
品牌名称
Boss直聘
所在行业
互联网
企业规模
1001-5000人
图数据库 Nebula Graph 在 Boss 直聘的应用
446次阅读
在 Boss 直聘的安全风控技术中,需要用到大规模图存储和挖掘计算,之前主要基于自建的高可用 Neo4j 2 集群来保障相关应用,而在实时行为分析方面,需要一个支持日增 10 亿关系的图数据库,Neo4j 无法满足应用需求。
针对这个场景,前期我们主要使用 Dgraph 12,踩过很多坑并和 Dgraph 团队连线会议,在使用 Dgraph 半年后最终还是选择了更贴合我们需求的 Nebula Graph 10。具体的对比 Benchmark 51 已经有很多团队在论坛分享了,这里就不再赘述,主要分享一些技术指标和选型,以及很多小伙伴感兴趣的 Dgraph 对比使用经验。
技术指标
硬件
配置如下:
- 处理器:Intel® Xeon® Gold 6230 CPU @ 2.10GHz 80(cores)
- 内存:DDR4,128G
- 存储:1.8T SSD
- 网络:万兆
Nebula Graph 部署 5 个节点,按官方建议 3 个 metad / 5 个 graphd / 5 个 storaged
软件
- Nebula Graph 版本:V1.1.0 3
- 操作系统:CentOS Linux release 7.3.1611 (Core)
配置
主要调整的配置和 storage 相关
# 按照文档建议,配置内存的 3 分之 1
--rocksdb_block_cache=40960
# 参数配置减小内存使用
--enable_partitioned_index_filter=true
--max_edge_returned_per_vertex=100000
指标
目前安全行为图保存 3 个月行为,近 500 亿边,10 分钟聚合写入一次,日均写入点 3,000 万,日均写入边 5.5 亿,插入延时 <=20 ms。
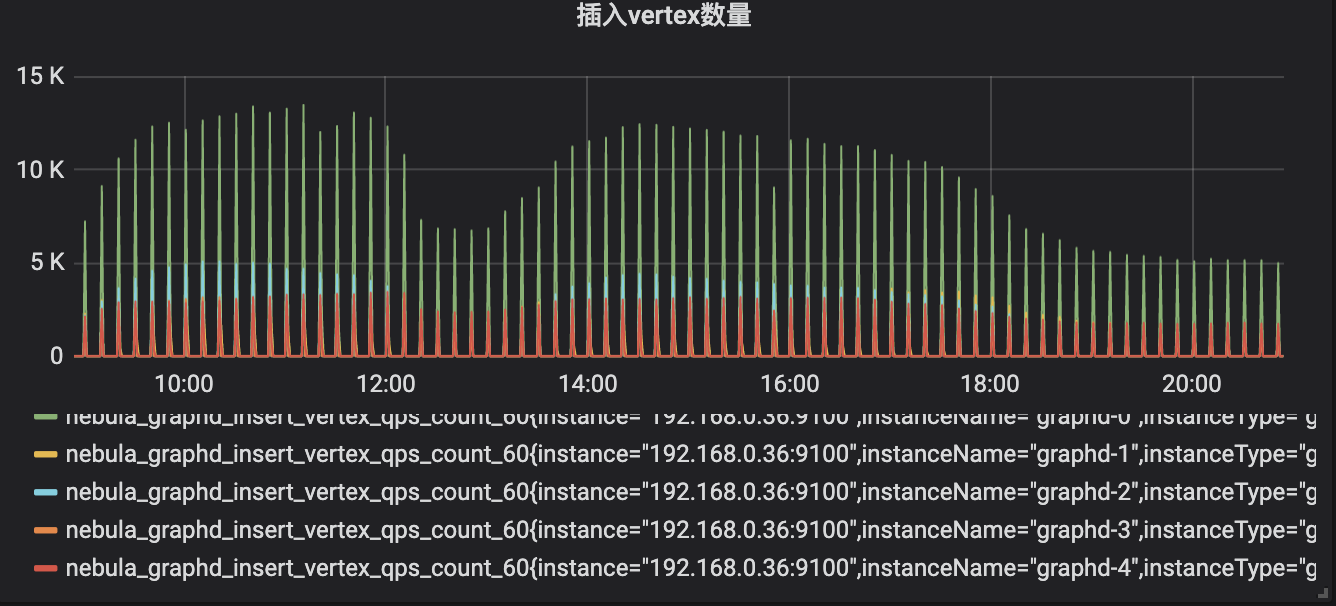
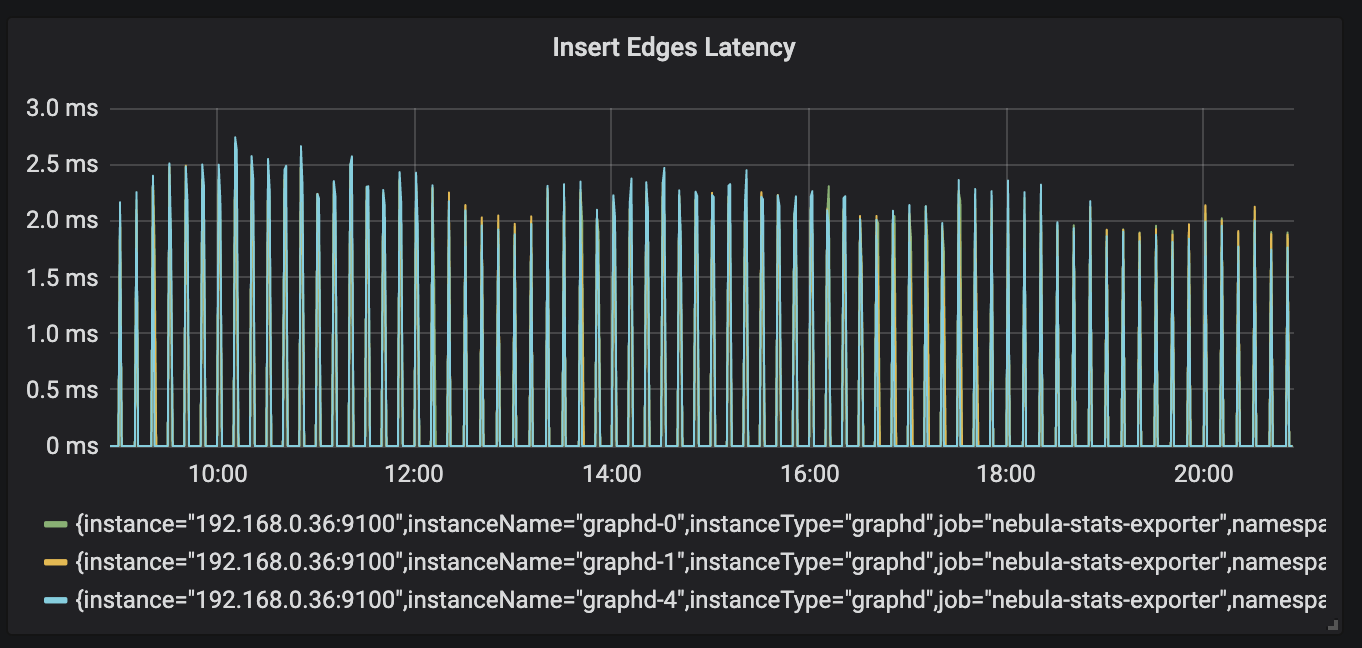

读延时 <= 100 ms,业务侧接口读延时 <= 200 ms,部分超大请求 < 1 s

当前磁盘空间占用 600G * 5 左右
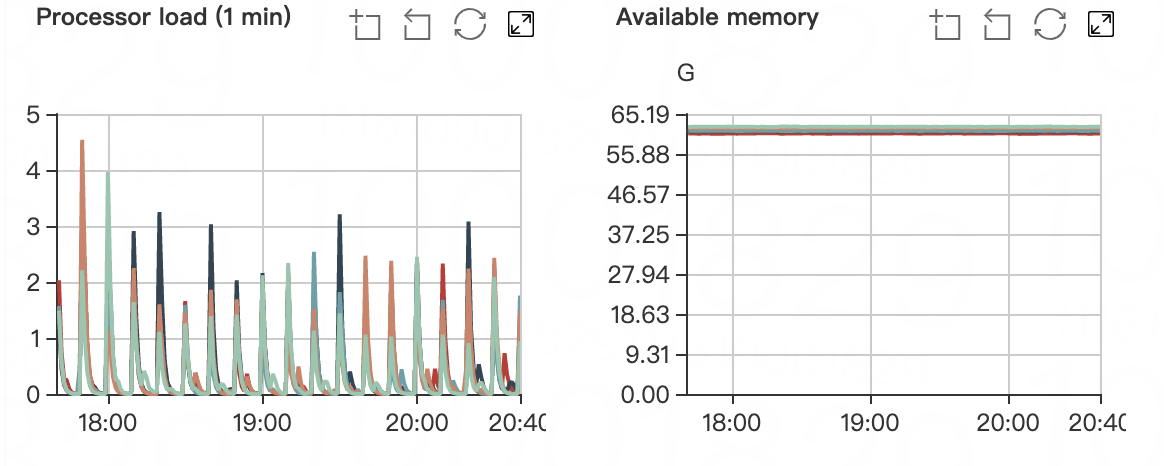
cpu 耗用 500% 左右,内存使用稳定在 60 G 左右
Dgraph使用对比
目前来说原生分布式图数据库国内选型主要比对 Dgraph和 Nebula Graph,前者我们使用半年
对比来说,Nebula Graph 很优秀,特别是工程化方面,体现在很多细节,可以看出开发团队在实际使用和实现上做较了较好的平衡:
- 1.支持手动控制数据平衡时机,自动固然很好,但是容易导致很多问题
- 2.控制内存占用(enable_partitioned_index_filter 优化和设置单次最大返回边数目),都放在内存固然快,但有时候也需要考虑数据量和性能的平衡
- 3.多图物理隔离,多张图实在太有必要
- 4.nGQL 最大程度接近最常用 MySQL 语句,2 期兼容 Cypher 更加完美;对比 GraphQL 固然香,但写起复杂图查询真的让人想爆炸,可能还是更加适合做数据中台查询语言
- 5.和图计算框架的结合,最近释放的 Spark GraphX 结合算法非常有用,原先我们的图计算都是基于 GraphX 从 Neo4j 抽取后离线计算团伙,后续打算尝试 Nebula Graph 抽取
这里主要从实际经验对比分享,二者都在持续优化,都在快速迭代,建议使用前多看看最新版本 release说明。
该产品与互联网行业合作的客户案例

中亦科技
互联网 201-500人
中亦安图 :以 NebulaGraph 为底座的智能运维解决
中亦安图 :以 NebulaGraph 为底座的智能运维解决方案
中亦安图
2022-07-18
应用实践
智能运维落地中遇到的挑战
随着 IT 基础架构

快手
互联网 5001-10000人
百亿级图数据在快手安全情报的应用与挑战
【作者介绍】
戚名钰:快手安全-移动安全组,主要负责快手安全情报平台的建设
倪雯:快手数据平台-分布式存储组,主要负责快手图数据库的建设
姚靖怡:快手数据平台

携程旅行网
互联网 51-200人
信息图谱携程酒店的应用
对于用户的每一次查询,都能根据其意图做到相应的场景和产品的匹配,是携程酒店技术团队的目标,但实现这个目标他们遇到了三大问题本文着重讲述他们是如何构建场景与信息关
查看更多

















