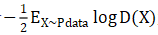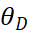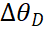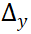GAN研究方法综述

编者按:本文是往届全球机器学习技术大会上票选出的最受欢迎的演讲内容,演讲者为Boolan首席AI咨询师—方林老师。
作为一种生成式的模型,GAN在众多领域大放异彩。如何训练GAN?下面由Boolan首席AI咨询师,方林老师为大家揭秘。

方林 Boolan首席AI咨询师
长期从事深度学习、贝叶斯网络、进化学习、类脑学习、脉冲神经网络和谓词逻辑的研究和技术咨询,涉及自动驾驶、人脸识别、自然语言处理等多项前沿AI行业应用,曾主导研发了人工智能博弈软件框架、通用问题求解框架、Prolog逻辑语言编译器和运行环境等。在加入Boolan之前,方林博士担任深兰科技AI资深研究员、首席科学家、深兰大学校长。南京大学计算机软件博士毕业。
以下为演讲内容:
GAN的科研成果层出不穷,有些研究报告之间还可能相互矛盾。我今天分享的只是我所了解到的,全球范围内这个领域,一些较为先进的科研成果,但不代表受到公认,不代表百分百正确,只是帮助大家打开思路。
真实样本和生成样本(由随机向量Z经过生成器生成)作为输入,经过判别器后,输出一个判别系数,通常来说,系数趋近于1,判别为真实样本;系数趋近于0,判别为生成样本。如果你不了解什么是生成式对抗网络,可以把生成器和判别器看成是函数。从结构上讲,它由两个CNN组成,而且现在的趋势是进一步细化,把判别器做成Encoder-Decoder模式。
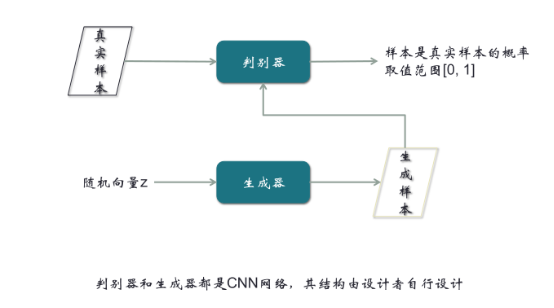
第一步:用真实样本训练判别器,令它判别出1
大家思考一下,如果我们不考虑第二步和第三步,只考虑第一步,实际上这个结构是有很大问题的。因为不管输入的样本是什么,想让它输出是1,这样单种类的分类,没有任何意义。一般意义上的分类器,起码分两类。如果不管判别器的输入层、隐藏层、中间层是什么样,只要最后一层保证输出是标量1,这个很容易做到。所以这个模型,只在我们接下来的所有步骤中有意义,单独看没有意义,这个大家要能看出来。

第二步,由随机向量经过生成器,输出生成样本,然后把生成样本输入到判别器,令它能输出0
与第一步联系,就会有两个分类,一个是1,一个是0。有了两个分类,判别器就可以得到优化。这是我们设计这个网络模型的结构时一定要注意的地方。在第二步,我们期望结果是0,但可能不是,就会产生误差,从而产生梯度,产生梯度后我们沿着箭头的反方向走,这就是反向传播。在反向传播过程中,可以把遇到的任何一个参数进行优化。优化过程中,有一个小技巧,在生成器的地方,把梯度截断,不优化生成器。因为对生成器优化,最终的结果不过是输出一个0,这不是生成器的目标。生成器的目标是生成一个很像真实样本的假样本。所以需要在这里截断梯度。第二步所进行的优化,是对判别器进行的优化。结合第一步,两步可以合成一步。
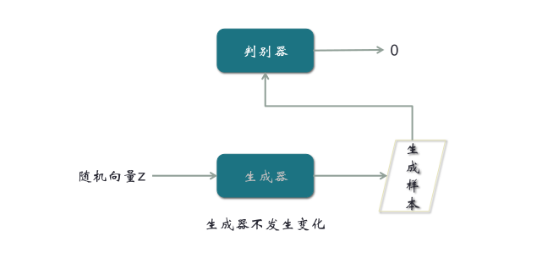
第三步,输入随机向量,经过生成器输出生成样本,再经过判别器,输出判别系数,这时我们期望输出是1
前面输出0,我们希望用梯度优化判别器,现在用一个不同的期望输出,来优化生成器。梯度在跑的过程中,虽然的确先经过判别器,但是因为判别器前面只对输出样本,期望输出是0,现在期望输出是1,所以梯度会路过判别器,只对生成器进行优化。所以最优化的结果,就是判别器对真实样本总是汇报1,对生成的假样本总是汇报0,同时我们生成器输出的生成样本,总是能通过判别器的判别。
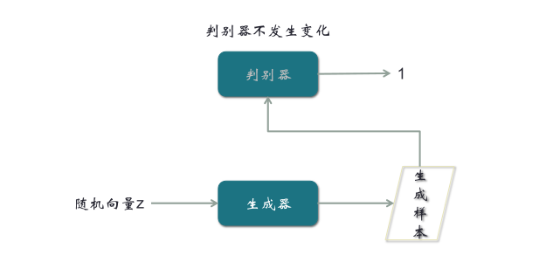
但是这里有一个矛盾的地方,生成样本经过判别器,如果判别结果是1,会被当成真实样本,这意味判别器的判别是错误的;如果判别结果趋近于0,说明判别器的判别是正确的,但是这又意味着生成器生成的结果是不理想的。这个矛盾的对抗结果,使得整个GAN的训练非常麻烦。
对判别器的训练: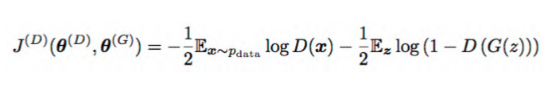
data指真实样本,D指判别器,G指生成器
我们期望D(X)趋近于1,整个![]() 趋近于0。D(G(z))是生成器对输入向量Z生成的样本,作为判别器的输入,我们期望这部分的输入趋近于0。
趋近于0。D(G(z))是生成器对输入向量Z生成的样本,作为判别器的输入,我们期望这部分的输入趋近于0。
对生成器的训练:
这里D(G(z))与上面相反,我们期望输出结果是1。
(一)Wasserstein GAN(WGAN)
GAN的问题,曾在Wasserstein的一篇论文中得到充分表达,当真实样本和生成样本的交集不可度量时,就会出现问题。
其实真实样本和生成样本不能说绝对没有交集,而是它们的交集要么是空集要么是不可度量,因为它是一个低微的流形。
举例:在一个三维的立体空间中,有一个二维平面和另一个二维平面,它们的相交是一条直线,这条直线在三维空间中是没有体积的。现在假设是10000维的高维空间,我们刚才讲的图片属于低微流形,也就是10000维空间中一个低维的超平面而已。与随机向量产生的生成样本之间,是两个超平面,就算有交集,交集的体积也是0(这个体积是多维体积,而不是真实体积)。
这会使得我们的运算出问题,回顾上面的公式:有真实样本和生成样本的分布,它们之间的交集体积为0,那么X和G(Z)几乎没有可度量的重合部分,这样的数对真实样本来说,它的分布为0,对生成样本的分布来说,概率为0,两个必有一个为0。我们知道对数里面取0,就会是一个负无穷,这个时候就会产生问题,使得训练进行不下去。
这里,可以看成是log对真实样本分布和生成样本分布的求积分。计算过程中我们可以发现,这两个分布是没有交集的。对于特定X来说,要么分子为0,要么分母为0,最后计算都无法进行。
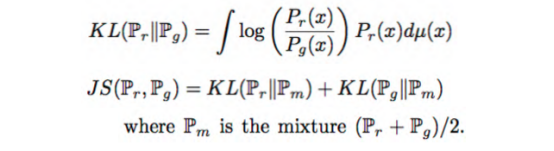
JS距离是基于KL距离的,使用的是两个分布÷2的公式。因为两个分布很有可能其中一个值为0,所以取平均数。计算发现,无论真实样本还是生成样本,两个值一个是1,另一个就是0,结果使得JS距离为一个常数。做深度学习和神经元网络模型训练,我们最不希望遇到一个不变的常量,因为如果遇到,意味着它要么是一个无用的参数,要么它就是最后我们计算出来的损的值,如果这个值是一个常量保持不变,也就意味着我们的梯度没有了。最后模型的训练就会出问题。
- WGAN给我们带来的启示
1、不要使用基于KL距离或者JS距离的梯度。
WGAN的建议是EM距离,输入X样本,输出Y,Y并不是一个0~1之间的数,而是一个图片。这是WGAN一个创新的地方。

2、让生成样本集合和真实样本集合之间有可度量的重叠。
比如:给真实样本加噪音。这个噪音可以是高斯分布,也可以是平均分布。加噪音的原因是只有这样的样本,才和随机生成的样本之间有可度量的交集,才能产生梯度,有了梯度,就可以训练生成器和辨别器。
(二)Energy-Based GAN (EBGAN)
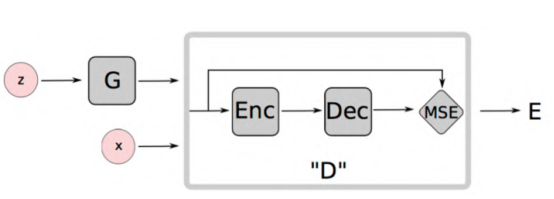
G指生成器,z代表随机向量,x代表真实样本。中间矩形框出的是辨别器,辨别器由Encoder和Decoder两部分组成。
这个模型输入的不管是真实样本还是假样本,都是图片,输出也是图片,比较两张图片是否一致。大家可能觉得奇怪,这不就是复制吗?是的,但在复制过程,先编码生成一维向量,然后一维向量经过解码,恢复图片,再与原始图片比较,如果是真实图片,我们希望两张图片完全一样;如果是生成图片,我们希望两张图片的差别越大越好。这改变了在最早GAN模型中用0和1区分真实样本与生成样本的做法,也避免了上面WGAN中发现的梯度为0的情况发生。
Encoder-Decoder中间会生成一个语义向量,这个语义向量图上没有画出来,但是非常重要。这个向量可以看成是输入向量的一个语义,因为照片之间进行图像操作非常困难,但是向量之间是可以加减乘除的,这样使得我们操作一个人脸改变他的表情,甚至变成另一张人脸的过程是平滑自然的。这就是这个语义向量做的事,如果没有Encoder-Decoder,这个事情就做不成。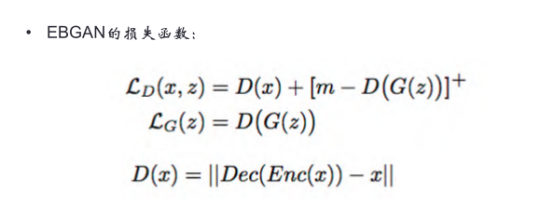
EBGAN定义了一个D(X)函数:X经过Encoder编码,再经过Decoder解码后,得到一个X的预测值,我们希望这个预测值跟X是无差别的。
在这个过程,我们希望真实样本的输入与输出之间的误差D(x)越小越好,生成样本的输入与输出之间的误差D(G(z))越大越好,整个公式就是判别器的损失函数Lost。m-D(G(z))指里面的数如果小于0,整个值就取0;如果大于0数,则这个数是几就取几。这么做的原因是,如果不加m-函数的限制,D(G(z))可以变成无穷大,前加负号就变成无穷小,Lost函数本来就希望无穷小,最后就会没有最小值。用梯度下降法对这个Lost求梯度是没有意义的,用这样的所谓梯度去优化模型,肯定没有结果。所以大家在做模型时,一定要注意:可以对函数求极值,条件是这个极值能达到,而且这个极值不是正无穷也不是负无穷。
另外,把-的误差改成+的误差,就是对生成器的优化。
(三)Boundary-Equilibrium GAN(BEGAN)
BEGAN模型,D函数就是之前的D函数,t指的是计算过程中第几轮训练,不断进行优化。
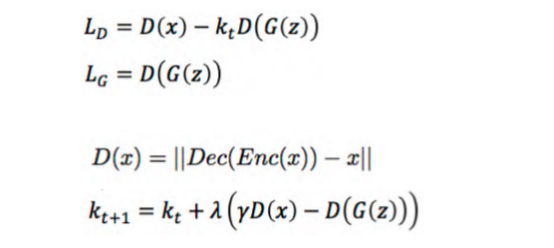
小结
对GAN的研究分为两个方向,一个是试图使GAN的精度提高,使生成的图片越像照片;第二个是令它的功能更强大。上面主要讲的是第一个方向,这里再强调一下,GAN在质量提高这条线上的模型,远不止上文介绍的三个。下面我们讲第二个方向,GAN的应用很强,从功能上,我们有哪些模型可以考虑。
(一)CGAN-条件生成式对抗网络
这个模型的样本是带有标签的,比如输入一个样本,同时需要带上性别标签,表示要求生成一张男人/女人的照片。这个模型是对原始GAN的一个扩展。
对判别器的训练:真实样本和标签,同时输入到判别器,输出要么是0要么是1。
对生成器的训练:随机向量和标签,同时输入生成器,然后标签和生成样本同时输入判别器。从输入的结构角度看出,真实样本的输入由真实样本和标签组成,而假样本的输入也是由假样本与标签组成,这个训练GAN模型的提高是一个比较大的进步。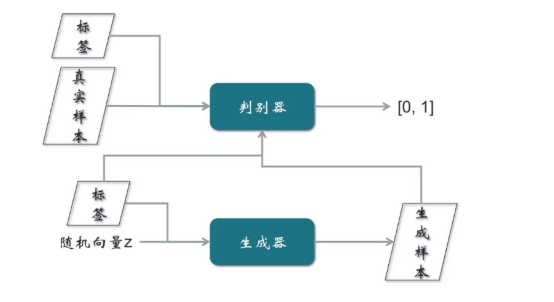
(二)Pix2Pix模型
这个模型同时也是一个应用,它的功能是手画一个鞋子或者包的线条,可以变成一个真实的鞋或者包的图片。这个模型的输入过程与上文CGAN一样,唯一区别是不需要随机向量,只需要把简笔画作为生成器的输入。
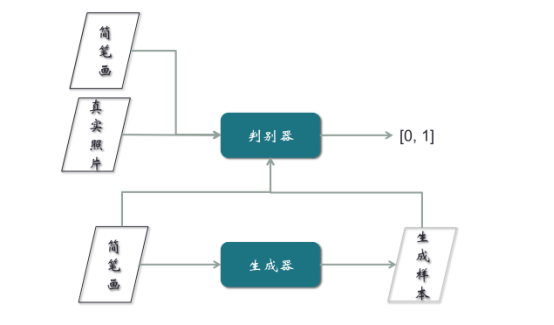
但是Pix2Pix在训练时,需要简笔画与真实样本,必须是成对的。比如简笔画是鞋子的线条,照片就需要是那张鞋子的照片,成对输入。然而样本的收集非常难,现在95%以上的时间、精力和费用都在样本的收集上,所以要简笔画与真实照片配对,非常不容易。这是Pix2Pix模型的一个重大缺陷。为解决这个缺陷,提出了CycleGAN的概念。
(三)CycleGAN
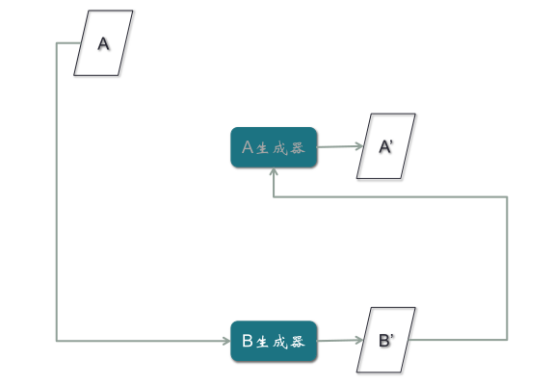
以上文简笔画为例,CycleGAN只需要两类,一类是简笔画,一类是照片,不需要一一配对,其它功能与Pix2Pix完全一致。但是取消了配对的限制,使得对样本收集的负担大大减轻。CycleGAN模型的结构,它有两个判别器,两个生成器。其中,B判别器和B生成器是为B图片做一个GAN模型,A判别器和A生成器是为A图片做一个GAN模型。
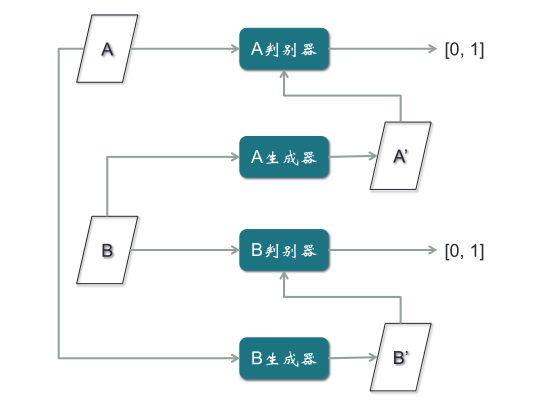
- CycleGAN的训练步骤
第一步,用A的真实样本训练A判别器,用B的真实样本训练B判别器,使得判别器对两类不同真实样本,分别都判别为1,这是从最早普通GAN模型扩展出来的。

第二步,B真实样本输入A生成器,输出假的A样本A’,然后通过A判别器,输出为0;第二条路径是A真实样本输入B生成器,输出假的B样本B’,再通过B判别器,输出为0。
第三步,B真实样本经过A生成器,生成假的A样本A’,再经过B生成器,生成假的B样本B’,目的是使假的B样本与B真实样本误差最小。注意:B’与B之间的误差,所产生的梯度应该去训练A生成器,而不是B生成器,因为B生成器输入的是A样本,与这条路径没有关系,所以梯度不应该影响B生成器,而应该优化A生成器。
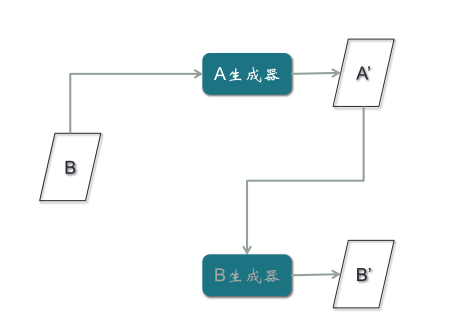
第四步,对A样本重复第三步骤,期望A’与A一致。如果不一致,产生的梯度用来训练B生成器,与A生成器无关。这是很巧妙的一个结构。
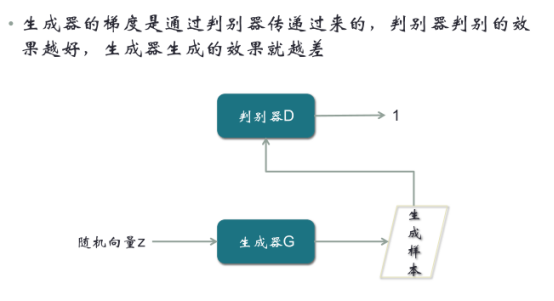
现在的判别器一般都分为Encoder-Decoder,每个Encoder-Decoder就是一个大型的CNN,每个卷积神经网络都有十几层,所以梯度产生后,跋山涉水到达生成器,会消失。为什么呢?
在对判别器的优化过程中,判别器的输入绝不只是一个x或者g,还有它自己的参数![]() ,因为它的参数也是它的输入。通过计算发现,每一次产生梯度后,梯度都会对这个模型的参数进行优化,产生
,因为它的参数也是它的输入。通过计算发现,每一次产生梯度后,梯度都会对这个模型的参数进行优化,产生![]() ,再施加到
,再施加到![]() ,所以
,所以![]() 的优化是累积的。但是不管是x还是g,真实样本永远不变,所以优化最后的效果,就是梯度越来越倾向于在最后的输入层被浪费掉,
的优化是累积的。但是不管是x还是g,真实样本永远不变,所以优化最后的效果,就是梯度越来越倾向于在最后的输入层被浪费掉,![]() 产生的偏差越来越倾向于被用来优化
产生的偏差越来越倾向于被用来优化![]() ,而越来越不倾向于优化
,而越来越不倾向于优化![]() 。所以梯度往生成器传的时候,就变得很微小,从而使得生成器的优化,变成问题。
。所以梯度往生成器传的时候,就变得很微小,从而使得生成器的优化,变成问题。
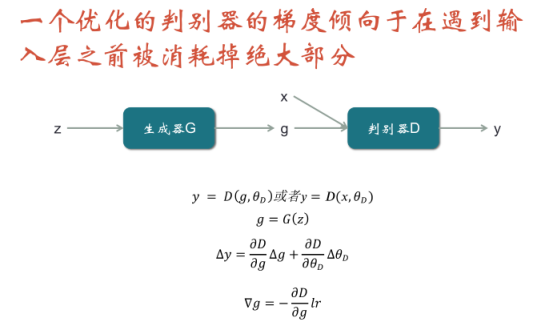
x表示真实样本,g表示假样本,![]() 表示判别器的参数
表示判别器的参数
1、GAN并不希望判别器的准确率达到1,而是0.5;如果我们把判别器的准确率优化到接近1时,再把它拉回0.5就变得十分困难。
2、我们对GAN的改进都是基于最优化目标的,数学上讲,把目标优化到“一半好”,这个说法是有矛盾的。如果我们设定一个目标,从数学上讲,就是把它优化为达到那个目标。而我们的梯度下降法是基于求偏导数等于0,求偏导数等于0的目的是让我们的目标达到最优,而不是达到一半优。
优化判别器时,一旦发现它对某个种类样本(指真实样本和生成样本两种)的判别,辨别准确率达到0.5时,就应该停下来。这是一种很奇怪的做法,我相信大家很少能在不参考其他程序文本代码的情况下,自己主动做这一步。因为一般我们希望辨别率达到99%都不够,而达到50%就要停下来,这需要你有极大的毅力相信自己的判断。虽然不容易做到,但确实要这样去做。
时间问题,我们今天关于GAN的分享就到这里。