“青春期”的深度学习:现状与未来展望

4月16-17日,【2021全球机器学习技术大会】在北京盛大举办。谷歌大脑高级研究科学家Lukasz Kaiser 作为 keynote 演讲嘉宾,分享了《Deep Learning Adolescence : What's Great and What's Next》的专题演讲。以下为演讲内容。

全球机器学习技术大会 Lukasz演讲现场照
虽然如今深度学习已经取得了很多进展,但是我感觉深度学习仍然处在青春期阶段,所以今天想跟大家讨论一下未来我们能够有哪些进展?
2016年是深度学习的一个重要节点,对于NLP的发展也是一个重要里程碑。谷歌很多人已经对一些任务进行研究,有20年甚至更长的时间,比如:磁性标记,即兴创建,命名实体识别,语言建模,翻译,句子压缩,抽象性总结,问题解答等。每个在研究系统里的人,都需要做大量的编码,在翻译上任务就更加复杂。
在深度学习领域,如果想把英文翻译成中文,首先需要输入一些变量,才会有输出变量,而这些变量都是大小可变的,神经网络将如何处理这些数据?以前是用NLP来处理这个问题,但实际效果并不是很好,而在编码和译码,也就是涉及到序列的处理方面,最终效果和原来相差不多。
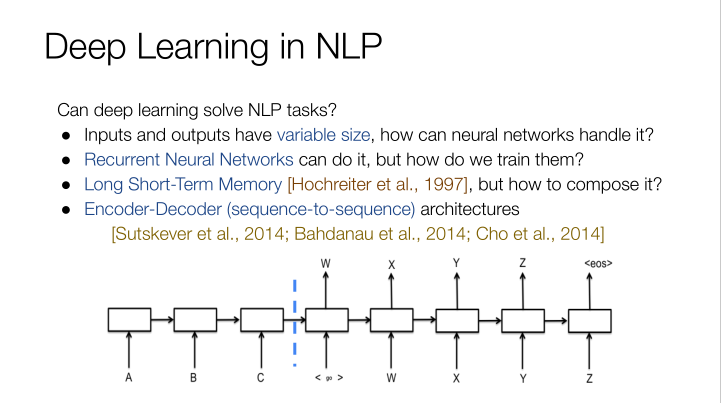
我们前面谈到的几大NLP任务,都可以通过地硅神经网络LNN来进行解决,听起来很简单,现实会更加复杂。在LSTMs模型上面,我们有不同的GPU层,每一层的工作效率都基于上一层的结果,我们的问题就是这些深度的LSTMs模型它行得通吗?答案是大部分时候可以做到。
我们以困惑度来衡量语言模型的性能,困惑度越低越好。通过不同的模型,我们将困惑度从67.6慢慢降低到28。

以语言模型示例:
英文:Yuri Zhirkov was in attendance at the Stamford Bridge at the start of the secondhalf but neither Drogba nor Malouda was able to push on through the Barcelonadefence .
中文:下半场初由礼什尔科夫出席了斯坦福比赛,但德罗巴和马罗达都无法通过巴塞罗那的防守。
从英文来讲,语句是非常通顺的。计算机能识别出这里有3个人的名字,他们都是足球运动员的名字,再加上前面的单词和短句,计算机推算出下一个单词和未来句子的走向。很多模型能够实现这样的效果,那么在翻译上行得通吗?
翻译的性能是以BLEU的分数来衡量的,分数越高越好。以短句为基础的机器学习,BLEU分数是12.7;早期的LSTM模型,分数是19.4,大型的LSTM模型(谷歌目前正在用的模型),它的分数是20.6;更大的GNMT的LSTM模型分数是24.9。BLEU分数只是一个打分标准,实际情况下翻译的效率和准确度如何呢?
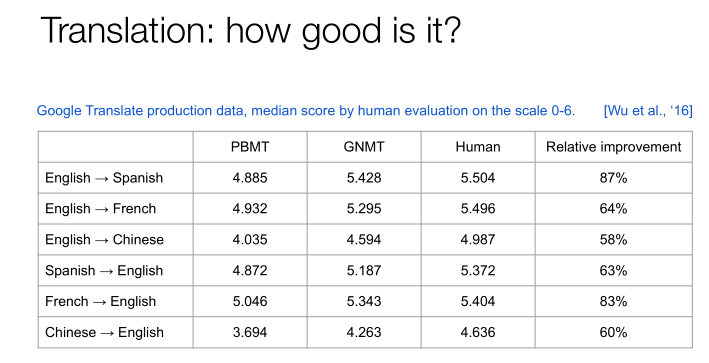
我们让很多人来读了一下这些翻译的文本,可以看到PBMT的分数是4.885,GNMT的分数是5.428,人类能达到的分数是5.504。不管是从英文到不同语种,还是不同语种之间的翻译,可以得出非常一致的结论就是,机器翻译方面我们已经取得了非常大的进展。
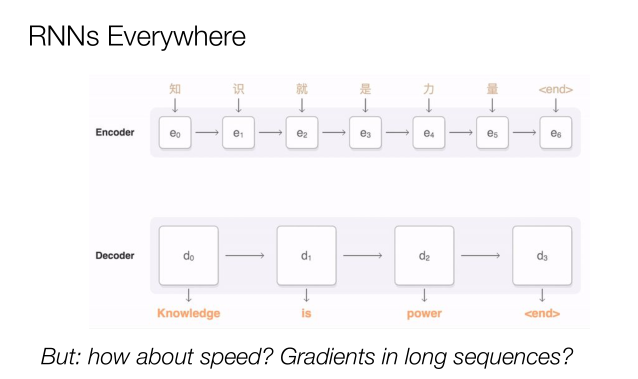
那未来会出现什么问题?机器翻译以短语为基础,而人们通常倾向于将整篇文章进行翻译。这时RNN神经网络非常重要,因为它无处不在,我们可以先编码再译码,但是当序列越来越长的时候问题就出现了,整个文本量非常大话问题就会更多,所以重点是我们如何能够在目前的状况下保有它的性能?如何能够提升它的速度,并且在长序列中进行渐变?
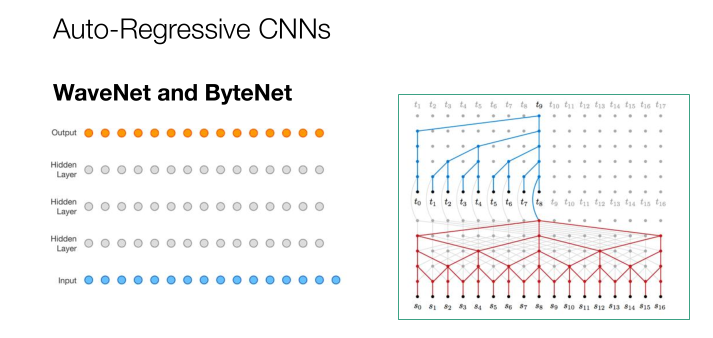
2017年,这个时候自回归的CNN展现了更多的能力。从输入层到几个隐藏层再到输出层,这是WaveNet and ByteNet的工作模式,我们可以一步将输入发布到不同的隐藏层,在层之间的移动也变得更加高效和迅速。那如何将正确的单词和语句放到正确的位置?这时我们就用到了注意力机制。
在注意力机制里面,有一个很重要的机制就是多头注意力机制。如果我们在多头注意力机制下,使用Transformer,那注意力机制会将所有的输入放在一个袋子里面,它不知道每一个单词应该放到什么位置,所以我们需要给它们加上位置点,然后通过多头注意力机制,将不同的信息分配到不同的位置。
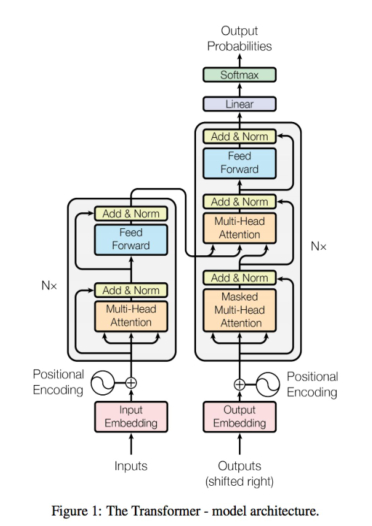
关于解码器,首先编码器开始生成一些数据,再加上一层解码器输出的内容,最后输入到下一层,这就是翻译的过程。所以从输入每一个词,然后生成下一层,这是同时进行的。在解码方面,它也是基于上一层的工作结果来进行解码的。观察机器学习的一些结果,大家可以看到BLEU值不断升高,达到了29.1,这是英语到德语的翻译分数,人类翻译能够达到31分,因此模型的翻译表现已经非常棒了。右边是我们的训练成本,也并没有显著的升高。

2018年,我们的工作重点是长文本的生成。当时我们试图通过热门搜索来生成整个维基百科的文章,训练了2300万个参数,比如“左边标黄的这一段话事实上没有意义,是读不通的”,我们发现参数越多的时候它的精度会越高。
2019年,谷歌旗下另外一个模型GPT2,是主要生成语言的。当时经济学领域一本非常有名的杂志,采访了这个模型的创建者。有趣的是,采访问题是人类问的,答案是机器给的。比如人类问,你认为我们人类该有多担心计算机会取代我们的工作?计算机答,这取决于计算机将会扮演什么样的角色。所以大家可以看到计算机是能够回答问题的。当然,如果问题越长,它的答案也会越来越让人无法理解,没有任何意义,这是现在存在的一个问题。
2020年出现了GPT3,整个故事都是由机器生成。比如一个人站在门口,他想要进去,音乐突然停止了,模型说,你好。然后人类说,我现在寻找一本书。接着模型说,你为什么想要这本书。整个文章模型能够不断地回答人类的问题,虽然它的问题都是一句话一句话进行,但是它的逻辑是非常清楚的,它说的每一句话都是有意义的。它还能生成一些人的内心想法,能把整个故事继续发展下去。比如它里面还谈到了你走进去以后看到了一个非常漂亮的女人,她有着长长的金发,她还穿着紫色的裙子,你觉得你见过这个女人,但事实上你却想不起来她到底是谁。这里模型不仅能生成句子,还能生成段落,而且这个故事还会不断地继续,无限的发展。
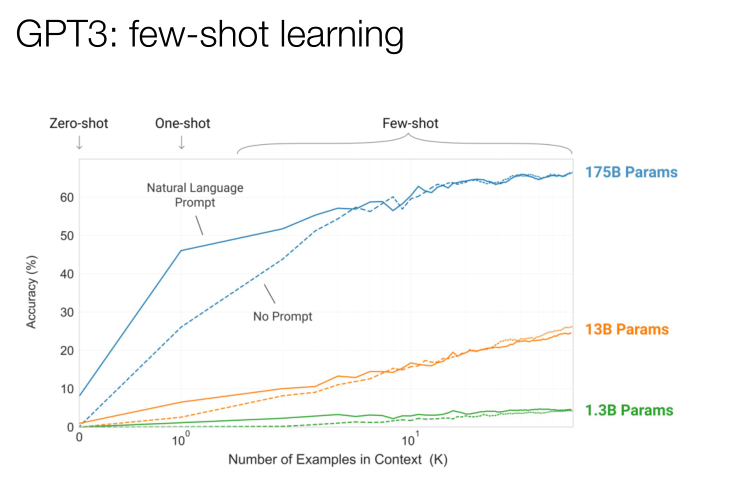
这里非常关键的一个模型是小样本学习。我们可以在这里描述一个非常短的任务,这个模型并没有预先训练过,它是未监督的,但它仍然能将英文翻译成法语,虽然它没有那些监督训练过的模型翻译得那么好,但是它也有一定的翻译效率。小样本学习的效果,取决于里面的例句有多少。很有趣的事情是当模型越来越大,它的效率会越来越高,其中有一个点是激增的,也就是说它得到的提示越多,它的学习效率越高,这个发展在过去的一年是非常可喜的。
上面我跟大家谈了很多的语言模型,都是我工作过的一些模型,下面也想跟大家聊一聊图像识别。
2017年,图像生成我们做了一些模型测试,这些图形的清晰度并不好。2020年,DALL-E模型给它一些文字提示,它就能通过AI自动生成一些图像。
示例:这张图像有一个小白萝卜,它穿着一条芭蕾舞小短裙正在溜一只狗,通过文字提示来生成图像。

从2020年开始,谷歌同事引进了视觉Transformer,在图像方面我们需要很多的输入来对它进行训练,我们需要很多预训练的数据库,数据子集,深度学习的这些模型不仅可以用在文本方面,也可以用在图像等方面。
我们想要得到一个很好的Transformer,如何做这些架构呢?2016年我们还没有办法用到PyTorch这样的工具,就把所有数据都放到一个框架里,2020年我们有了pytorcb,这些数据图书馆都非常有用,可以看到很多事例,它会教你如何操作,非常容易上手。
我们也希望这些模型能有更多数据来进行训练,比如有一个数据库Tensop tensor Trax,可以下载这些数据集并创建一个自己的数据集,也可以将自己的输入建成一个一个输入管道,重复以上步骤我们可以随时下载这些输入和输出的结果。
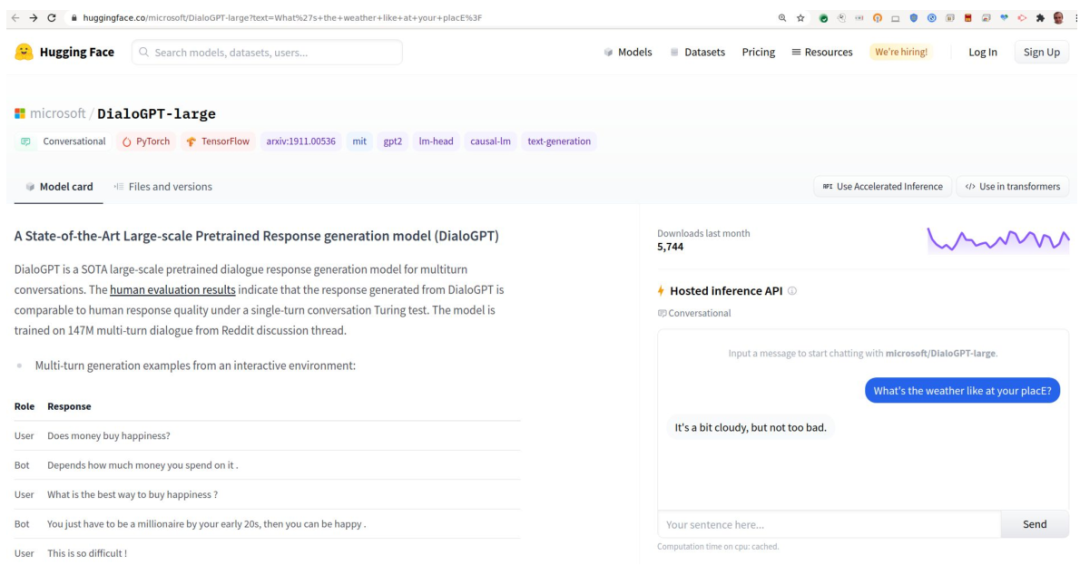
有一个非常有名的资源库叫Hugging Face。它的页面是对话形式的,在网站上输入你的文本,然后运行。你不需要下载任何东西,可以直接在网站上运营,它也可以实现发布。
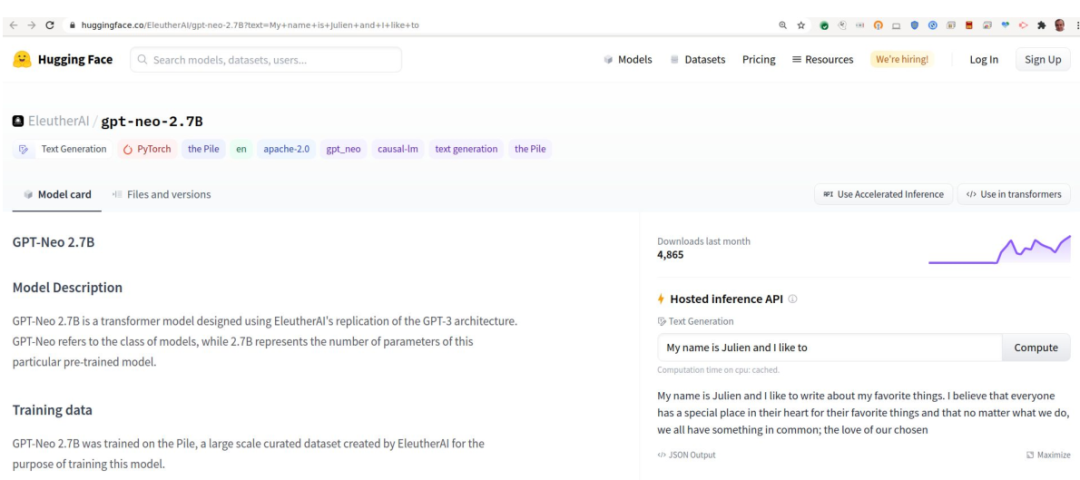
GPT neo,是一个非常高质量的反向传播模型。这个模型很可能比GPT2的那个模型更好,大家可以看到下面写我的名字,以及我最喜欢的事情等,如果输入不同的参数,它会给你提供一些不同的故事。因为架构已经做好了,所以我们可以在上面运行很多个任务,像现在运行更多模型,或者创建更多的模型就越来越容易了。
未来我们将迎来一个什么样的时代呢?我认为是多种模态的时代,一个模型不会完成所有的工作,图像、文本、视频、声音等都会有不同的模型来专门处理的时代。
2017年的多模型,从输入编码到中间的混合,再到解码,它们都能完成不同的任务。未来多种模态的模型将会更加广泛的应用,将会变得更简单更美好,结果也会被更加优化。
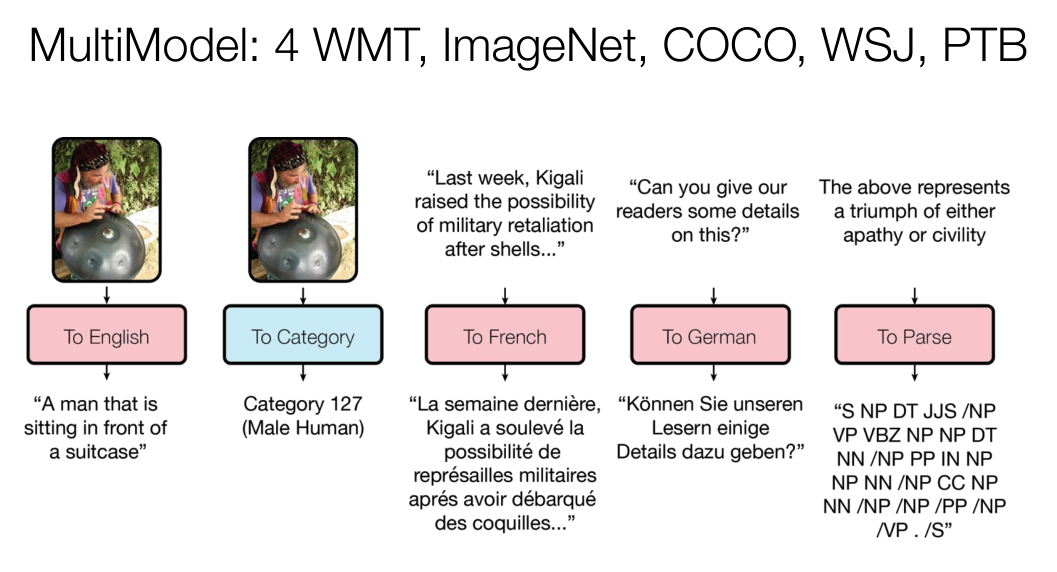
我的另一个信念是我们会有更多更好的Transformer。比如你有1000个单词,在这个量级下,模型的运行效率是还可以的,如果是10~10万字,问题就会变多。从右图可以看出,这是各种各样不同的模型在试图解决这些问题。
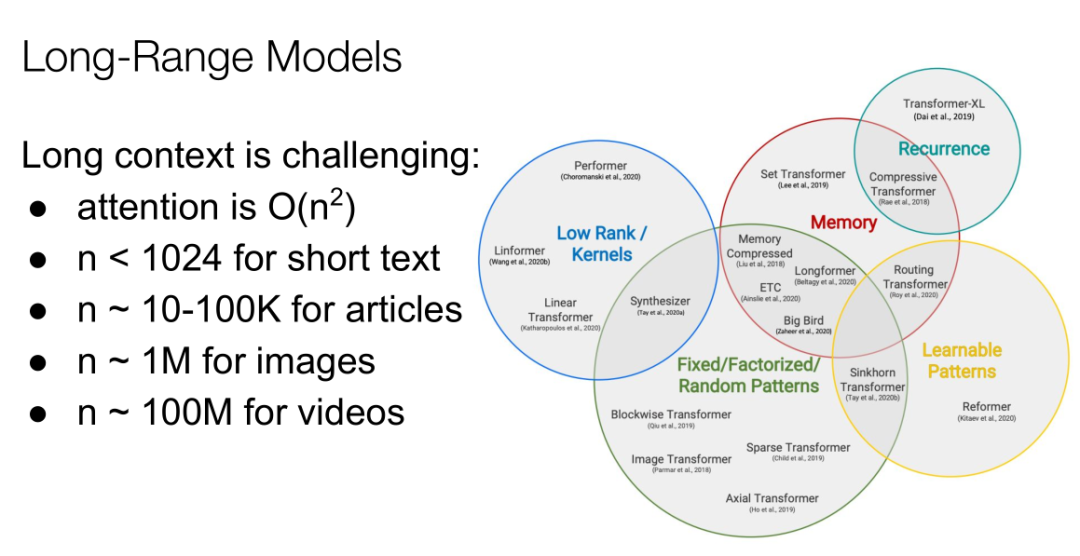
我们可以处理100万左右的图像,但要注意,如果一定要生成视频,需要大概1亿特殊句,因此我们有更多的工作需要做。所以趋势是Transformer会越来越大,序列会越来越长,但我们无法将每个任务都在超级计算机上进行测试,因为需要非常强大的GPU等,同时运行速率也会越来越慢,那么解决这个问题的答案就是稀疏模型。
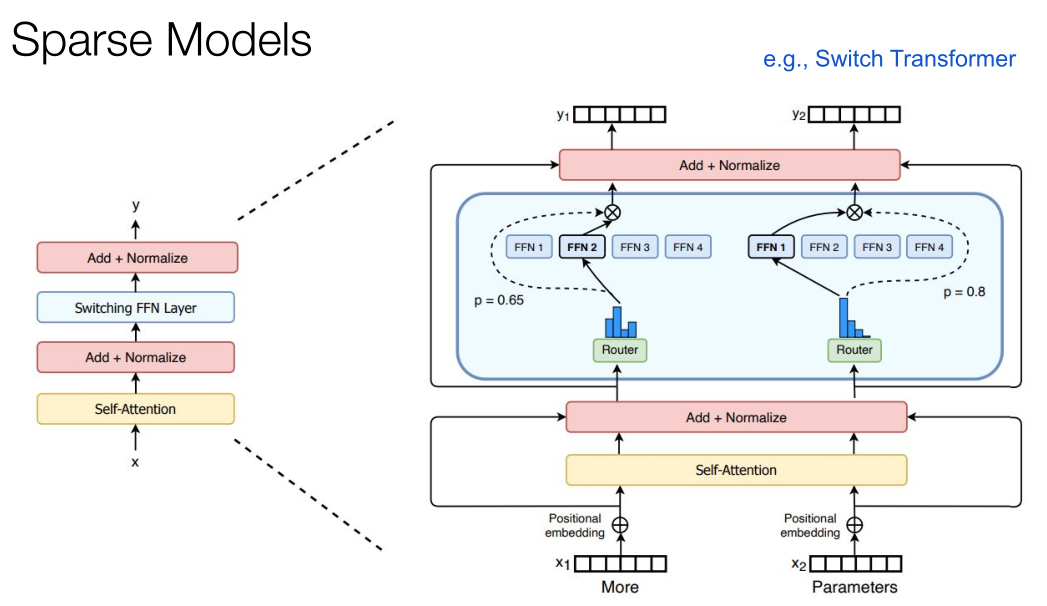
我们有很多稀疏模型可以使用,在训练中可以将每一个字都识别出来,然后当单词进入这个模型就会激活不同的FFN。对比一下人类大脑,它也没有办法随时激活每一个神经元,那么要让Transformer工作得越来越快,就需要建立更大的模型。因此我认为Transformer可以被作为服务来提供,它会变得更快,以数量级的方式增长,也可以处理很长的上下文。
上面跟大家展示了GPT2模型,只需要给它一些提示,它就能生成任务的答案。这是一个OPENAi的API,你只需要在上面写上社交网络的发言,它就能判断出你的情绪是正面的,负面的,还是中性的。如果你有这样一个API你需要去训练你的模型吗?
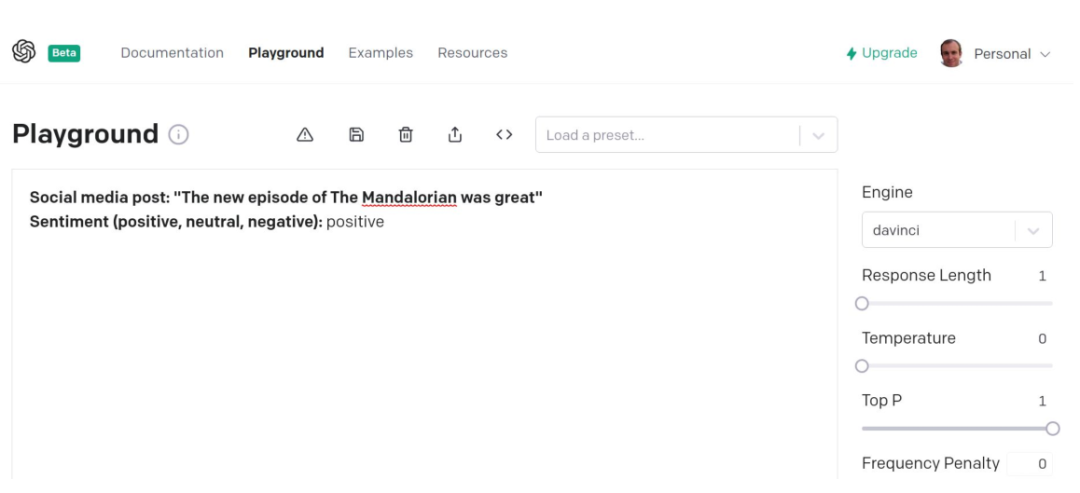
对于模型也是一样,我认为模型将来会被作为服务来提供。当然如果你是阿里、腾讯这样的大企业,你可能会训练自己的模型,但它确实是需要花费很多的时间精力和成本的。未来我觉得很快我们就能够得到,一些以服务方式提供的运行速率更快的Transformer,如果您的手里有一个快速运行的多模态Transformer能够直接使用,您会把它来做些什么呢?
以上就是我今天想跟大家分享的内容。











