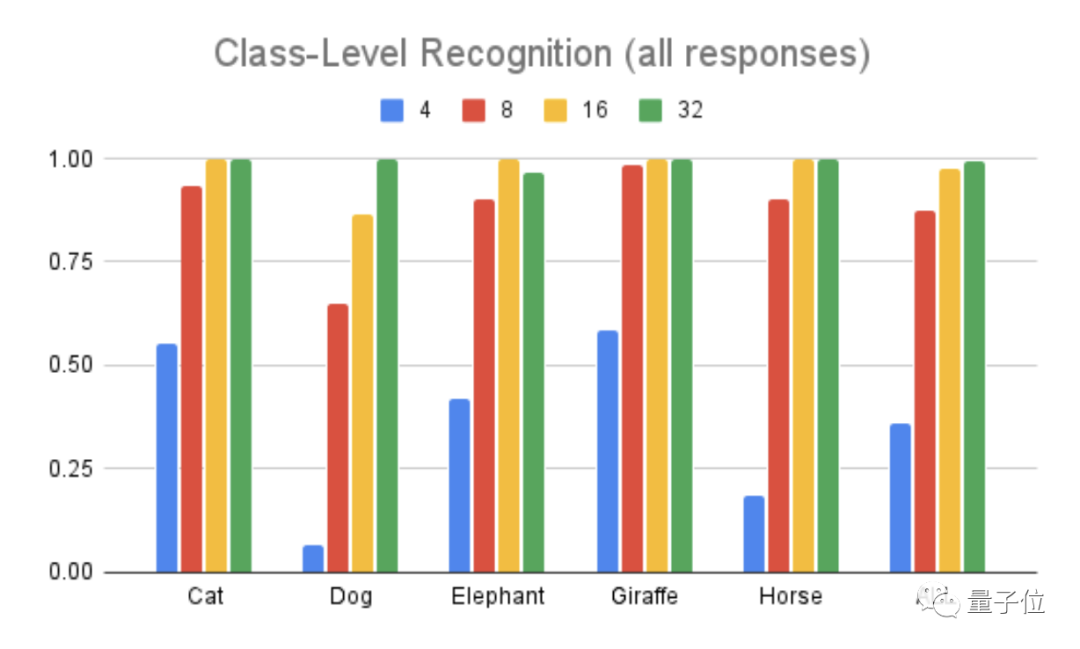
从图中可以看出,无论什么动物,在高度抽象的时候(4笔画),辨识度都很低,随着笔画越来越多,辨识度也会逐渐提高。
毕竟这么抽象的画,看不出来是啥也很正常。
但是,模型团队在第二轮测试辨识度时删除了第六个选项,也就是必须从这五个动物类型中选一个归类。
这时,我们从下面的柱形图中可以看到,即使是高度抽象的4笔画,辨识度也提高了不少,从36%提到了76%。
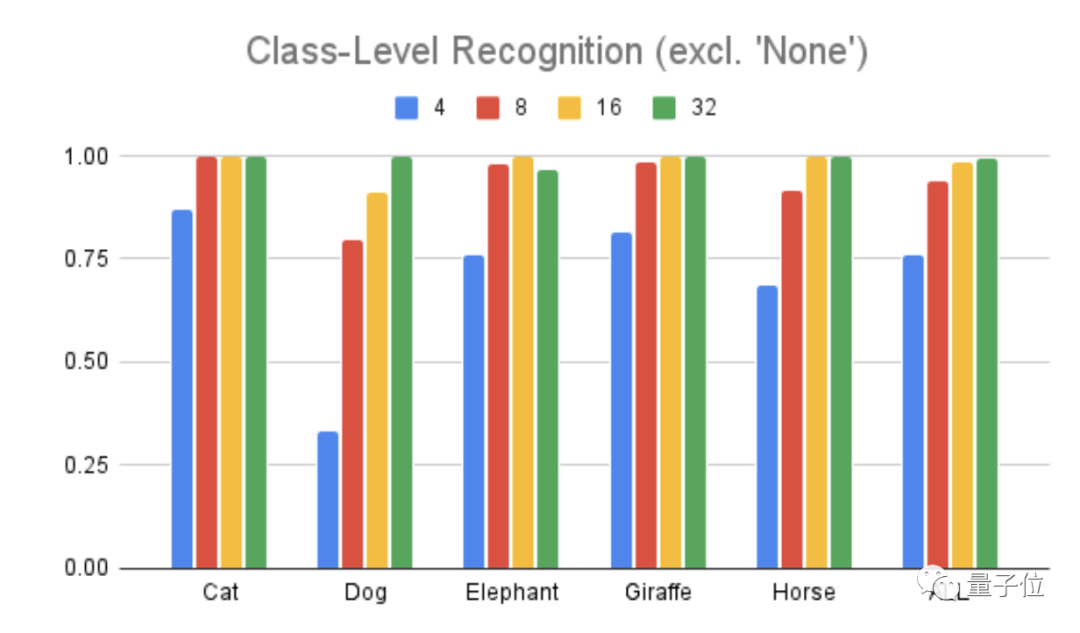
这就说明了之前辨认不出是太抽象导致的,AI毕加索的画仍然抓住了动物的核心特征。
目前这个模型已经出了colab版本,只需在左侧文件夹中添加你想要抽象化的图片,然后运行三个部分即可得到输出照片。
CLIPasso团队成员主要来自洛桑联邦理工学院、特拉维夫大学等。
其中Jessica是苏黎世联邦理工学院机器人方向的硕士研究生,目前在洛桑联邦理工学院的计算机视觉实验室VILAB实习。

而Yale Vinker是特拉维夫大学计算机科学的博士研究生,对艺术和技术的交叉领域非常感兴趣,也难怪CLIPasso有这么丰富的艺术细胞。

参考链接:
[1]https://clipasso.github.io/clipasso/
[2]https://colab.research.google.com/github/yael-vinker/CLIPasso/blob/main/CLIPasso.ipynb#scrollTo=L7Cp8FFHx3VG
本文来自微信公众号 “量子位”(ID:QbitAI),36氪经授权发布。





















